 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDicta-LM 3.0: Advancing The Frontier of Hebrew Sovereign LLMs
Feb 02, 2026Open-weight LLMs have been released by frontier labs; however, sovereign Large Language Models (for languages other than English) remain low in supply yet high in demand. Training large language models (LLMs) for low-resource languages such as Hebrew poses unique challenges. In this paper, we introduce Dicta-LM 3.0: an open-weight collection of LLMs trained on substantially-sized corpora of Hebrew and English texts. The model is released in three sizes: 24B - adapted from the Mistral-Small-3.1 base model, 12B - adapted from the NVIDIA Nemotron Nano V2 model, and 1.7B - adapted from the Qwen3-1.7B base model. We are releasing multiple variants of each model, each with a native context length of 65k tokens; base model and chat model with tool-calling support. To rigorously evaluate our models, we introduce a new benchmark suite for evaluation of Hebrew chat-LLMs, covering a diverse set of tasks including Translation, Summarization, Winograd, Israeli Trivia, and Diacritization (nikud). Our work not only addresses the intricacies of training LLMs in low-resource languages but also proposes a framework that can be leveraged for adapting other LLMs to various non-English languages, contributing to the broader field of multilingual NLP.
The Overlooked Role of Graded Relevance Thresholds in Multilingual Dense Retrieval
Jan 07, 2026Dense retrieval models are typically fine-tuned with contrastive learning objectives that require binary relevance judgments, even though relevance is inherently graded. We analyze how graded relevance scores and the threshold used to convert them into binary labels affect multilingual dense retrieval. Using a multilingual dataset with LLM-annotated relevance scores, we examine monolingual, multilingual mixture, and cross-lingual retrieval scenarios. Our findings show that the optimal threshold varies systematically across languages and tasks, often reflecting differences in resource level. A well-chosen threshold can improve effectiveness, reduce the amount of fine-tuning data required, and mitigate annotation noise, whereas a poorly chosen one can degrade performance. We argue that graded relevance is a valuable but underutilized signal for dense retrieval, and that threshold calibration should be treated as a principled component of the fine-tuning pipeline.
IQ Test for LLMs: An Evaluation Framework for Uncovering Core Skills in LLMs
Jul 27, 2025Current evaluations of large language models (LLMs) rely on benchmark scores, but it is difficult to interpret what these individual scores reveal about a model's overall skills. Specifically, as a community we lack understanding of how tasks relate to one another, what they measure in common, how they differ, or which ones are redundant. As a result, models are often assessed via a single score averaged across benchmarks, an approach that fails to capture the models' wholistic strengths and limitations. Here, we propose a new evaluation paradigm that uses factor analysis to identify latent skills driving performance across benchmarks. We apply this method to a comprehensive new leaderboard showcasing the performance of 60 LLMs on 44 tasks, and identify a small set of latent skills that largely explain performance. Finally, we turn these insights into practical tools that identify redundant tasks, aid in model selection, and profile models along each latent skill.
Measuring the Effect of Transcription Noise on Downstream Language Understanding Tasks
Feb 19, 2025With the increasing prevalence of recorded human speech, spoken language understanding (SLU) is essential for its efficient processing. In order to process the speech, it is commonly transcribed using automatic speech recognition technology. This speech-to-text transition introduces errors into the transcripts, which subsequently propagate to downstream NLP tasks, such as dialogue summarization. While it is known that transcript noise affects downstream tasks, a systematic approach to analyzing its effects across different noise severities and types has not been addressed. We propose a configurable framework for assessing task models in diverse noisy settings, and for examining the impact of transcript-cleaning techniques. The framework facilitates the investigation of task model behavior, which can in turn support the development of effective SLU solutions. We exemplify the utility of our framework on three SLU tasks and four task models, offering insights regarding the effect of transcript noise on tasks in general and models in particular. For instance, we find that task models can tolerate a certain level of noise, and are affected differently by the types of errors in the transcript.
Diversity Over Quantity: A Lesson From Few Shot Relation Classification
Dec 06, 2024In few-shot relation classification (FSRC), models must generalize to novel relations with only a few labeled examples. While much of the recent progress in NLP has focused on scaling data size, we argue that diversity in relation types is more crucial for FSRC performance. In this work, we demonstrate that training on a diverse set of relations significantly enhances a model's ability to generalize to unseen relations, even when the overall dataset size remains fixed. We introduce REBEL-FS, a new FSRC benchmark that incorporates an order of magnitude more relation types than existing datasets. Through systematic experiments, we show that increasing the diversity of relation types in the training data leads to consistent gains in performance across various few-shot learning scenarios, including high-negative settings. Our findings challenge the common assumption that more data alone leads to better performance and suggest that targeted data curation focused on diversity can substantially reduce the need for large-scale datasets in FSRC.
Adapting LLMs to Hebrew: Unveiling DictaLM 2.0 with Enhanced Vocabulary and Instruction Capabilities
Jul 09, 2024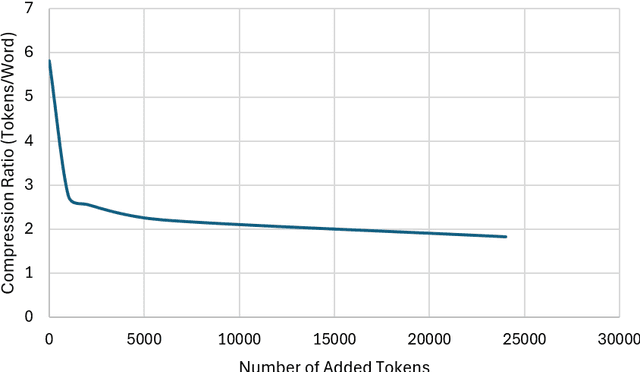
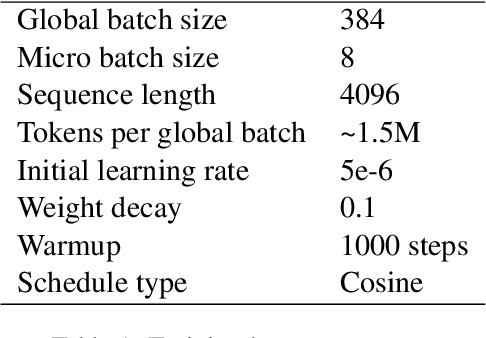
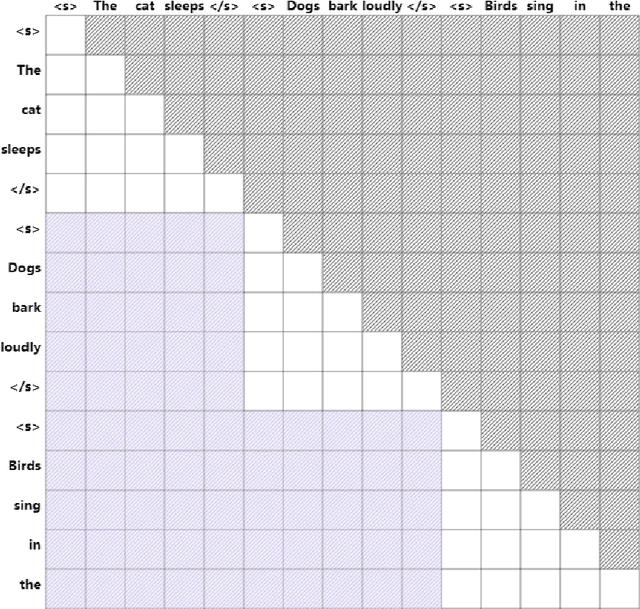
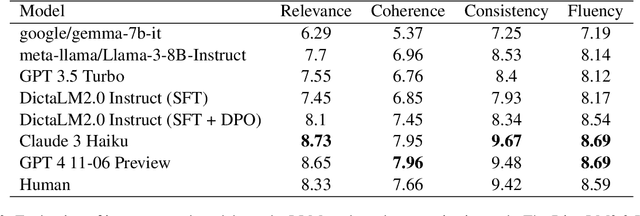
Training large language models (LLMs) in low-resource languages such as Hebrew poses unique challenges. In this paper, we introduce DictaLM2.0 and DictaLM2.0-Instruct, two LLMs derived from the Mistral model, trained on a substantial corpus of approximately 200 billion tokens in both Hebrew and English. Adapting a pre-trained model to a new language involves specialized techniques that differ significantly from training a model from scratch or further training existing models on well-resourced languages such as English. We outline these novel training methodologies, which facilitate effective learning and adaptation to the linguistic properties of Hebrew. Additionally, we fine-tuned DictaLM2.0-Instruct on a comprehensive instruct dataset to enhance its performance on task-specific instructions. To rigorously evaluate our models, we introduce a new benchmark suite for Hebrew LLM evaluation, covering a diverse set of tasks including Question Answering, Sentiment Analysis, Winograd Schema Challenge, Translation, and Summarization. Our work not only addresses the intricacies of training LLMs in low-resource languages but also proposes a framework that can be leveraged for adapting other LLMs to various non-English languages, contributing to the broader field of multilingual NLP.
NERetrieve: Dataset for Next Generation Named Entity Recognition and Retrieval
Oct 22, 2023Recognizing entities in texts is a central need in many information-seeking scenarios, and indeed, Named Entity Recognition (NER) is arguably one of the most successful examples of a widely adopted NLP task and corresponding NLP technology. Recent advances in large language models (LLMs) appear to provide effective solutions (also) for NER tasks that were traditionally handled with dedicated models, often matching or surpassing the abilities of the dedicated models. Should NER be considered a solved problem? We argue to the contrary: the capabilities provided by LLMs are not the end of NER research, but rather an exciting beginning. They allow taking NER to the next level, tackling increasingly more useful, and increasingly more challenging, variants. We present three variants of the NER task, together with a dataset to support them. The first is a move towards more fine-grained -- and intersectional -- entity types. The second is a move towards zero-shot recognition and extraction of these fine-grained types based on entity-type labels. The third, and most challenging, is the move from the recognition setup to a novel retrieval setup, where the query is a zero-shot entity type, and the expected result is all the sentences from a large, pre-indexed corpus that contain entities of these types, and their corresponding spans. We show that all of these are far from being solved. We provide a large, silver-annotated corpus of 4 million paragraphs covering 500 entity types, to facilitate research towards all of these three goals.
Retrieving Texts based on Abstract Descriptions
May 21, 2023



In this work, we aim to connect two research areas: instruction models and retrieval-based models. While instruction-tuned Large Language Models (LLMs) excel at extracting information from text, they are not suitable for semantic retrieval. Similarity search over embedding vectors allows to index and query vectors, but the similarity reflected in the embedding is sub-optimal for many use cases. We identify the task of retrieving sentences based on abstract descriptions of their content. We demonstrate the inadequacy of current text embeddings and propose an alternative model that significantly improves when used in standard nearest neighbor search. The model is trained using positive and negative pairs sourced through prompting an a large language model (LLM). While it is easy to source the training material from an LLM, the retrieval task cannot be performed by the LLM directly. This demonstrates that data from LLMs can be used not only for distilling more efficient specialized models than the original LLM, but also for creating new capabilities not immediately possible using the original model.
Relation Extraction as Two-way Span-Prediction
Oct 09, 2020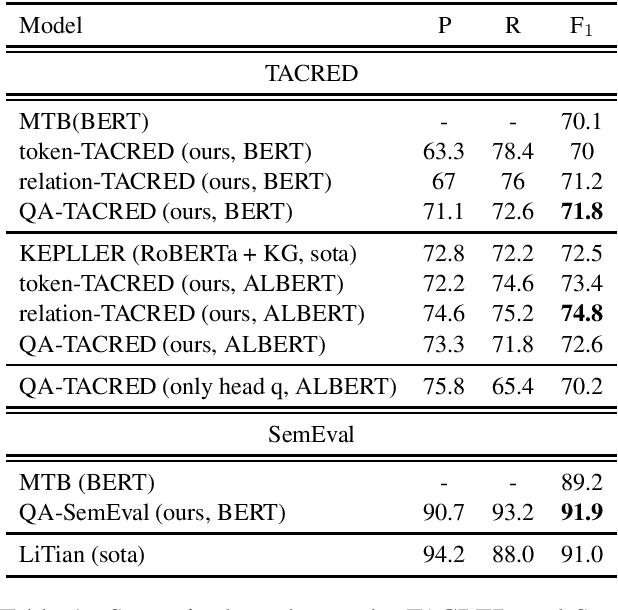
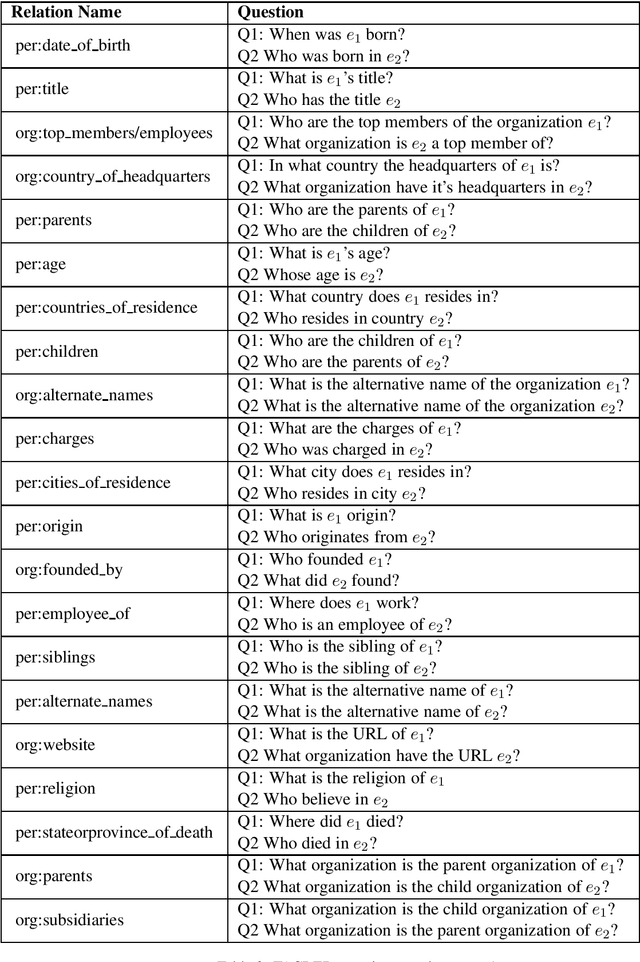

The current supervised relation classification (RC) task uses a single embedding to represent the relation between a pair of entities. We argue that a better approach is to treat the RC task as a Question answering (QA) like span prediction problem. We present a span-prediction based system for RC and evaluate its performance compared to the embedding based system. We achieve state-of-the-art results on the TACRED and SemEval task 8 datasets.