 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral or spatial? Leveraging both for speaker extraction in challenging data conditions
Dec 23, 2025This paper presents a robust multi-channel speaker extraction algorithm designed to handle inaccuracies in reference information. While existing approaches often rely solely on either spatial or spectral cues to identify the target speaker, our method integrates both sources of information to enhance robustness. A key aspect of our approach is its emphasis on stability, ensuring reliable performance even when one of the features is degraded or misleading. Given a noisy mixture and two potentially unreliable cues, a dedicated network is trained to dynamically balance their contributions-or disregard the less informative one when necessary. We evaluate the system under challenging conditions by simulating inference-time errors using a simple direction of arrival (DOA) estimator and a noisy spectral enrollment process. Experimental results demonstrate that the proposed model successfully extracts the desired speaker even in the presence of substantial reference inaccuracies.
Measuring the Effect of Transcription Noise on Downstream Language Understanding Tasks
Feb 19, 2025With the increasing prevalence of recorded human speech, spoken language understanding (SLU) is essential for its efficient processing. In order to process the speech, it is commonly transcribed using automatic speech recognition technology. This speech-to-text transition introduces errors into the transcripts, which subsequently propagate to downstream NLP tasks, such as dialogue summarization. While it is known that transcript noise affects downstream tasks, a systematic approach to analyzing its effects across different noise severities and types has not been addressed. We propose a configurable framework for assessing task models in diverse noisy settings, and for examining the impact of transcript-cleaning techniques. The framework facilitates the investigation of task model behavior, which can in turn support the development of effective SLU solutions. We exemplify the utility of our framework on three SLU tasks and four task models, offering insights regarding the effect of transcript noise on tasks in general and models in particular. For instance, we find that task models can tolerate a certain level of noise, and are affected differently by the types of errors in the transcript.
End-to-End Multi-Microphone Speaker Extraction Using Relative Transfer Functions
Feb 10, 2025This paper introduces a multi-microphone method for extracting a desired speaker from a mixture involving multiple speakers and directional noise in a reverberant environment. In this work, we propose leveraging the instantaneous relative transfer function (RTF), estimated from a reference utterance recorded in the same position as the desired source. The effectiveness of the RTF-based spatial cue is compared with direction of arrival (DOA)-based spatial cue and the conventional spectral embedding. Experimental results in challenging acoustic scenarios demonstrate that using spatial cues yields better performance than the spectral-based cue and that the instantaneous RTF outperforms the DOA-based spatial cue.
Optimized Tokenization for Transcribed Error Correction
Oct 16, 2023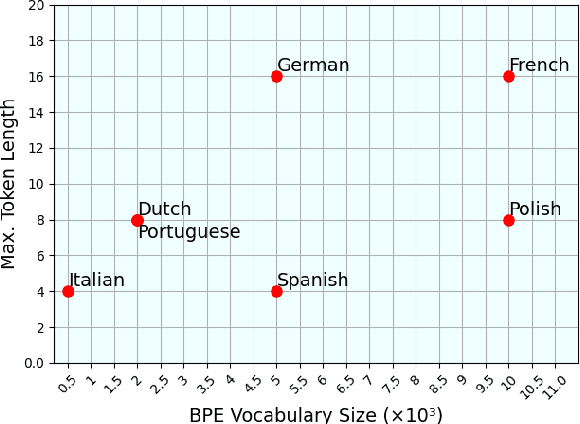
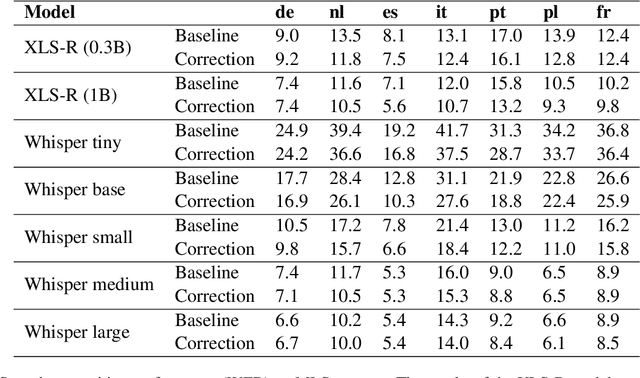
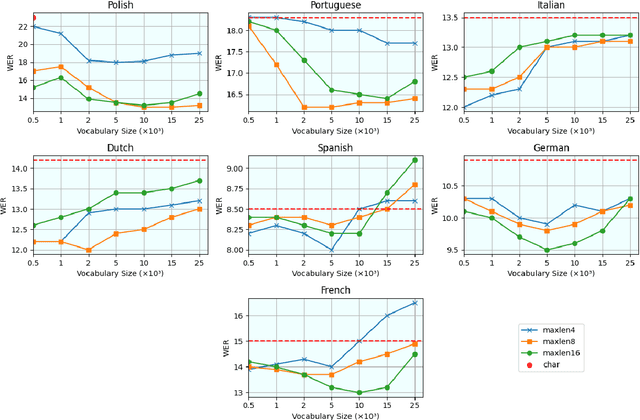
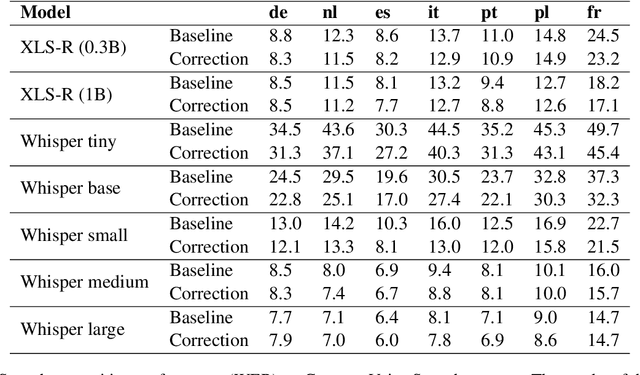
The challenges facing speech recognition systems, such as variations in pronunciations, adverse audio conditions, and the scarcity of labeled data, emphasize the necessity for a post-processing step that corrects recurring errors. Previous research has shown the advantages of employing dedicated error correction models, yet training such models requires large amounts of labeled data which is not easily obtained. To overcome this limitation, synthetic transcribed-like data is often utilized, however, bridging the distribution gap between transcribed errors and synthetic noise is not trivial. In this paper, we demonstrate that the performance of correction models can be significantly increased by training solely using synthetic data. Specifically, we empirically show that: (1) synthetic data generated using the error distribution derived from a set of transcribed data outperforms the common approach of applying random perturbations; (2) applying language-specific adjustments to the vocabulary of a BPE tokenizer strike a balance between adapting to unseen distributions and retaining knowledge of transcribed errors. We showcase the benefits of these key observations, and evaluate our approach using multiple languages, speech recognition systems and prominent speech recognition datasets.
A two-stage speaker extraction algorithm under adverse acoustic conditions using a single-microphone
Mar 13, 2023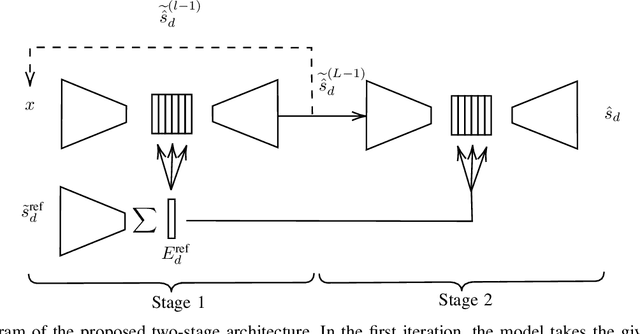

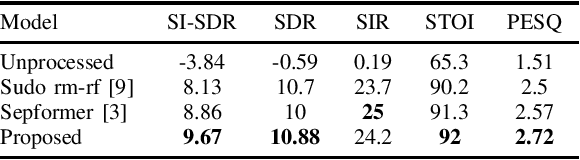
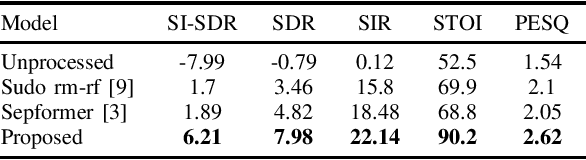
In this work, we present a two-stage method for speaker extraction under reverberant and noisy conditions. Given a reference signal of the desired speaker, the clean, but the still reverberant, desired speaker is first extracted from the noisy-mixed signal. In the second stage, the extracted signal is further enhanced by joint dereverberation and residual noise and interference reduction. The proposed architecture comprises two sub-networks, one for the extraction task and the second for the dereverberation task. We present a training strategy for this architecture and show that the performance of the proposed method is on par with other state-of-the-art (SOTA) methods when applied to the WHAMR! dataset. Furthermore, we present a new dataset with more realistic adverse acoustic conditions and show that our method outperforms the competing methods when applied to this dataset as well.
Don't Be So Sure! Boosting ASR Decoding via Confidence Relaxation
Dec 27, 2022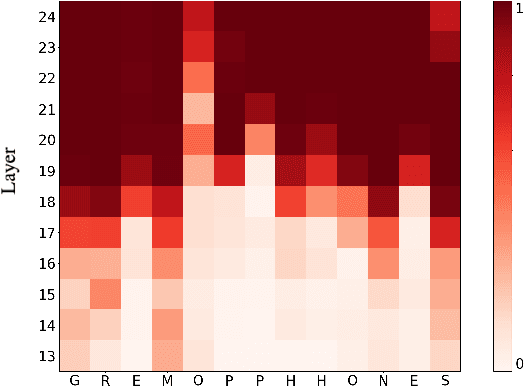

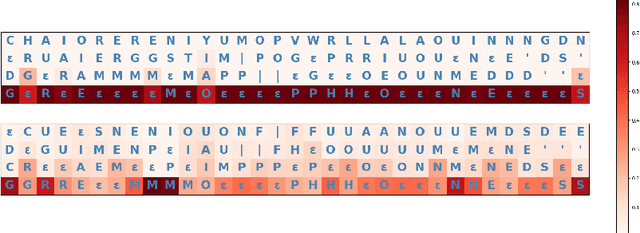
Automatic Speech Recognition (ASR) systems frequently use a search-based decoding strategy aiming to find the best attainable transcript by considering multiple candidates. One prominent speech recognition decoding heuristic is beam search, which seeks the transcript with the greatest likelihood computed using the predicted distribution. While showing substantial performance gains in various tasks, beam search loses some of its effectiveness when the predicted probabilities are highly confident, i.e., the predicted distribution is massed for a single or very few classes. We show that recently proposed Self-Supervised Learning (SSL)-based ASR models tend to yield exceptionally confident predictions that may hamper beam search from truly considering a diverse set of candidates. We perform a layer analysis to reveal and visualize how predictions evolve, and propose a decoding procedure that improves the performance of fine-tuned ASR models. Our proposed approach does not require further training beyond the original fine-tuning, nor additional model parameters. In fact, we find that our proposed method requires significantly less inference computation than current approaches. We propose aggregating the top M layers, potentially leveraging useful information encoded in intermediate layers, and relaxing model confidence. We demonstrate the effectiveness of our approach by conducting an empirical study on varying amounts of labeled resources and different model sizes, showing consistent improvements in particular when applied to low-resource scenarios.
Magnitude or Phase? A Two Stage Algorithm for Dereverberation
Oct 31, 2022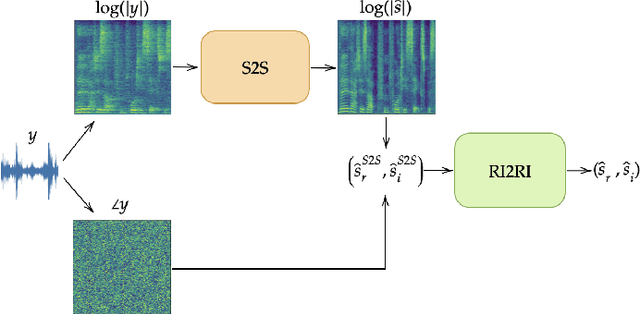



In this work we present a new single-microphone speech dereverberation algorithm. First, a performance analysis is presented to interpret that algorithms focused on improving solely magnitude or phase are not good enough. Furthermore, we demonstrate that few objective measurements have high correlation with the clean magnitude while others with the clean phase. Consequently ,we propose a new architecture which consists of two sub-models, each of which is responsible for a different task. The first model estimates the clean magnitude given the noisy input. The enhanced magnitude together with the noisy-input phase are then used as inputs to the second model to estimate the real and imaginary portions of the dereverberated signal. A training scheme including pre-training and fine-tuning is presented in the paper. We evaluate our proposed approach using data from the REVERB challenge and compare our results to other methods. We demonstrate consistent improvements in all measures, which can be attributed to the improved estimates of both the magnitude and the phase.
Enhancing Speech Recognition Decoding via Layer Aggregation
Apr 05, 2022
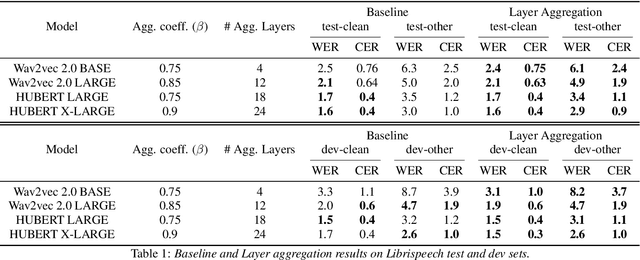
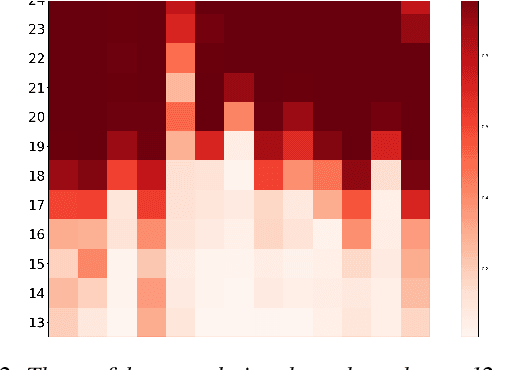
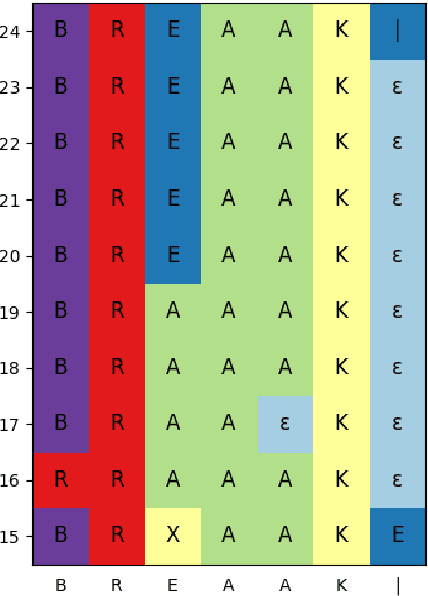
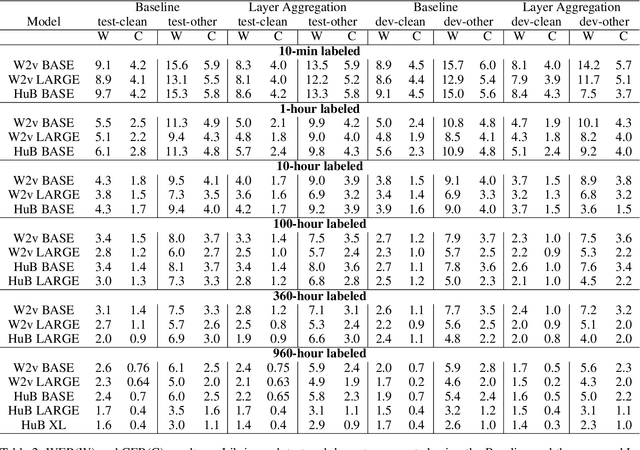
Recently proposed speech recognition systems are designed to predict using representations generated by their top layers, employing greedy decoding which isolates each timestep from the rest of the sequence. Aiming for improved performance, a beam search algorithm is frequently utilized and a language model is incorporated to assist with ranking the top candidates. In this work, we experiment with several speech recognition models and find that logits predicted using the top layers may hamper beam search from achieving optimal results. Specifically, we show that fined-tuned Wav2Vec 2.0 and HuBERT yield highly confident predictions, and hypothesize that the predictions are based on local information and may not take full advantage of the information encoded in intermediate layers. To this end, we perform a layer analysis to reveal and visualize how predictions evolve throughout the inference flow. We then propose a prediction method that aggregates the top M layers, potentially leveraging useful information encoded in intermediate layers and relaxing model confidence. We showcase the effectiveness of our approach via beam search decoding, conducting our experiments on Librispeech test and dev sets and achieving WER, and CER reduction of up to 10% and 22%, respectively.
CNN self-attention voice activity detector
Mar 06, 2022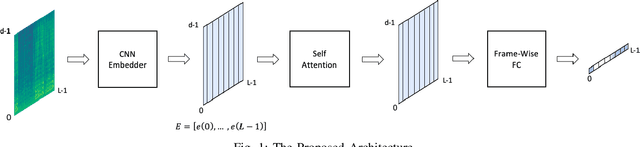


In this work we present a novel single-channel Voice Activity Detector (VAD) approach. We utilize a Convolutional Neural Network (CNN) which exploits the spatial information of the noisy input spectrum to extract frame-wise embedding sequence, followed by a Self Attention (SA) Encoder with a goal of finding contextual information from the embedding sequence. Different from previous works which were employed on each frame (with context frames) separately, our method is capable of processing the entire signal at once, and thus enabling long receptive field. We show that the fusion of CNN and SA architectures outperforms methods based solely on CNN and SA. Extensive experimental-study shows that our model outperforms previous models on real-life benchmarks, and provides State Of The Art (SOTA) results with relatively small and lightweight model.
Single microphone speaker extraction using unified time-frequency Siamese-Unet
Mar 06, 2022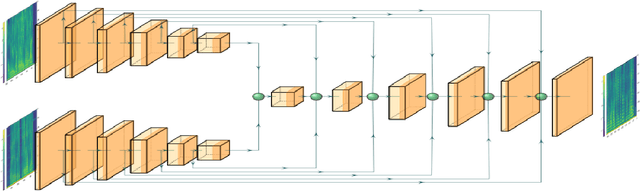
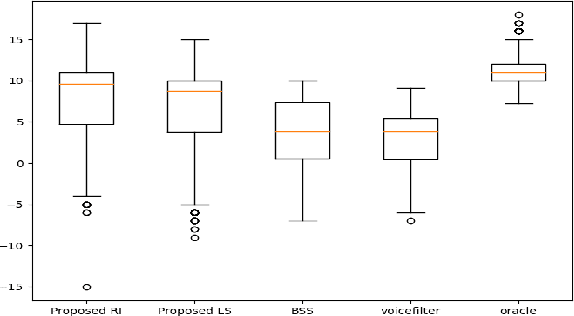
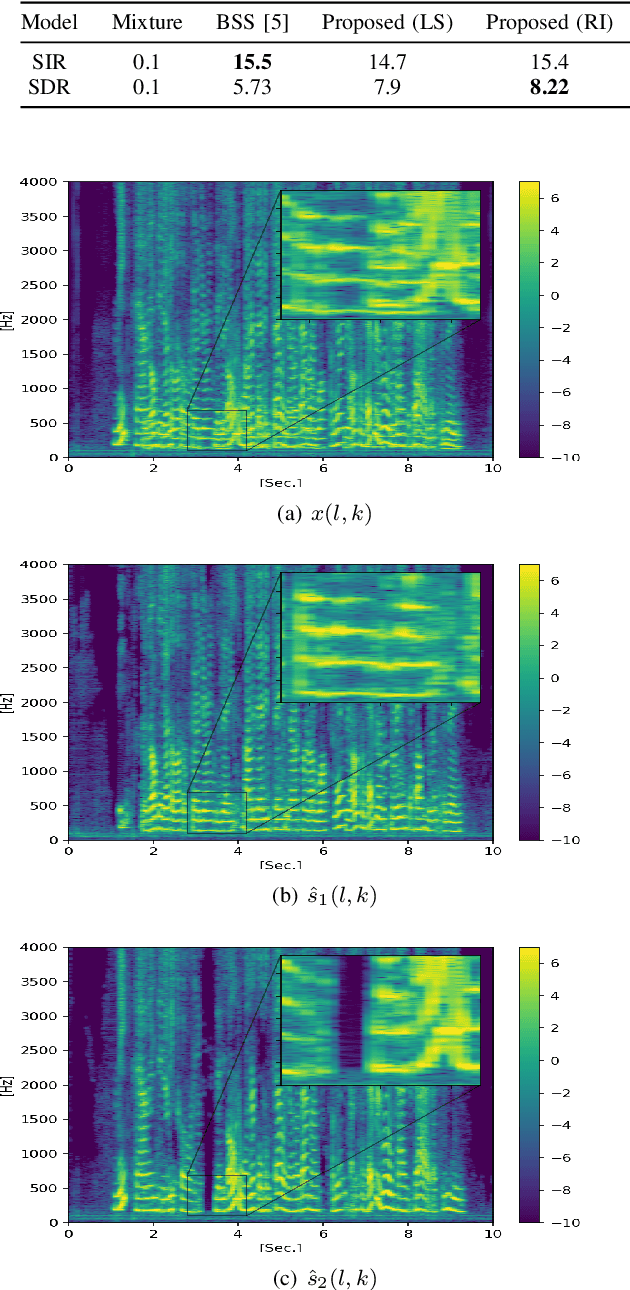

In this paper we present a unified time-frequency method for speaker extraction in clean and noisy conditions. Given a mixed signal, along with a reference signal, the common approaches for extracting the desired speaker are either applied in the time-domain or in the frequency-domain. In our approach, we propose a Siamese-Unet architecture that uses both representations. The Siamese encoders are applied in the frequency-domain to infer the embedding of the noisy and reference spectra, respectively. The concatenated representations are then fed into the decoder to estimate the real and imaginary components of the desired speaker, which are then inverse-transformed to the time-domain. The model is trained with the Scale-Invariant Signal-to-Distortion Ratio (SI-SDR) loss to exploit the time-domain information. The time-domain loss is also regularized with frequency-domain loss to preserve the speech patterns. Experimental results demonstrate that the unified approach is not only very easy to train, but also provides superior results as compared with state-of-the-art (SOTA) Blind Source Separation (BSS) methods, as well as commonly used speaker extraction approach.