 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepeerRTF: Robust MVDR Beamforming Using Graph Convolutional Network
Jul 01, 2024



Accurate and reliable identification of the RTF between microphones with respect to a desired source is an essential component in the design of microphone array beamformers, specifically the MVDR criterion. Since an accurate estimation of the RTF in a noisy and reverberant environment is a cumbersome task, we aim at leveraging prior knowledge of the acoustic enclosure to robustify the RTF estimation by learning the RTF manifold. In this paper, we present a novel robust RTF identification method, tested and trained with real recordings, which relies on learning the RTF manifold using a GCN to infer a robust representation of the RTF in a confined area, and consequently enhance the beamformer's performance.
CNN self-attention voice activity detector
Mar 06, 2022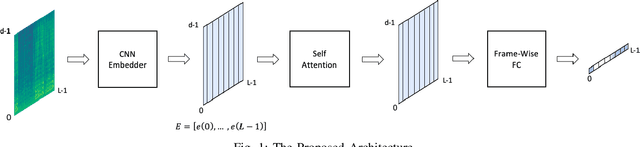


In this work we present a novel single-channel Voice Activity Detector (VAD) approach. We utilize a Convolutional Neural Network (CNN) which exploits the spatial information of the noisy input spectrum to extract frame-wise embedding sequence, followed by a Self Attention (SA) Encoder with a goal of finding contextual information from the embedding sequence. Different from previous works which were employed on each frame (with context frames) separately, our method is capable of processing the entire signal at once, and thus enabling long receptive field. We show that the fusion of CNN and SA architectures outperforms methods based solely on CNN and SA. Extensive experimental-study shows that our model outperforms previous models on real-life benchmarks, and provides State Of The Art (SOTA) results with relatively small and lightweight model.