 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepeerRTF: Robust MVDR Beamforming Using Graph Convolutional Network
Jul 01, 2024



Accurate and reliable identification of the RTF between microphones with respect to a desired source is an essential component in the design of microphone array beamformers, specifically the MVDR criterion. Since an accurate estimation of the RTF in a noisy and reverberant environment is a cumbersome task, we aim at leveraging prior knowledge of the acoustic enclosure to robustify the RTF estimation by learning the RTF manifold. In this paper, we present a novel robust RTF identification method, tested and trained with real recordings, which relies on learning the RTF manifold using a GCN to infer a robust representation of the RTF in a confined area, and consequently enhance the beamformer's performance.
RevRIR: Joint Reverberant Speech and Room Impulse Response Embedding using Contrastive Learning with Application to Room Shape Classification
Jun 05, 2024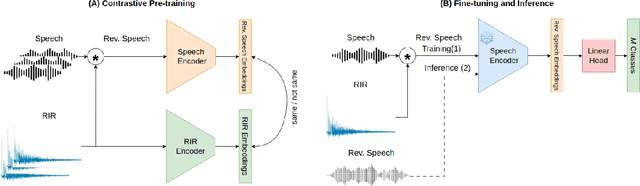


This paper focuses on room fingerprinting, a task involving the analysis of an audio recording to determine the specific volume and shape of the room in which it was captured. While it is relatively straightforward to determine the basic room parameters from the Room Impulse Responses (RIR), doing so from a speech signal is a cumbersome task. To address this challenge, we introduce a dual-encoder architecture that facilitates the estimation of room parameters directly from speech utterances. During pre-training, one encoder receives the RIR while the other processes the reverberant speech signal. A contrastive loss function is employed to embed the speech and the acoustic response jointly. In the fine-tuning stage, the specific classification task is trained. In the test phase, only the reverberant utterance is available, and its embedding is used for the task of room shape classification. The proposed scheme is extensively evaluated using simulated acoustic environments.