 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevRIR: Joint Reverberant Speech and Room Impulse Response Embedding using Contrastive Learning with Application to Room Shape Classification
Jun 05, 2024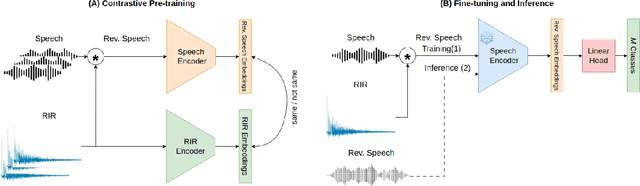


This paper focuses on room fingerprinting, a task involving the analysis of an audio recording to determine the specific volume and shape of the room in which it was captured. While it is relatively straightforward to determine the basic room parameters from the Room Impulse Responses (RIR), doing so from a speech signal is a cumbersome task. To address this challenge, we introduce a dual-encoder architecture that facilitates the estimation of room parameters directly from speech utterances. During pre-training, one encoder receives the RIR while the other processes the reverberant speech signal. A contrastive loss function is employed to embed the speech and the acoustic response jointly. In the fine-tuning stage, the specific classification task is trained. In the test phase, only the reverberant utterance is available, and its embedding is used for the task of room shape classification. The proposed scheme is extensively evaluated using simulated acoustic environments.
Align With Purpose: Optimize Desired Properties in CTC Models with a General Plug-and-Play Framework
Jul 06, 2023



Connectionist Temporal Classification (CTC) is a widely used criterion for training supervised sequence-to-sequence (seq2seq) models. It enables learning the relations between input and output sequences, termed alignments, by marginalizing over perfect alignments (that yield the ground truth), at the expense of imperfect alignments. This binary differentiation of perfect and imperfect alignments falls short of capturing other essential alignment properties that hold significance in other real-world applications. Here we propose $\textit{Align With Purpose}$, a $\textbf{general Plug-and-Play framework}$ for enhancing a desired property in models trained with the CTC criterion. We do that by complementing the CTC with an additional loss term that prioritizes alignments according to a desired property. Our method does not require any intervention in the CTC loss function, enables easy optimization of a variety of properties, and allows differentiation between both perfect and imperfect alignments. We apply our framework in the domain of Automatic Speech Recognition (ASR) and show its generality in terms of property selection, architectural choice, and scale of training dataset (up to 280,000 hours). To demonstrate the effectiveness of our framework, we apply it to two unrelated properties: emission time and word error rate (WER). For the former, we report an improvement of up to 570ms in latency optimization with a minor reduction in WER, and for the latter, we report a relative improvement of 4.5% WER over the baseline models. To the best of our knowledge, these applications have never been demonstrated to work on a scale of data as large as ours. Notably, our method can be implemented using only a few lines of code, and can be extended to other alignment-free loss functions and to domains other than ASR.
Learning a Metric Embedding for Face Recognition using the Multibatch Method
May 24, 2016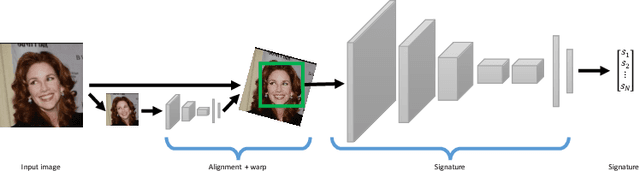

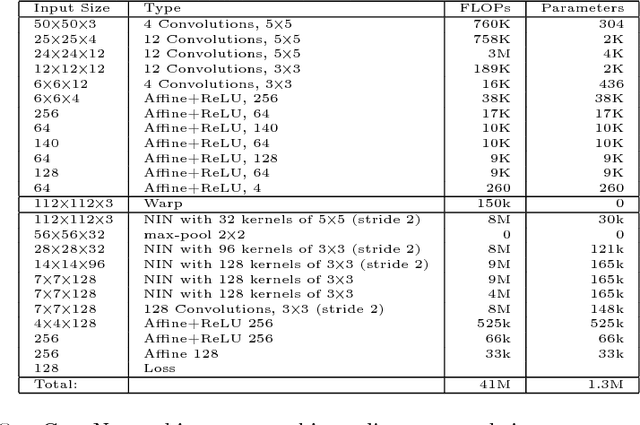

This work is motivated by the engineering task of achieving a near state-of-the-art face recognition on a minimal computing budget running on an embedded system. Our main technical contribution centers around a novel training method, called Multibatch, for similarity learning, i.e., for the task of generating an invariant "face signature" through training pairs of "same" and "not-same" face images. The Multibatch method first generates signatures for a mini-batch of $k$ face images and then constructs an unbiased estimate of the full gradient by relying on all $k^2-k$ pairs from the mini-batch. We prove that the variance of the Multibatch estimator is bounded by $O(1/k^2)$, under some mild conditions. In contrast, the standard gradient estimator that relies on random $k/2$ pairs has a variance of order $1/k$. The smaller variance of the Multibatch estimator significantly speeds up the convergence rate of stochastic gradient descent. Using the Multibatch method we train a deep convolutional neural network that achieves an accuracy of $98.2\%$ on the LFW benchmark, while its prediction runtime takes only $30$msec on a single ARM Cortex A9 core. Furthermore, the entire training process took only 12 hours on a single Titan X GPU.