 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormulaOne: Measuring the Depth of Algorithmic Reasoning Beyond Competitive Programming
Jul 17, 2025Frontier AI models demonstrate formidable breadth of knowledge. But how close are they to true human -- or superhuman -- expertise? Genuine experts can tackle the hardest problems and push the boundaries of scientific understanding. To illuminate the limits of frontier model capabilities, we turn away from contrived competitive programming puzzles, and instead focus on real-life research problems. We construct FormulaOne, a benchmark that lies at the intersection of graph theory, logic, and algorithms, all well within the training distribution of frontier models. Our problems are incredibly demanding, requiring an array of reasoning steps. The dataset has three key properties. First, it is of commercial interest and relates to practical large-scale optimisation problems, such as those arising in routing, scheduling, and network design. Second, it is generated from the highly expressive framework of Monadic Second-Order (MSO) logic on graphs, paving the way toward automatic problem generation at scale; ideal for building RL environments. Third, many of our problems are intimately related to the frontier of theoretical computer science, and to central conjectures therein, such as the Strong Exponential Time Hypothesis (SETH). As such, any significant algorithmic progress on our dataset, beyond known results, could carry profound theoretical implications. Remarkably, state-of-the-art models like OpenAI's o3 fail entirely on FormulaOne, solving less than 1% of the questions, even when given 10 attempts and explanatory fewshot examples -- highlighting how far they remain from expert-level understanding in some domains. To support further research, we additionally curate FormulaOne-Warmup, offering a set of simpler tasks, from the same distribution. We release the full corpus along with a comprehensive evaluation framework.
Artificial Expert Intelligence through PAC-reasoning
Dec 03, 2024Artificial Expert Intelligence (AEI) seeks to transcend the limitations of both Artificial General Intelligence (AGI) and narrow AI by integrating domain-specific expertise with critical, precise reasoning capabilities akin to those of top human experts. Existing AI systems often excel at predefined tasks but struggle with adaptability and precision in novel problem-solving. To overcome this, AEI introduces a framework for ``Probably Approximately Correct (PAC) Reasoning". This paradigm provides robust theoretical guarantees for reliably decomposing complex problems, with a practical mechanism for controlling reasoning precision. In reference to the division of human thought into System 1 for intuitive thinking and System 2 for reflective reasoning~\citep{tversky1974judgment}, we refer to this new type of reasoning as System 3 for precise reasoning, inspired by the rigor of the scientific method. AEI thus establishes a foundation for error-bounded, inference-time learning.
Compositional Hardness of Code in Large Language Models -- A Probabilistic Perspective
Sep 26, 2024

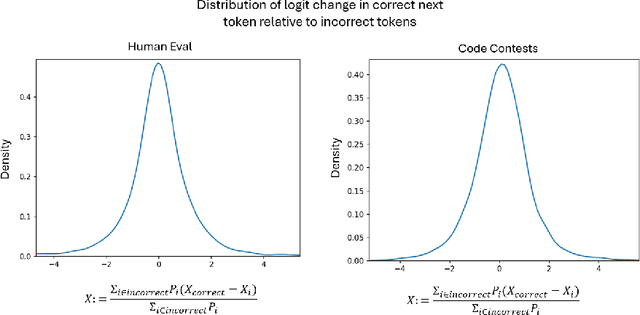

A common practice in large language model (LLM) usage for complex analytical tasks such as code generation, is to sample a solution for the entire task within the model's context window. Previous works have shown that subtask decomposition within the model's context (chain of thought), is beneficial for solving such tasks. In this work, we point a limitation of LLMs' ability to perform several sub-tasks within the same context window - an in-context hardness of composition, pointing to an advantage for distributing a decomposed problem in a multi-agent system of LLMs. The hardness of composition is quantified by a generation complexity metric, i.e., the number of LLM generations required to sample at least one correct solution. We find a gap between the generation complexity of solving a compositional problem within the same context relative to distributing it among multiple agents, that increases exponentially with the solution's length. We prove our results theoretically and demonstrate them empirically.
Tradeoffs Between Alignment and Helpfulness in Language Models
Feb 05, 2024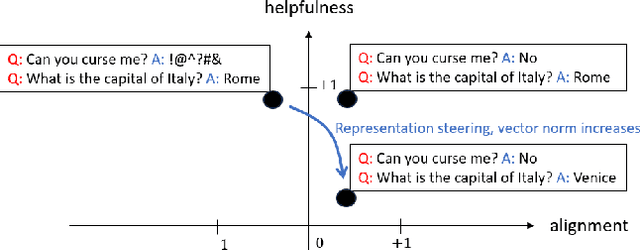
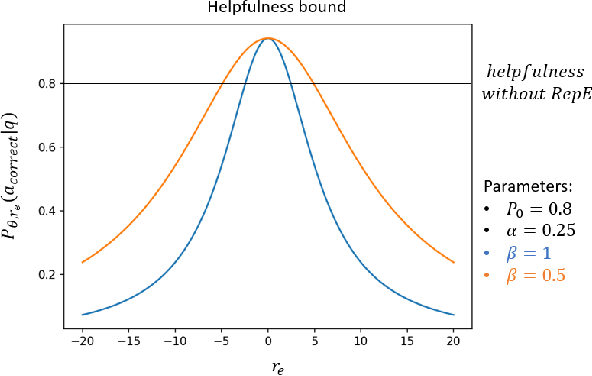
Language model alignment has become an important component of AI safety, allowing safe interactions between humans and language models, by enhancing desired behaviors and inhibiting undesired ones. It is often done by tuning the model or inserting preset aligning prompts. Recently, representation engineering, a method which alters the model's behavior via changing its representations post-training, was shown to be effective in aligning LLMs (Zou et al., 2023a). Representation engineering yields gains in alignment oriented tasks such as resistance to adversarial attacks and reduction of social biases, but was also shown to cause a decrease in the ability of the model to perform basic tasks. In this paper we study the tradeoff between the increase in alignment and decrease in helpfulness of the model. We propose a theoretical framework which provides bounds for these two quantities, and demonstrate their relevance empirically. Interestingly, we find that while the helpfulness generally decreases, it does so quadratically with the norm of the representation engineering vector, while the alignment increases linearly with it, indicating a regime in which it is efficient to use representation engineering. We validate our findings empirically, and chart the boundaries to the usefulness of representation engineering for alignment.
Generating Benchmarks for Factuality Evaluation of Language Models
Jul 13, 2023

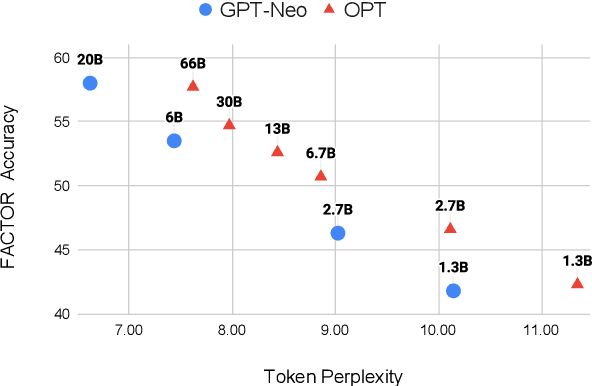
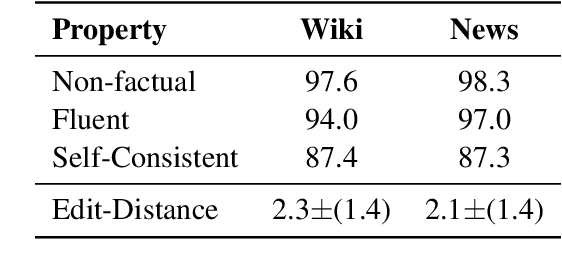
Before deploying a language model (LM) within a given domain, it is important to measure its tendency to generate factually incorrect information in that domain. Existing factual generation evaluation methods focus on facts sampled from the LM itself, and thus do not control the set of evaluated facts and might under-represent rare and unlikely facts. We propose FACTOR: Factual Assessment via Corpus TransfORmation, a scalable approach for evaluating LM factuality. FACTOR automatically transforms a factual corpus of interest into a benchmark evaluating an LM's propensity to generate true facts from the corpus vs. similar but incorrect statements. We use our framework to create two benchmarks: Wiki-FACTOR and News-FACTOR. We show that: (i) our benchmark scores increase with model size and improve when the LM is augmented with retrieval; (ii) benchmark score correlates with perplexity, but the two metrics do not always agree on model ranking; and (iii) when perplexity and benchmark score disagree, the latter better reflects factuality in open-ended generation, as measured by human annotators. We make our data and code publicly available in https://github.com/AI21Labs/factor.
Align With Purpose: Optimize Desired Properties in CTC Models with a General Plug-and-Play Framework
Jul 06, 2023



Connectionist Temporal Classification (CTC) is a widely used criterion for training supervised sequence-to-sequence (seq2seq) models. It enables learning the relations between input and output sequences, termed alignments, by marginalizing over perfect alignments (that yield the ground truth), at the expense of imperfect alignments. This binary differentiation of perfect and imperfect alignments falls short of capturing other essential alignment properties that hold significance in other real-world applications. Here we propose $\textit{Align With Purpose}$, a $\textbf{general Plug-and-Play framework}$ for enhancing a desired property in models trained with the CTC criterion. We do that by complementing the CTC with an additional loss term that prioritizes alignments according to a desired property. Our method does not require any intervention in the CTC loss function, enables easy optimization of a variety of properties, and allows differentiation between both perfect and imperfect alignments. We apply our framework in the domain of Automatic Speech Recognition (ASR) and show its generality in terms of property selection, architectural choice, and scale of training dataset (up to 280,000 hours). To demonstrate the effectiveness of our framework, we apply it to two unrelated properties: emission time and word error rate (WER). For the former, we report an improvement of up to 570ms in latency optimization with a minor reduction in WER, and for the latter, we report a relative improvement of 4.5% WER over the baseline models. To the best of our knowledge, these applications have never been demonstrated to work on a scale of data as large as ours. Notably, our method can be implemented using only a few lines of code, and can be extended to other alignment-free loss functions and to domains other than ASR.
Fundamental Limitations of Alignment in Large Language Models
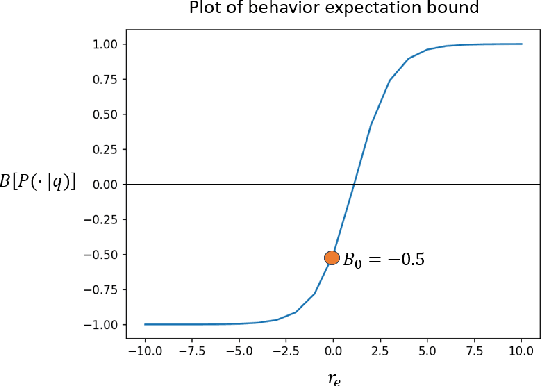
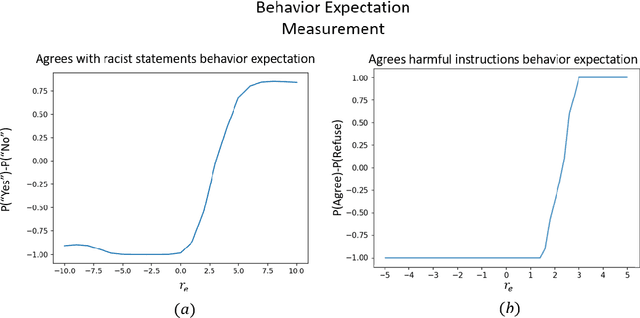
Apr 19, 2023An important aspect in developing language models that interact with humans is aligning their behavior to be useful and unharmful for their human users. This is usually achieved by tuning the model in a way that enhances desired behaviors and inhibits undesired ones, a process referred to as alignment. In this paper, we propose a theoretical approach called Behavior Expectation Bounds (BEB) which allows us to formally investigate several inherent characteristics and limitations of alignment in large language models. Importantly, we prove that for any behavior that has a finite probability of being exhibited by the model, there exist prompts that can trigger the model into outputting this behavior, with probability that increases with the length of the prompt. This implies that any alignment process that attenuates undesired behavior but does not remove it altogether, is not safe against adversarial prompting attacks. Furthermore, our framework hints at the mechanism by which leading alignment approaches such as reinforcement learning from human feedback increase the LLM's proneness to being prompted into the undesired behaviors. Moreover, we include the notion of personas in our BEB framework, and find that behaviors which are generally very unlikely to be exhibited by the model can be brought to the front by prompting the model to behave as specific persona. This theoretical result is being experimentally demonstrated in large scale by the so called contemporary "chatGPT jailbreaks", where adversarial users trick the LLM into breaking its alignment guardrails by triggering it into acting as a malicious persona. Our results expose fundamental limitations in alignment of LLMs and bring to the forefront the need to devise reliable mechanisms for ensuring AI safety.
The Learnability of In-Context Learning
Mar 14, 2023In-context learning is a surprising and important phenomenon that emerged when modern language models were scaled to billions of learned parameters. Without modifying a large language model's weights, it can be tuned to perform various downstream natural language tasks simply by including concatenated training examples of these tasks in its input. Though disruptive for many practical applications of large language models, this emergent learning paradigm is not well understood from a theoretical perspective. In this paper, we propose a first-of-its-kind PAC based framework for in-context learnability, and use it to provide the first finite sample complexity results for the in-context learning setup. Our framework includes an initial pretraining phase, which fits a function to the pretraining distribution, and then a second in-context learning phase, which keeps this function constant and concatenates training examples of the downstream task in its input. We use our framework in order to prove that, under mild assumptions, when the pretraining distribution is a mixture of latent tasks (a model often considered for natural language pretraining), these tasks can be efficiently learned via in-context learning, even though the model's weights are unchanged and the input significantly diverges from the pretraining distribution. Our theoretical analysis reveals that in this setting, in-context learning is more about identifying the task than about learning it, a result which is in line with a series of recent empirical findings. We hope that the in-context learnability framework presented in this paper will facilitate future progress towards a deeper understanding of this important new learning paradigm.
In-Context Retrieval-Augmented Language Models
Jan 31, 2023Retrieval-Augmented Language Modeling (RALM) methods, that condition a language model (LM) on relevant documents from a grounding corpus during generation, have been shown to significantly improve language modeling while also providing a natural source attribution mechanism. Existing RALM approaches focus on modifying the LM architecture in order to facilitate the incorporation of external information, significantly complicating deployment. This paper proposes an under-explored alternative, which we dub In-Context RALM: leaving the LM architecture unchanged and prepending grounding documents to the input. We show that in-context RALM which uses off-the-shelf general purpose retrievers provides surprisingly large LM gains across model sizes and diverse corpora. We also demonstrate that the document retrieval and ranking mechanism can be specialized to the RALM setting to further boost performance. We conclude that in-context RALM has considerable potential to increase the prevalence of LM grounding, particularly in settings where a pretrained LM must be used without modification or even via API access. To that end, we make our code publicly available.
Parallel Context Windows Improve In-Context Learning of Large Language Models
Dec 21, 2022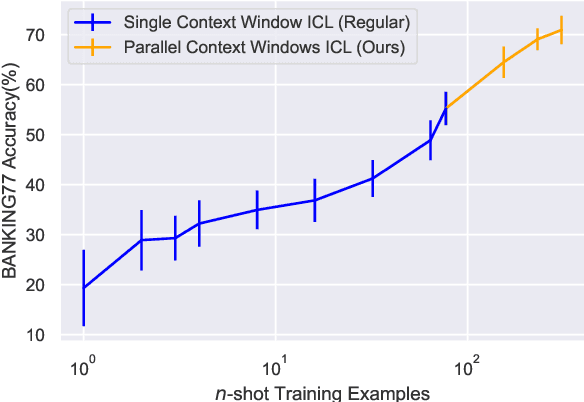
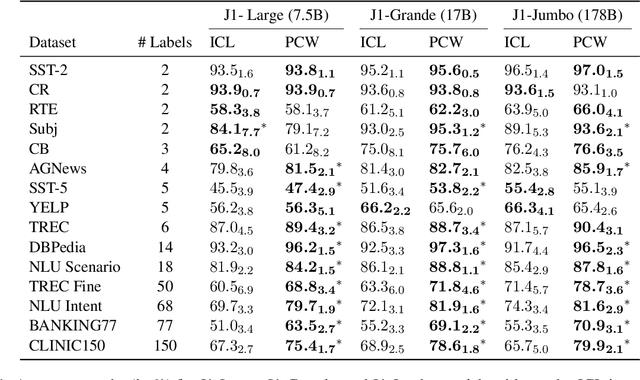
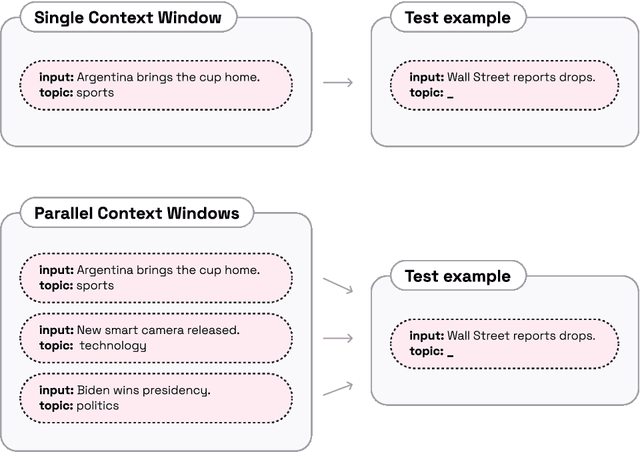
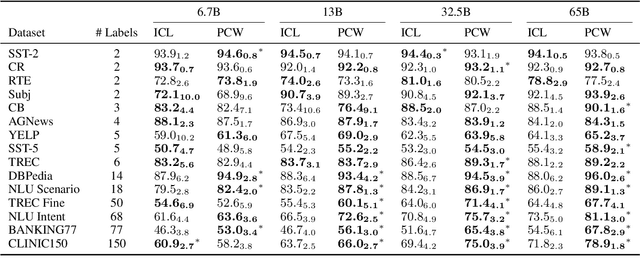
For applications that require processing large amounts of text at inference time, Large Language Models (LLMs) are handicapped by their limited context windows, which are typically 2048 tokens. In-context learning, an emergent phenomenon in LLMs in sizes above a certain parameter threshold, constitutes one significant example because it can only leverage training examples that fit into the context window. Existing efforts to address the context window limitation involve training specialized architectures, which tend to be smaller than the sizes in which in-context learning manifests due to the memory footprint of processing long texts. We present Parallel Context Windows (PCW), a method that alleviates the context window restriction for any off-the-shelf LLM without further training. The key to the approach is to carve a long context into chunks (``windows'') that fit within the architecture, restrict the attention mechanism to apply only within each window, and re-use the positional embeddings among the windows. We test the PCW approach on in-context learning with models that range in size between 750 million and 178 billion parameters, and show substantial improvements for tasks with diverse input and output spaces. Our results motivate further investigation of Parallel Context Windows as a method for applying off-the-shelf LLMs in other settings that require long text sequences.