 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024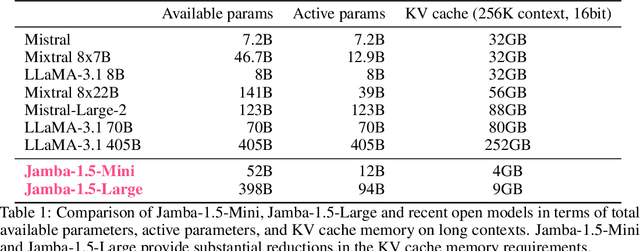
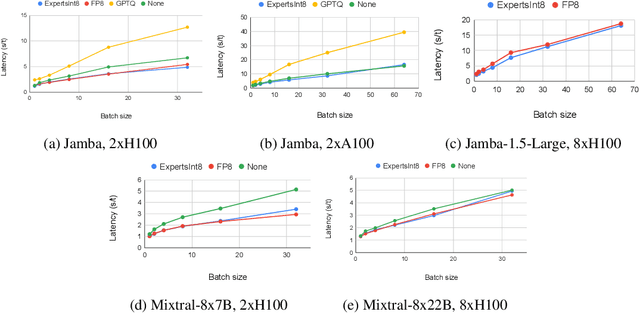
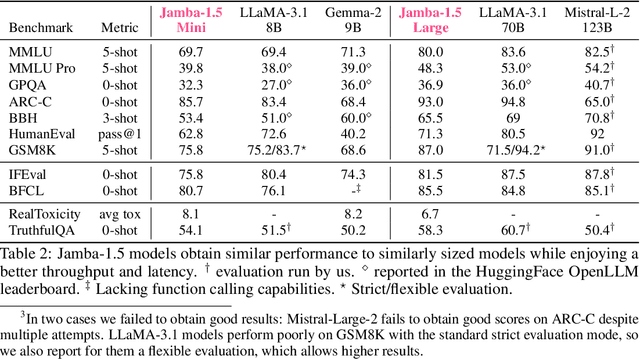
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
Jamba: A Hybrid Transformer-Mamba Language Model
Mar 28, 2024



We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
Human or Not? A Gamified Approach to the Turing Test
May 31, 2023



We present "Human or Not?", an online game inspired by the Turing test, that measures the capability of AI chatbots to mimic humans in dialog, and of humans to tell bots from other humans. Over the course of a month, the game was played by over 1.5 million users who engaged in anonymous two-minute chat sessions with either another human or an AI language model which was prompted to behave like humans. The task of the players was to correctly guess whether they spoke to a person or to an AI. This largest scale Turing-style test conducted to date revealed some interesting facts. For example, overall users guessed the identity of their partners correctly in only 68% of the games. In the subset of the games in which users faced an AI bot, users had even lower correct guess rates of 60% (that is, not much higher than chance). This white paper details the development, deployment, and results of this unique experiment. While this experiment calls for many extensions and refinements, these findings already begin to shed light on the inevitable near future which will commingle humans and AI.
MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning
May 01, 2022
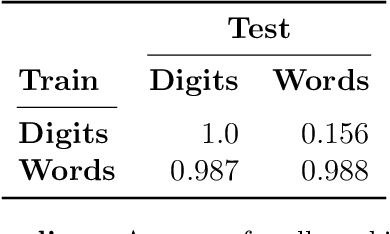

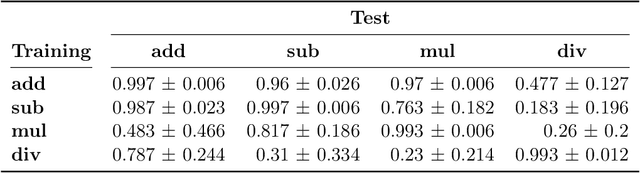
Huge language models (LMs) have ushered in a new era for AI, serving as a gateway to natural-language-based knowledge tasks. Although an essential element of modern AI, LMs are also inherently limited in a number of ways. We discuss these limitations and how they can be avoided by adopting a systems approach. Conceptualizing the challenge as one that involves knowledge and reasoning in addition to linguistic processing, we define a flexible architecture with multiple neural models, complemented by discrete knowledge and reasoning modules. We describe this neuro-symbolic architecture, dubbed the Modular Reasoning, Knowledge and Language (MRKL, pronounced "miracle") system, some of the technical challenges in implementing it, and Jurassic-X, AI21 Labs' MRKL system implementation.
Standing on the Shoulders of Giant Frozen Language Models
Apr 21, 2022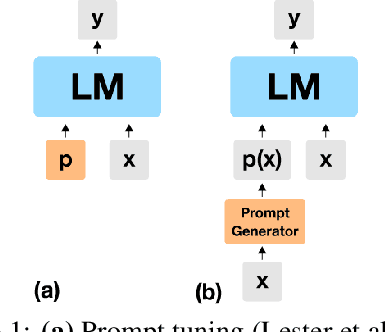
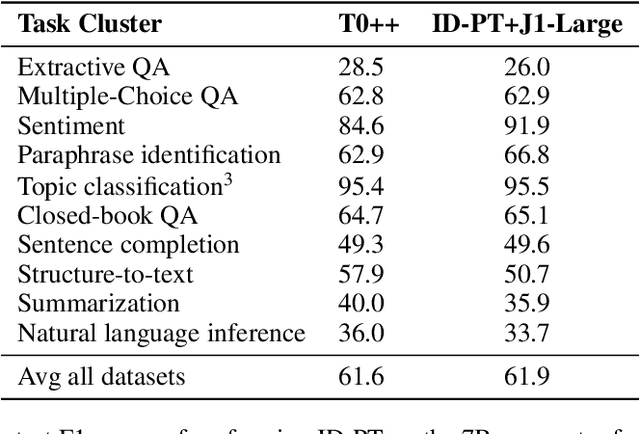
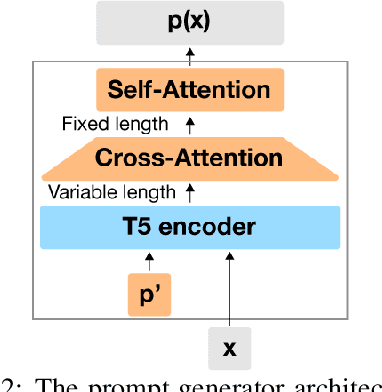

Huge pretrained language models (LMs) have demonstrated surprisingly good zero-shot capabilities on a wide variety of tasks. This gives rise to the appealing vision of a single, versatile model with a wide range of functionalities across disparate applications. However, current leading techniques for leveraging a "frozen" LM -- i.e., leaving its weights untouched -- still often underperform fine-tuning approaches which modify these weights in a task-dependent way. Those, in turn, suffer forgetfulness and compromise versatility, suggesting a tradeoff between performance and versatility. The main message of this paper is that current frozen-model techniques such as prompt tuning are only the tip of the iceberg, and more powerful methods for leveraging frozen LMs can do just as well as fine tuning in challenging domains without sacrificing the underlying model's versatility. To demonstrate this, we introduce three novel methods for leveraging frozen models: input-dependent prompt tuning, frozen readers, and recursive LMs, each of which vastly improves on current frozen-model approaches. Indeed, some of our methods even outperform fine-tuning approaches in domains currently dominated by the latter. The computational cost of each method is higher than that of existing frozen model methods, but still negligible relative to a single pass through a huge frozen LM. Each of these methods constitutes a meaningful contribution in its own right, but by presenting these contributions together we aim to convince the reader of a broader message that goes beyond the details of any given method: that frozen models have untapped potential and that fine-tuning is often unnecessary.
Exemplar Guided Active Learning
Nov 02, 2020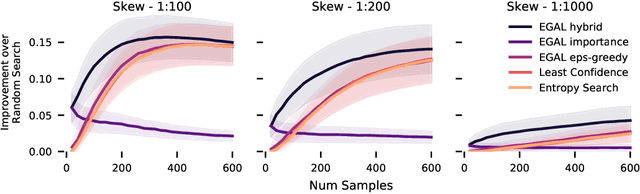
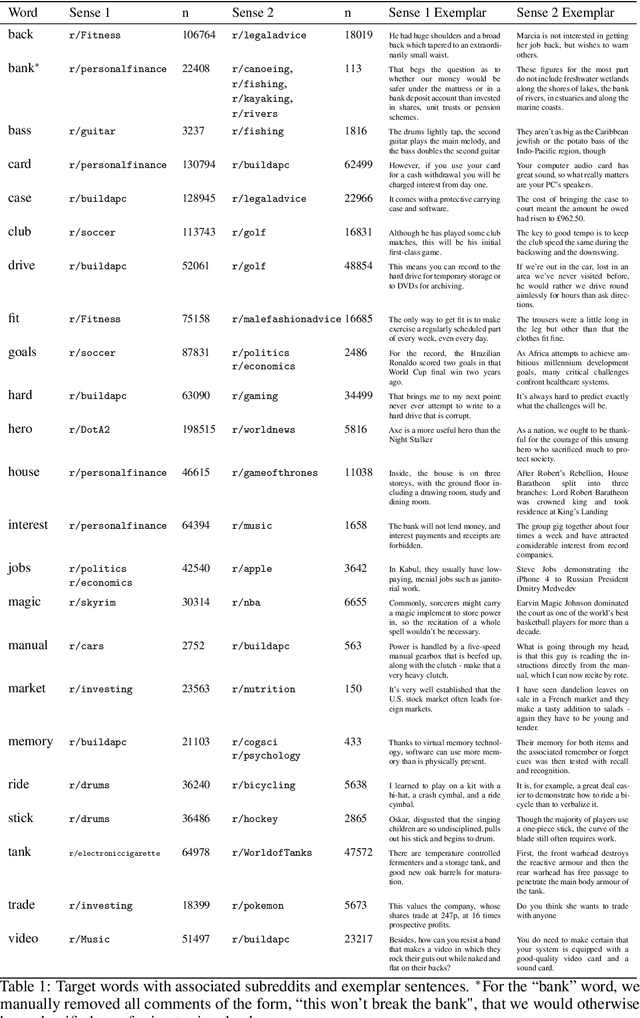
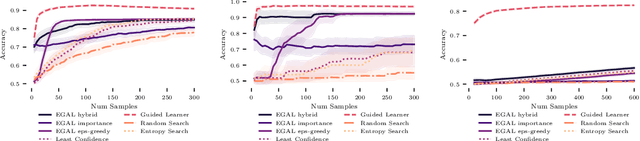
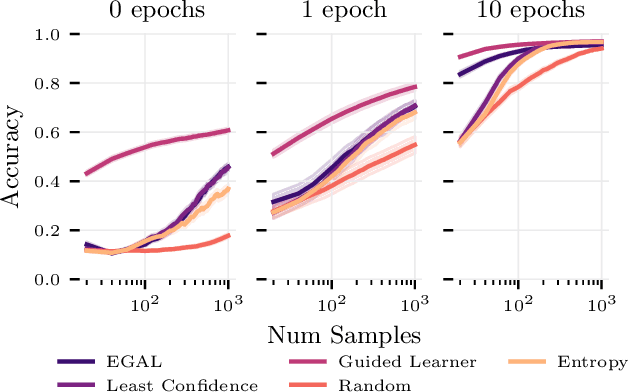
We consider the problem of wisely using a limited budget to label a small subset of a large unlabeled dataset. We are motivated by the NLP problem of word sense disambiguation. For any word, we have a set of candidate labels from a knowledge base, but the label set is not necessarily representative of what occurs in the data: there may exist labels in the knowledge base that very rarely occur in the corpus because the sense is rare in modern English; and conversely there may exist true labels that do not exist in our knowledge base. Our aim is to obtain a classifier that performs as well as possible on examples of each "common class" that occurs with frequency above a given threshold in the unlabeled set while annotating as few examples as possible from "rare classes" whose labels occur with less than this frequency. The challenge is that we are not informed which labels are common and which are rare, and the true label distribution may exhibit extreme skew. We describe an active learning approach that (1) explicitly searches for rare classes by leveraging the contextual embedding spaces provided by modern language models, and (2) incorporates a stopping rule that ignores classes once we prove that they occur below our target threshold with high probability. We prove that our algorithm only costs logarithmically more than a hypothetical approach that knows all true label frequencies and show experimentally that incorporating automated search can significantly reduce the number of samples needed to reach target accuracy levels.
PMI-Masking: Principled masking of correlated spans
Oct 05, 2020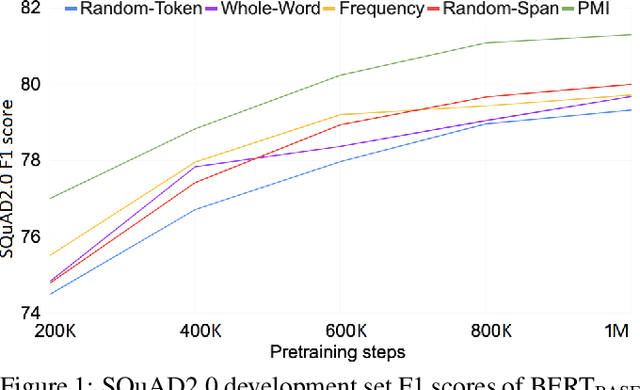

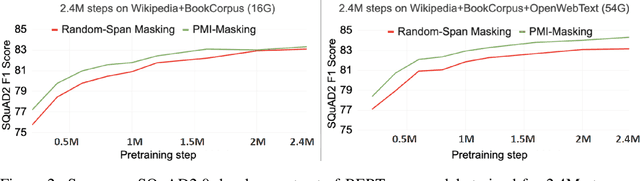
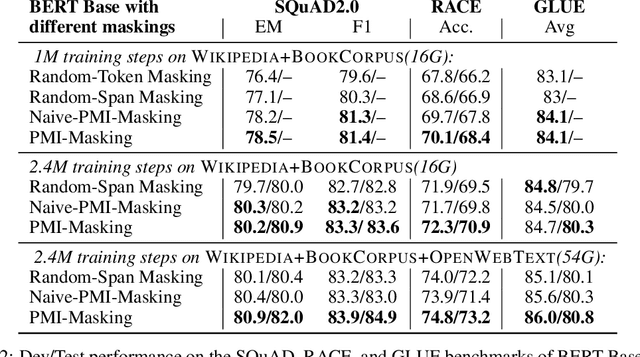
Masking tokens uniformly at random constitutes a common flaw in the pretraining of Masked Language Models (MLMs) such as BERT. We show that such uniform masking allows an MLM to minimize its training objective by latching onto shallow local signals, leading to pretraining inefficiency and suboptimal downstream performance. To address this flaw, we propose PMI-Masking, a principled masking strategy based on the concept of Pointwise Mutual Information (PMI), which jointly masks a token n-gram if it exhibits high collocation over the corpus. PMI-Masking motivates, unifies, and improves upon prior more heuristic approaches that attempt to address the drawback of random uniform token masking, such as whole-word masking, entity/phrase masking, and random-span masking. Specifically, we show experimentally that PMI-Masking reaches the performance of prior masking approaches in half the training time, and consistently improves performance at the end of training.
SenseBERT: Driving Some Sense into BERT
Aug 15, 2019

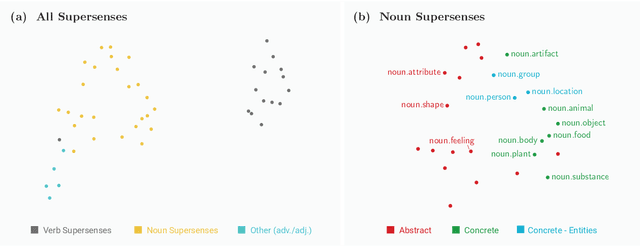
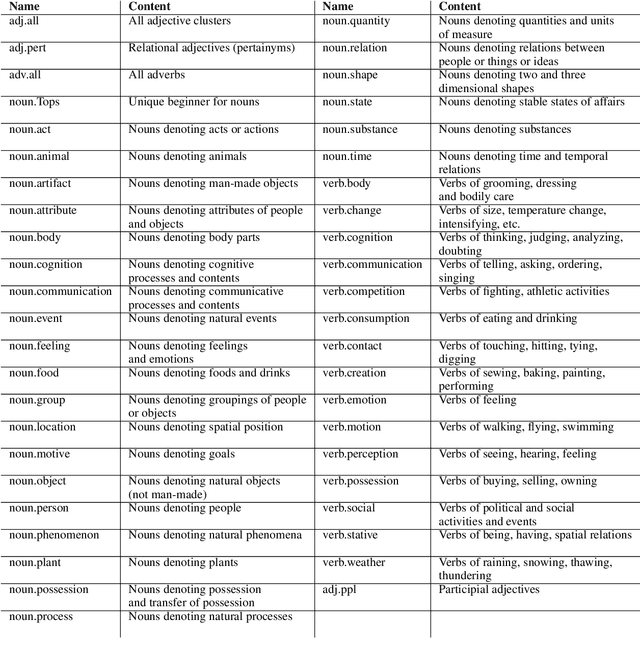
Self-supervision techniques have allowed neural language models to advance the frontier in Natural Language Understanding. However, existing self-supervision techniques operate at the word-form level, which serves as a surrogate for the underlying semantic content. This paper proposes a method to employ self-supervision directly at the word-sense level. Our model, named SenseBERT, is pre-trained to predict not only the masked words but also their WordNet supersenses. Accordingly, we attain a lexical-semantic level language model, without the use of human annotation. SenseBERT achieves significantly improved lexical understanding, as we demonstrate by experimenting on SemEval, and by attaining a state of the art result on the Word in Context (WiC) task. Our approach is extendable to other linguistic signals, which can be similarly integrated into the pre-training process, leading to increasingly semantically informed language models.