 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024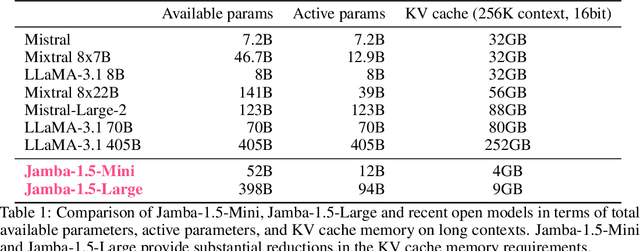
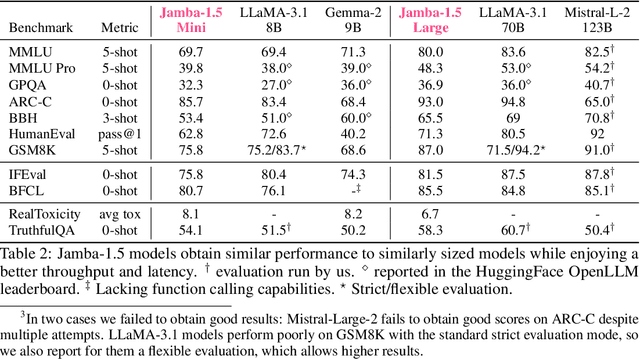
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
Jamba: A Hybrid Transformer-Mamba Language Model
Mar 28, 2024



We present Jamba, a new base large language model based on a novel hybrid Transformer-Mamba mixture-of-experts (MoE) architecture. Specifically, Jamba interleaves blocks of Transformer and Mamba layers, enjoying the benefits of both model families. MoE is added in some of these layers to increase model capacity while keeping active parameter usage manageable. This flexible architecture allows resource- and objective-specific configurations. In the particular configuration we have implemented, we end up with a powerful model that fits in a single 80GB GPU. Built at large scale, Jamba provides high throughput and small memory footprint compared to vanilla Transformers, and at the same time state-of-the-art performance on standard language model benchmarks and long-context evaluations. Remarkably, the model presents strong results for up to 256K tokens context length. We study various architectural decisions, such as how to combine Transformer and Mamba layers, and how to mix experts, and show that some of them are crucial in large scale modeling. We also describe several interesting properties of these architectures which the training and evaluation of Jamba have revealed, and plan to release checkpoints from various ablation runs, to encourage further exploration of this novel architecture. We make the weights of our implementation of Jamba publicly available under a permissive license.
fMRI Neurofeedback Learning Patterns are Predictive of Personal and Clinical Traits
Dec 21, 2021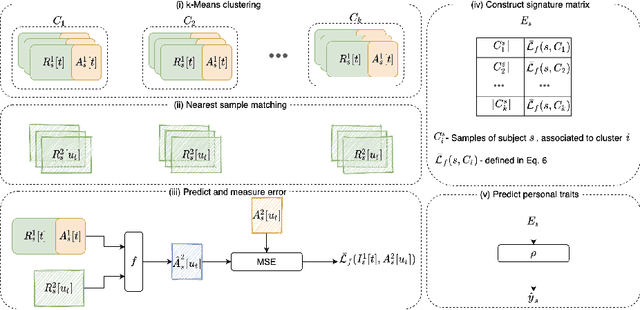
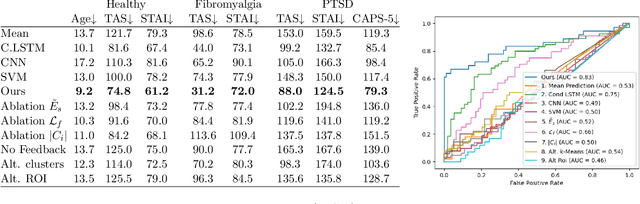
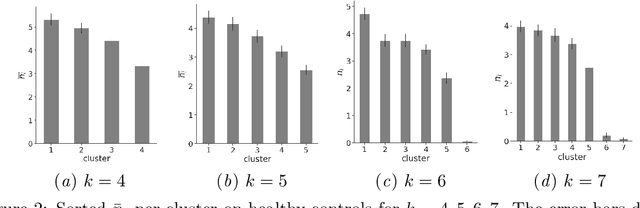

We obtain a personal signature of a person's learning progress in a self-neuromodulation task, guided by functional MRI (fMRI). The signature is based on predicting the activity of the Amygdala in a second neurofeedback session, given a similar fMRI-derived brain state in the first session. The prediction is made by a deep neural network, which is trained on the entire training cohort of patients. This signal, which is indicative of a person's progress in performing the task of Amygdala modulation, is aggregated across multiple prototypical brain states and then classified by a linear classifier to various personal and clinical indications. The predictive power of the obtained signature is stronger than previous approaches for obtaining a personal signature from fMRI neurofeedback and provides an indication that a person's learning pattern may be used as a diagnostic tool. Our code has been made available, and data would be shared, subject to ethical approvals.
Learning Personal Representations from fMRIby Predicting Neurofeedback Performance
Dec 06, 2021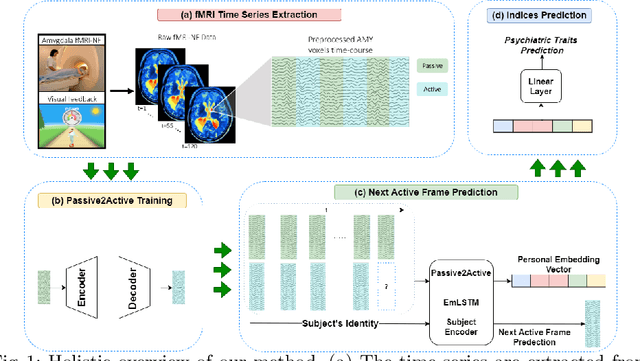
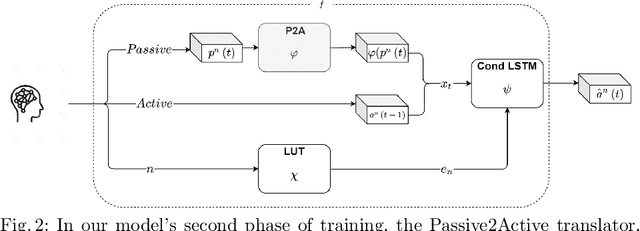
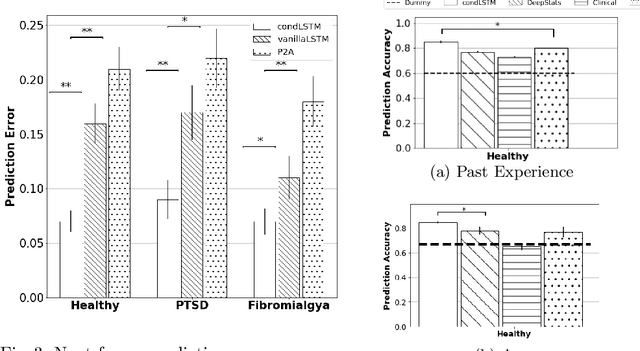
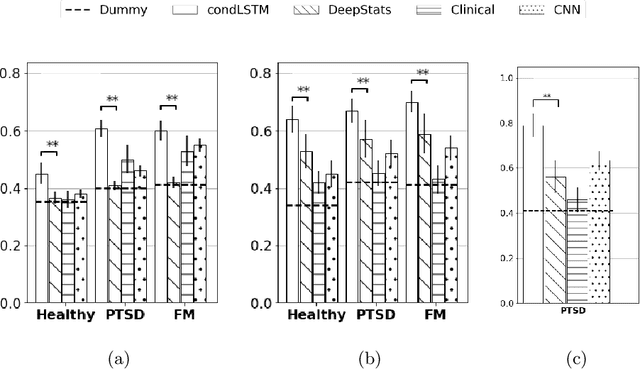
We present a deep neural network method for learning a personal representation for individuals that are performing a self neuromodulation task, guided by functional MRI (fMRI). This neurofeedback task (watch vs. regulate) provides the subjects with a continuous feedback contingent on down regulation of their Amygdala signal and the learning algorithm focuses on this region's time-course of activity. The representation is learned by a self-supervised recurrent neural network, that predicts the Amygdala activity in the next fMRI frame given recent fMRI frames and is conditioned on the learned individual representation. It is shown that the individuals' representation improves the next-frame prediction considerably. Moreover, this personal representation, learned solely from fMRI images, yields good performance in linear prediction of psychiatric traits, which is better than performing such a prediction based on clinical data and personality tests. Our code is attached as supplementary and the data would be shared subject to ethical approvals.