 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJamba-1.5: Hybrid Transformer-Mamba Models at Scale
Aug 22, 2024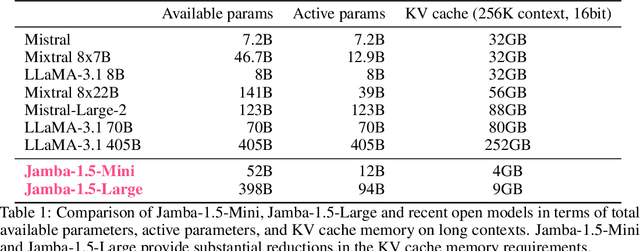
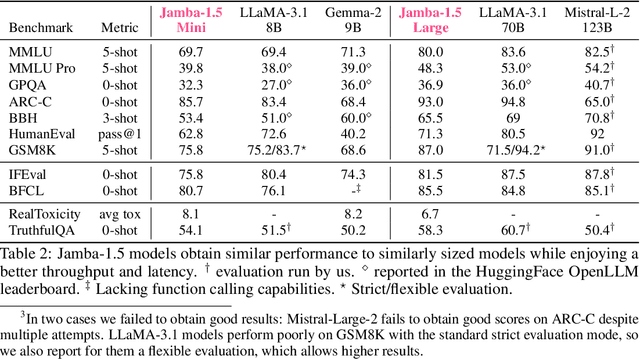
We present Jamba-1.5, new instruction-tuned large language models based on our Jamba architecture. Jamba is a hybrid Transformer-Mamba mixture of experts architecture, providing high throughput and low memory usage across context lengths, while retaining the same or better quality as Transformer models. We release two model sizes: Jamba-1.5-Large, with 94B active parameters, and Jamba-1.5-Mini, with 12B active parameters. Both models are fine-tuned for a variety of conversational and instruction-following capabilties, and have an effective context length of 256K tokens, the largest amongst open-weight models. To support cost-effective inference, we introduce ExpertsInt8, a novel quantization technique that allows fitting Jamba-1.5-Large on a machine with 8 80GB GPUs when processing 256K-token contexts without loss of quality. When evaluated on a battery of academic and chatbot benchmarks, Jamba-1.5 models achieve excellent results while providing high throughput and outperforming other open-weight models on long-context benchmarks. The model weights for both sizes are publicly available under the Jamba Open Model License and we release ExpertsInt8 as open source.
Technical Report: Auxiliary Tuning and its Application to Conditional Text Generation
Jun 30, 2020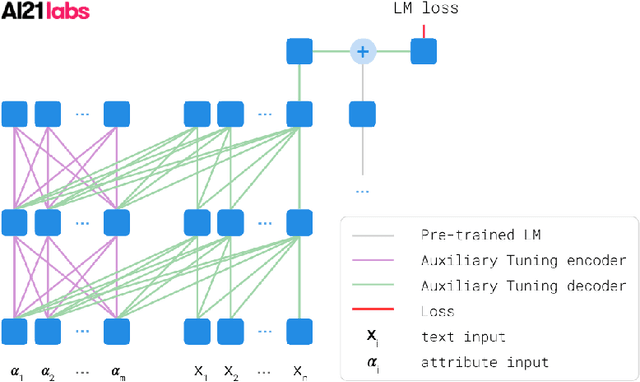

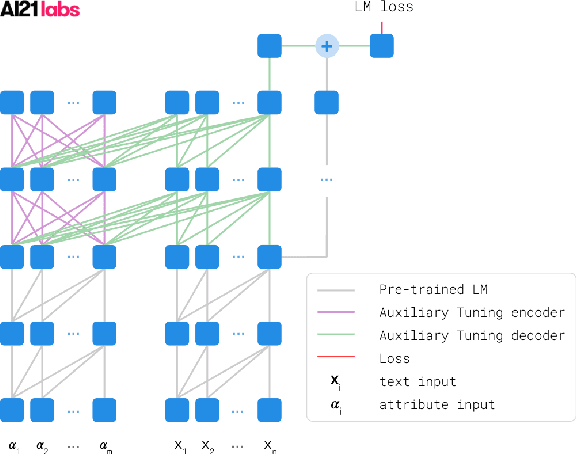
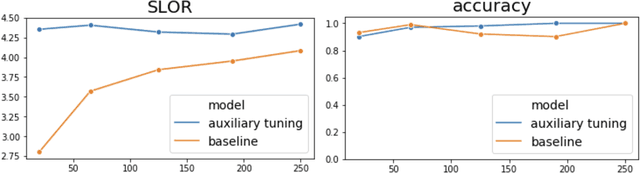
We introduce a simple and efficient method, called Auxiliary Tuning, for adapting a pre-trained Language Model to a novel task; we demonstrate this approach on the task of conditional text generation. Our approach supplements the original pre-trained model with an auxiliary model that shifts the output distribution according to the target task. The auxiliary model is trained by adding its logits to the pre-trained model logits and maximizing the likelihood of the target task output. Our method imposes no constraints on the auxiliary architecture. In particular, the auxiliary model can ingest additional input relevant to the target task, independently from the pre-trained model's input. Furthermore, mixing the models at the logits level provides a natural probabilistic interpretation of the method. Our method achieved similar results to training from scratch for several different tasks, while using significantly fewer resources for training; we share a specific example of text generation conditioned on keywords.
The Cost of Training NLP Models: A Concise Overview
Apr 19, 2020We review the cost of training large-scale language models, and the drivers of these costs. The intended audience includes engineers and scientists budgeting their model-training experiments, as well as non-practitioners trying to make sense of the economics of modern-day Natural Language Processing (NLP).