 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormulaOne: Measuring the Depth of Algorithmic Reasoning Beyond Competitive Programming
Jul 17, 2025Frontier AI models demonstrate formidable breadth of knowledge. But how close are they to true human -- or superhuman -- expertise? Genuine experts can tackle the hardest problems and push the boundaries of scientific understanding. To illuminate the limits of frontier model capabilities, we turn away from contrived competitive programming puzzles, and instead focus on real-life research problems. We construct FormulaOne, a benchmark that lies at the intersection of graph theory, logic, and algorithms, all well within the training distribution of frontier models. Our problems are incredibly demanding, requiring an array of reasoning steps. The dataset has three key properties. First, it is of commercial interest and relates to practical large-scale optimisation problems, such as those arising in routing, scheduling, and network design. Second, it is generated from the highly expressive framework of Monadic Second-Order (MSO) logic on graphs, paving the way toward automatic problem generation at scale; ideal for building RL environments. Third, many of our problems are intimately related to the frontier of theoretical computer science, and to central conjectures therein, such as the Strong Exponential Time Hypothesis (SETH). As such, any significant algorithmic progress on our dataset, beyond known results, could carry profound theoretical implications. Remarkably, state-of-the-art models like OpenAI's o3 fail entirely on FormulaOne, solving less than 1% of the questions, even when given 10 attempts and explanatory fewshot examples -- highlighting how far they remain from expert-level understanding in some domains. To support further research, we additionally curate FormulaOne-Warmup, offering a set of simpler tasks, from the same distribution. We release the full corpus along with a comprehensive evaluation framework.
Artificial Expert Intelligence through PAC-reasoning
Dec 03, 2024Artificial Expert Intelligence (AEI) seeks to transcend the limitations of both Artificial General Intelligence (AGI) and narrow AI by integrating domain-specific expertise with critical, precise reasoning capabilities akin to those of top human experts. Existing AI systems often excel at predefined tasks but struggle with adaptability and precision in novel problem-solving. To overcome this, AEI introduces a framework for ``Probably Approximately Correct (PAC) Reasoning". This paradigm provides robust theoretical guarantees for reliably decomposing complex problems, with a practical mechanism for controlling reasoning precision. In reference to the division of human thought into System 1 for intuitive thinking and System 2 for reflective reasoning~\citep{tversky1974judgment}, we refer to this new type of reasoning as System 3 for precise reasoning, inspired by the rigor of the scientific method. AEI thus establishes a foundation for error-bounded, inference-time learning.
ChatGPT Based Data Augmentation for Improved Parameter-Efficient Debiasing of LLMs
Feb 19, 2024Large Language models (LLMs), while powerful, exhibit harmful social biases. Debiasing is often challenging due to computational costs, data constraints, and potential degradation of multi-task language capabilities. This work introduces a novel approach utilizing ChatGPT to generate synthetic training data, aiming to enhance the debiasing of LLMs. We propose two strategies: Targeted Prompting, which provides effective debiasing for known biases but necessitates prior specification of bias in question; and General Prompting, which, while slightly less effective, offers debiasing across various categories. We leverage resource-efficient LLM debiasing using adapter tuning and compare the effectiveness of our synthetic data to existing debiasing datasets. Our results reveal that: (1) ChatGPT can efficiently produce high-quality training data for debiasing other LLMs; (2) data produced via our approach surpasses existing datasets in debiasing performance while also preserving internal knowledge of a pre-trained LLM; and (3) synthetic data exhibits generalizability across categories, effectively mitigating various biases, including intersectional ones. These findings underscore the potential of synthetic data in advancing the fairness of LLMs with minimal retraining cost.
Incrementally-Computable Neural Networks: Efficient Inference for Dynamic Inputs
Jul 27, 2023

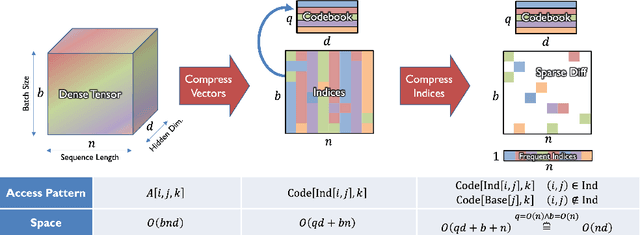

Deep learning often faces the challenge of efficiently processing dynamic inputs, such as sensor data or user inputs. For example, an AI writing assistant is required to update its suggestions in real time as a document is edited. Re-running the model each time is expensive, even with compression techniques like knowledge distillation, pruning, or quantization. Instead, we take an incremental computing approach, looking to reuse calculations as the inputs change. However, the dense connectivity of conventional architectures poses a major obstacle to incremental computation, as even minor input changes cascade through the network and restrict information reuse. To address this, we use vector quantization to discretize intermediate values in the network, which filters out noisy and unnecessary modifications to hidden neurons, facilitating the reuse of their values. We apply this approach to the transformers architecture, creating an efficient incremental inference algorithm with complexity proportional to the fraction of the modified inputs. Our experiments with adapting the OPT-125M pre-trained language model demonstrate comparable accuracy on document classification while requiring 12.1X (median) fewer operations for processing sequences of atomic edits.
Towards Neural Variational Monte Carlo That Scales Linearly with System Size
Dec 21, 2022


Quantum many-body problems are some of the most challenging problems in science and are central to demystifying some exotic quantum phenomena, e.g., high-temperature superconductors. The combination of neural networks (NN) for representing quantum states, coupled with the Variational Monte Carlo (VMC) algorithm, has been shown to be a promising method for solving such problems. However, the run-time of this approach scales quadratically with the number of simulated particles, constraining the practically usable NN to - in machine learning terms - minuscule sizes (<10M parameters). Considering the many breakthroughs brought by extreme NN in the +1B parameters scale to other domains, lifting this constraint could significantly expand the set of quantum systems we can accurately simulate on classical computers, both in size and complexity. We propose a NN architecture called Vector-Quantized Neural Quantum States (VQ-NQS) that utilizes vector-quantization techniques to leverage redundancies in the local-energy calculations of the VMC algorithm - the source of the quadratic scaling. In our preliminary experiments, we demonstrate VQ-NQS ability to reproduce the ground state of the 2D Heisenberg model across various system sizes, while reporting a significant reduction of about ${\times}10$ in the number of FLOPs in the local-energy calculation.
Neural tensor contractions and the expressive power of deep neural quantum states
Mar 18, 2021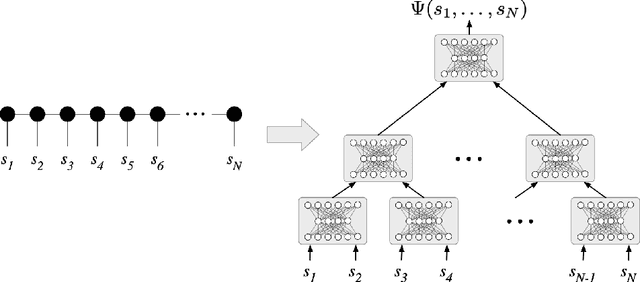


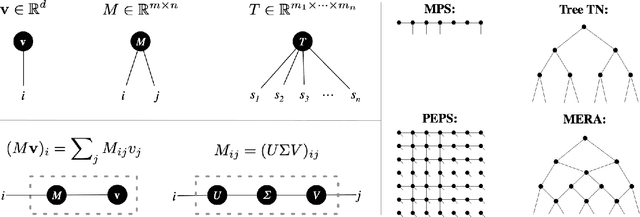
We establish a direct connection between general tensor networks and deep feed-forward artificial neural networks. The core of our results is the construction of neural-network layers that efficiently perform tensor contractions, and that use commonly adopted non-linear activation functions. The resulting deep networks feature a number of edges that closely matches the contraction complexity of the tensor networks to be approximated. In the context of many-body quantum states, this result establishes that neural-network states have strictly the same or higher expressive power than practically usable variational tensor networks. As an example, we show that all matrix product states can be efficiently written as neural-network states with a number of edges polynomial in the bond dimension and depth logarithmic in the system size. The opposite instead does not hold true, and our results imply that there exist quantum states that are not efficiently expressible in terms of matrix product states or practically usable PEPS, but that are instead efficiently expressible with neural network states.
Technical Report: Auxiliary Tuning and its Application to Conditional Text Generation
Jun 30, 2020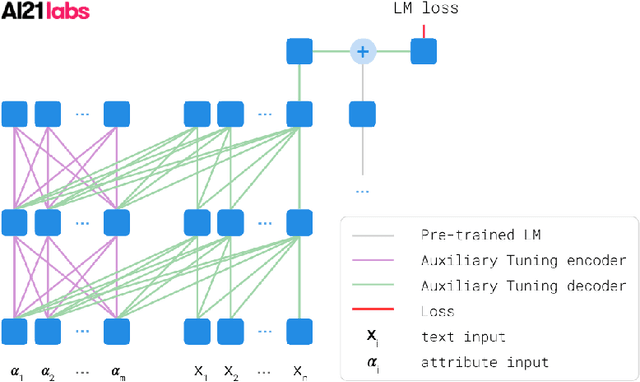

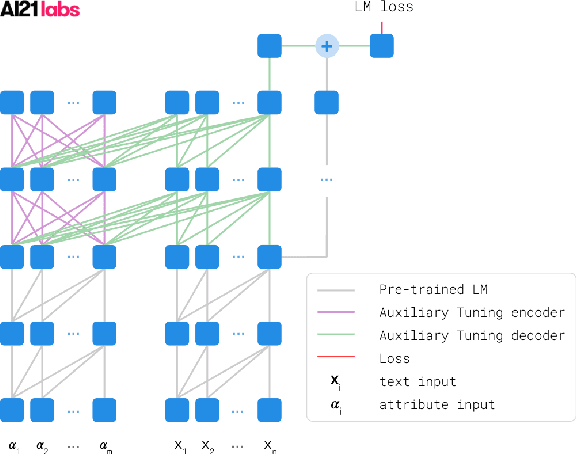
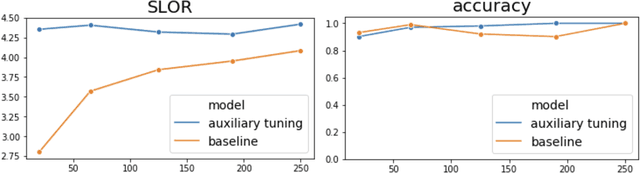
We introduce a simple and efficient method, called Auxiliary Tuning, for adapting a pre-trained Language Model to a novel task; we demonstrate this approach on the task of conditional text generation. Our approach supplements the original pre-trained model with an auxiliary model that shifts the output distribution according to the target task. The auxiliary model is trained by adding its logits to the pre-trained model logits and maximizing the likelihood of the target task output. Our method imposes no constraints on the auxiliary architecture. In particular, the auxiliary model can ingest additional input relevant to the target task, independently from the pre-trained model's input. Furthermore, mixing the models at the logits level provides a natural probabilistic interpretation of the method. Our method achieved similar results to training from scratch for several different tasks, while using significantly fewer resources for training; we share a specific example of text generation conditioned on keywords.
Limits to Depth Efficiencies of Self-Attention
Jun 22, 2020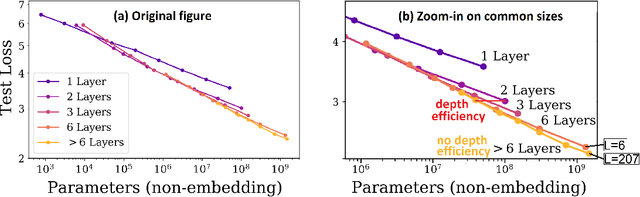
Self-attention architectures, which are rapidly pushing the frontier in natural language processing, demonstrate a surprising depth-inefficient behavior: Empirical signals indicate that increasing the internal representation (network width) is just as useful as increasing the number of self-attention layers (network depth). In this paper, we theoretically study the interplay between depth and width in self-attention, and shed light on the root of the above phenomenon. We invalidate the seemingly plausible hypothesis by which widening is as effective as deepening for self-attention, and show that in fact stacking self-attention layers is so effective that it quickly saturates a capacity of the network width. Specifically, we pinpoint a "depth threshold" that is logarithmic in $d_x$, the network width: $L_{\textrm{th}}=\log_{3}(d_x)$. For networks of depth that is below the threshold, we establish a double-exponential depth-efficiency of the self-attention operation, while for depths over the threshold we show that depth-inefficiency kicks in. Our predictions strongly accord with extensive empirical ablations in Kaplan et al. (2020), accounting for the different behaviors in the two depth-(in)efficiency regimes. By identifying network width as a limiting factor, our analysis indicates that solutions for dramatically increasing the width can facilitate the next leap in self-attention expressivity.
The Cost of Training NLP Models: A Concise Overview
Apr 19, 2020We review the cost of training large-scale language models, and the drivers of these costs. The intended audience includes engineers and scientists budgeting their model-training experiments, as well as non-practitioners trying to make sense of the economics of modern-day Natural Language Processing (NLP).
SenseBERT: Driving Some Sense into BERT
Aug 15, 2019

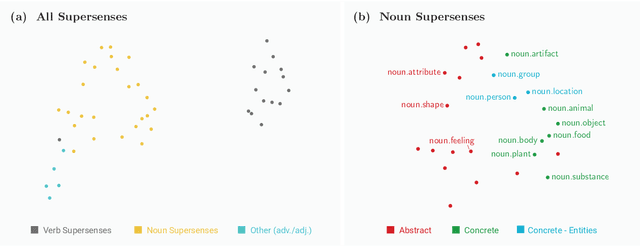
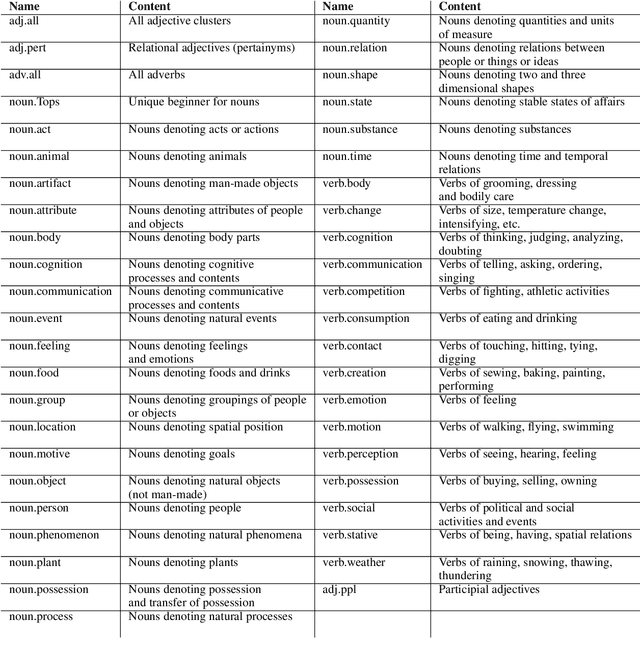
Self-supervision techniques have allowed neural language models to advance the frontier in Natural Language Understanding. However, existing self-supervision techniques operate at the word-form level, which serves as a surrogate for the underlying semantic content. This paper proposes a method to employ self-supervision directly at the word-sense level. Our model, named SenseBERT, is pre-trained to predict not only the masked words but also their WordNet supersenses. Accordingly, we attain a lexical-semantic level language model, without the use of human annotation. SenseBERT achieves significantly improved lexical understanding, as we demonstrate by experimenting on SemEval, and by attaining a state of the art result on the Word in Context (WiC) task. Our approach is extendable to other linguistic signals, which can be similarly integrated into the pre-training process, leading to increasingly semantically informed language models.