 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComMer: a Framework for Compressing and Merging User Data for Personalization
Jan 05, 2025Large Language Models (LLMs) excel at a wide range of tasks, but adapting them to new data, particularly for personalized applications, poses significant challenges due to resource and computational constraints. Existing methods either rely on exposing fresh data to the model through the prompt, which is limited by context size and computationally expensive at inference time, or fine-tuning, which incurs substantial training and update costs. In this paper, we introduce ComMer - Compress and Merge - a novel framework that efficiently personalizes LLMs by compressing users' documents into compact representations, which are then merged and fed into a frozen LLM. We evaluate ComMer on two types of personalization tasks - personalized skill learning, using the tweet paraphrasing dataset and the personalized news headline generation dataset from the LaMP benchmark, and knowledge-intensive, using the PerLTQA dataset. Our experiments demonstrate that in constrained inference budget scenarios ComMer achieves superior quality in skill learning tasks, while highlighting limitations in knowledge-intensive settings due to the loss of detailed information. These results offer insights into trade-offs and potential optimizations in multi-document compression for personalization.
Standing on the Shoulders of Giant Frozen Language Models
Apr 21, 2022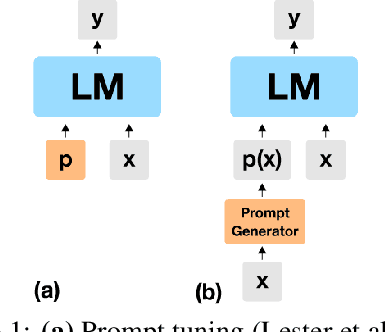
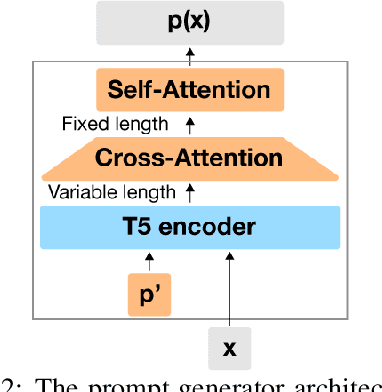

Huge pretrained language models (LMs) have demonstrated surprisingly good zero-shot capabilities on a wide variety of tasks. This gives rise to the appealing vision of a single, versatile model with a wide range of functionalities across disparate applications. However, current leading techniques for leveraging a "frozen" LM -- i.e., leaving its weights untouched -- still often underperform fine-tuning approaches which modify these weights in a task-dependent way. Those, in turn, suffer forgetfulness and compromise versatility, suggesting a tradeoff between performance and versatility. The main message of this paper is that current frozen-model techniques such as prompt tuning are only the tip of the iceberg, and more powerful methods for leveraging frozen LMs can do just as well as fine tuning in challenging domains without sacrificing the underlying model's versatility. To demonstrate this, we introduce three novel methods for leveraging frozen models: input-dependent prompt tuning, frozen readers, and recursive LMs, each of which vastly improves on current frozen-model approaches. Indeed, some of our methods even outperform fine-tuning approaches in domains currently dominated by the latter. The computational cost of each method is higher than that of existing frozen model methods, but still negligible relative to a single pass through a huge frozen LM. Each of these methods constitutes a meaningful contribution in its own right, but by presenting these contributions together we aim to convince the reader of a broader message that goes beyond the details of any given method: that frozen models have untapped potential and that fine-tuning is often unnecessary.
Technical Report: Auxiliary Tuning and its Application to Conditional Text Generation
Jun 30, 2020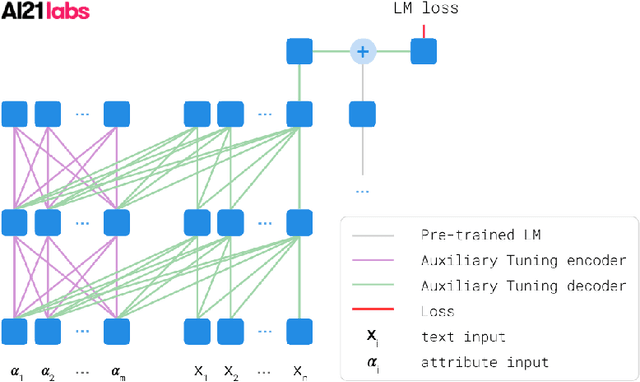

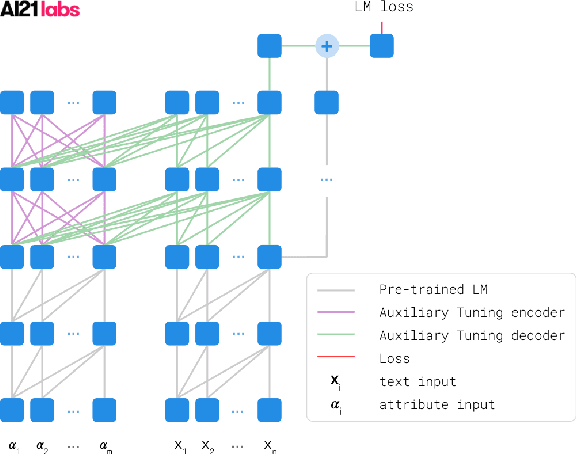
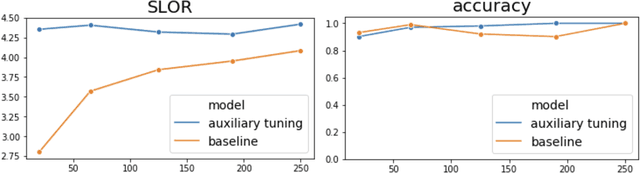
We introduce a simple and efficient method, called Auxiliary Tuning, for adapting a pre-trained Language Model to a novel task; we demonstrate this approach on the task of conditional text generation. Our approach supplements the original pre-trained model with an auxiliary model that shifts the output distribution according to the target task. The auxiliary model is trained by adding its logits to the pre-trained model logits and maximizing the likelihood of the target task output. Our method imposes no constraints on the auxiliary architecture. In particular, the auxiliary model can ingest additional input relevant to the target task, independently from the pre-trained model's input. Furthermore, mixing the models at the logits level provides a natural probabilistic interpretation of the method. Our method achieved similar results to training from scratch for several different tasks, while using significantly fewer resources for training; we share a specific example of text generation conditioned on keywords.
Deep density networks and uncertainty in recommender systems
May 06, 2018
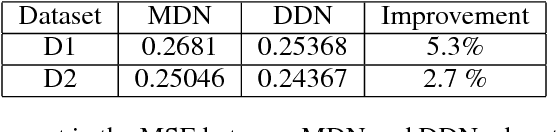
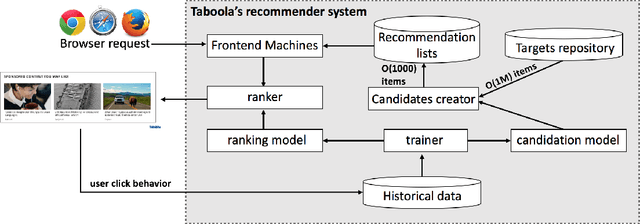
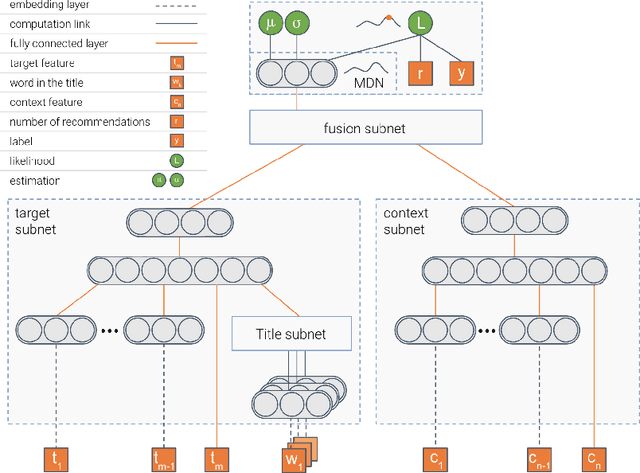
Building robust online content recommendation systems requires learning complex interactions between user preferences and content features. The field has evolved rapidly in recent years from traditional multi-arm bandit and collaborative filtering techniques, with new methods employing Deep Learning models to capture non-linearities. Despite progress, the dynamic nature of online recommendations still poses great challenges, such as finding the delicate balance between exploration and exploitation. In this paper we show how uncertainty estimations can be incorporated by employing them in an optimistic exploitation/exploration strategy for more efficient exploration of new recommendations. We provide a novel hybrid deep neural network model, Deep Density Networks (DDN), which integrates content-based deep learning models with a collaborative scheme that is able to robustly model and estimate uncertainty. Finally, we present online and offline results after incorporating DNN into a real world content recommendation system that serves billions of recommendations per day, and show the benefit of using DDN in practice.