 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLA: Block Sparse Plus Linear Attention for Long Context Modeling
Jan 29, 2026Block-wise sparse attention offers significant efficiency gains for long-context modeling, yet existing methods often suffer from low selection fidelity and cumulative contextual loss by completely discarding unselected blocks. To address these limitations, we introduce Sparse Plus Linear Attention (SPLA), a framework that utilizes a selection metric derived from second-order Taylor expansions to accurately identify relevant blocks for exact attention. Instead of discarding the remaining "long tail," SPLA compresses unselected blocks into a compact recurrent state via a residual linear attention (RLA) module. Crucially, to avoid IO overhead, we derive an optimized subtraction-based formulation for RLA -- calculating the residual as the difference between global and selected linear attention -- ensuring that unselected blocks are never explicitly accessed during inference. Our experiments demonstrate that SPLA closes the performance gap in continual pretraining, surpassing dense attention models on long-context benchmarks like RULER while maintaining competitive general knowledge and reasoning capabilities.
Continual Memorization of Factoids in Large Language Models
Nov 11, 2024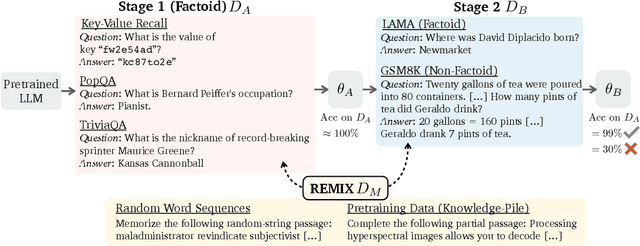
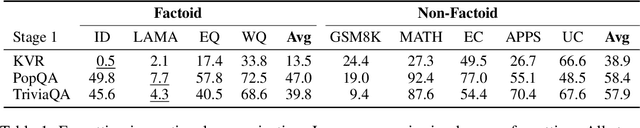
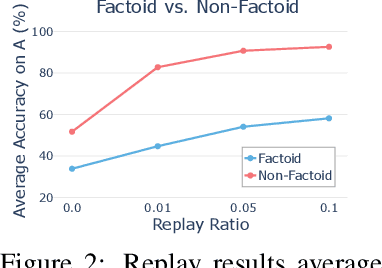
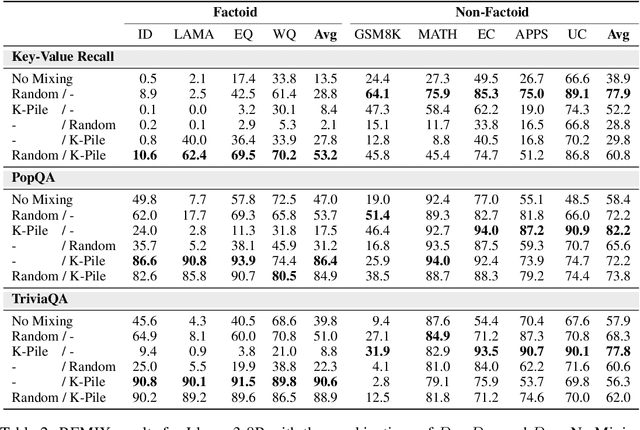
Large language models can absorb a massive amount of knowledge through pretraining, but pretraining is inefficient for acquiring long-tailed or specialized facts. Therefore, fine-tuning on specialized or new knowledge that reflects changes in the world has become popular, though it risks disrupting the model's original capabilities. We study this fragility in the context of continual memorization, where the model is trained on a small set of long-tail factoids (factual associations) and must retain these factoids after multiple stages of subsequent training on other datasets. Through extensive experiments, we show that LLMs suffer from forgetting across a wide range of subsequent tasks, and simple replay techniques do not fully prevent forgetting, especially when the factoid datasets are trained in the later stages. We posit that there are two ways to alleviate forgetting: 1) protect the memorization process as the model learns the factoids, or 2) reduce interference from training in later stages. With this insight, we develop an effective mitigation strategy: REMIX (Random and Generic Data Mixing). REMIX prevents forgetting by mixing generic data sampled from pretraining corpora or even randomly generated word sequences during each stage, despite being unrelated to the memorized factoids in the first stage. REMIX can recover performance from severe forgetting, often outperforming replay-based methods that have access to the factoids from the first stage. We then analyze how REMIX alters the learning process and find that successful forgetting prevention is associated with a pattern: the model stores factoids in earlier layers than usual and diversifies the set of layers that store these factoids. The efficacy of REMIX invites further investigation into the underlying dynamics of memorization and forgetting, opening exciting possibilities for future research.
When a language model is optimized for reasoning, does it still show embers of autoregression? An analysis of OpenAI o1
Oct 02, 2024In "Embers of Autoregression" (McCoy et al., 2023), we showed that several large language models (LLMs) have some important limitations that are attributable to their origins in next-word prediction. Here we investigate whether these issues persist with o1, a new system from OpenAI that differs from previous LLMs in that it is optimized for reasoning. We find that o1 substantially outperforms previous LLMs in many cases, with particularly large improvements on rare variants of common tasks (e.g., forming acronyms from the second letter of each word in a list, rather than the first letter). Despite these quantitative improvements, however, o1 still displays the same qualitative trends that we observed in previous systems. Specifically, o1 - like previous LLMs - is sensitive to the probability of examples and tasks, performing better and requiring fewer "thinking tokens" in high-probability settings than in low-probability ones. These results show that optimizing a language model for reasoning can mitigate but might not fully overcome the language model's probability sensitivity.
Representing Rule-based Chatbots with Transformers
Jul 15, 2024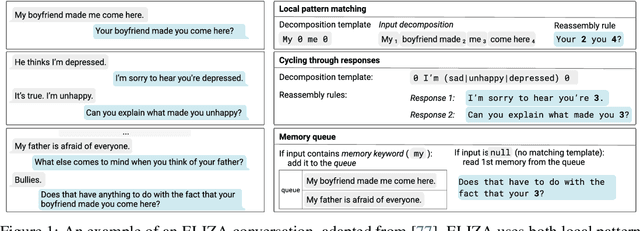


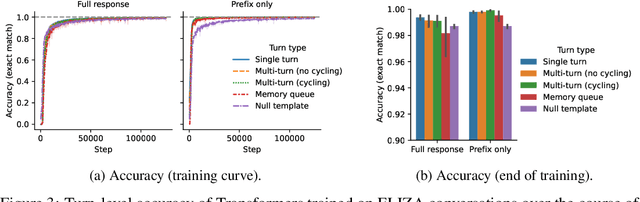
Transformer-based chatbots can conduct fluent, natural-sounding conversations, but we have limited understanding of the mechanisms underlying their behavior. Prior work has taken a bottom-up approach to understanding Transformers by constructing Transformers for various synthetic and formal language tasks, such as regular expressions and Dyck languages. However, it is not obvious how to extend this approach to understand more naturalistic conversational agents. In this work, we take a step in this direction by constructing a Transformer that implements the ELIZA program, a classic, rule-based chatbot. ELIZA illustrates some of the distinctive challenges of the conversational setting, including both local pattern matching and long-term dialog state tracking. We build on constructions from prior work -- in particular, for simulating finite-state automata -- showing how simpler constructions can be composed and extended to give rise to more sophisticated behavior. Next, we train Transformers on a dataset of synthetically generated ELIZA conversations and investigate the mechanisms the models learn. Our analysis illustrates the kinds of mechanisms these models tend to prefer -- for example, models favor an induction head mechanism over a more precise, position based copying mechanism; and using intermediate generations to simulate recurrent data structures, like ELIZA's memory mechanisms. Overall, by drawing an explicit connection between neural chatbots and interpretable, symbolic mechanisms, our results offer a new setting for mechanistic analysis of conversational agents.
Finding Transformer Circuits with Edge Pruning
Jun 24, 2024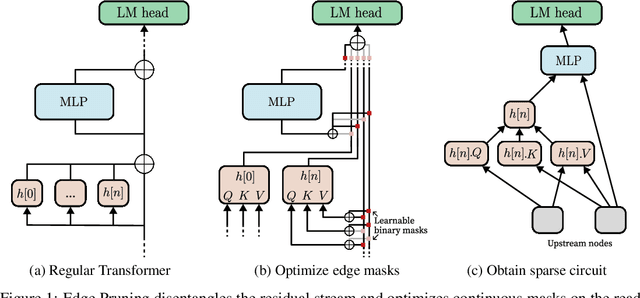
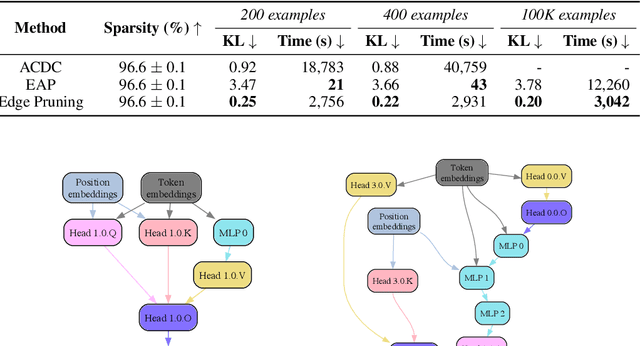
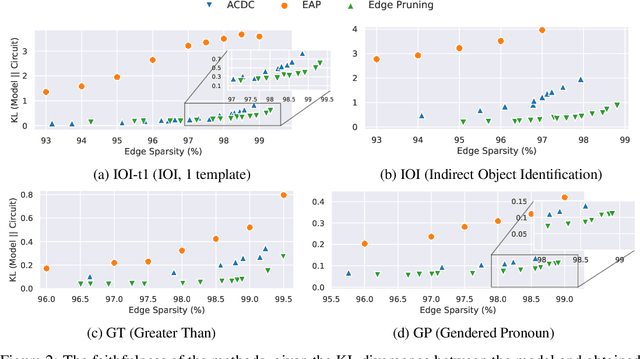
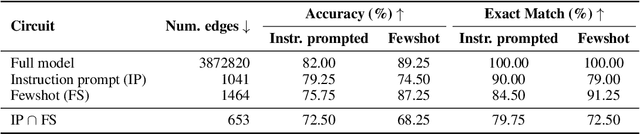
The path to interpreting a language model often proceeds via analysis of circuits -- sparse computational subgraphs of the model that capture specific aspects of its behavior. Recent work has automated the task of discovering circuits. Yet, these methods have practical limitations, as they rely either on inefficient search algorithms or inaccurate approximations. In this paper, we frame automated circuit discovery as an optimization problem and propose *Edge Pruning* as an effective and scalable solution. Edge Pruning leverages gradient-based pruning techniques, but instead of removing neurons or components, it prunes the \emph{edges} between components. Our method finds circuits in GPT-2 that use less than half the number of edges compared to circuits found by previous methods while being equally faithful to the full model predictions on standard circuit-finding tasks. Edge Pruning is efficient even with as many as 100K examples, outperforming previous methods in speed and producing substantially better circuits. It also perfectly recovers the ground-truth circuits in two models compiled with Tracr. Thanks to its efficiency, we scale Edge Pruning to CodeLlama-13B, a model over 100x the scale that prior methods operate on. We use this setting for a case study comparing the mechanisms behind instruction prompting and in-context learning. We find two circuits with more than 99.96% sparsity that match the performance of the full model and reveal that the mechanisms in the two settings overlap substantially. Our case study shows that Edge Pruning is a practical and scalable tool for interpretability and sheds light on behaviors that only emerge in large models.
The Heuristic Core: Understanding Subnetwork Generalization in Pretrained Language Models
Mar 06, 2024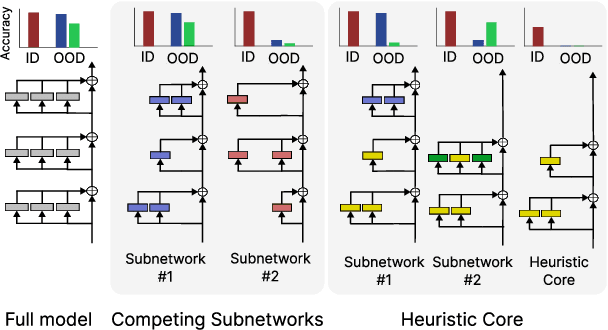


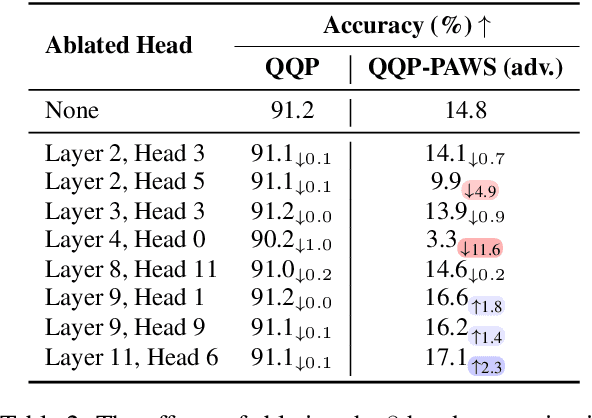
Prior work has found that pretrained language models (LMs) fine-tuned with different random seeds can achieve similar in-domain performance but generalize differently on tests of syntactic generalization. In this work, we show that, even within a single model, we can find multiple subnetworks that perform similarly in-domain, but generalize vastly differently. To better understand these phenomena, we investigate if they can be understood in terms of "competing subnetworks": the model initially represents a variety of distinct algorithms, corresponding to different subnetworks, and generalization occurs when it ultimately converges to one. This explanation has been used to account for generalization in simple algorithmic tasks. Instead of finding competing subnetworks, we find that all subnetworks -- whether they generalize or not -- share a set of attention heads, which we refer to as the heuristic core. Further analysis suggests that these attention heads emerge early in training and compute shallow, non-generalizing features. The model learns to generalize by incorporating additional attention heads, which depend on the outputs of the "heuristic" heads to compute higher-level features. Overall, our results offer a more detailed picture of the mechanisms for syntactic generalization in pretrained LMs.
Interpretability Illusions in the Generalization of Simplified Models
Dec 06, 2023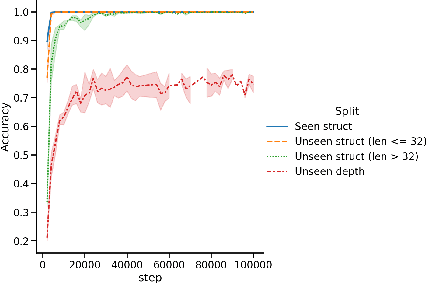
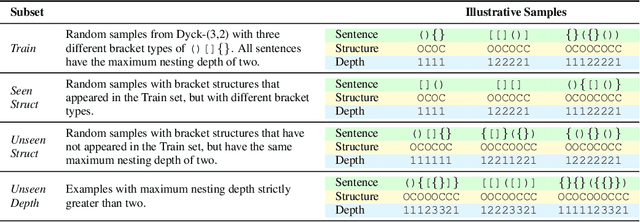
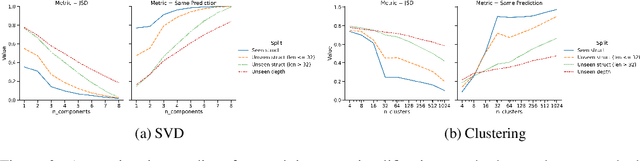

A common method to study deep learning systems is to use simplified model representations -- for example, using singular value decomposition to visualize the model's hidden states in a lower dimensional space. This approach assumes that the results of these simplified are faithful to the original model. Here, we illustrate an important caveat to this assumption: even if the simplified representations can accurately approximate the full model on the training set, they may fail to accurately capture the model's behavior out of distribution -- the understanding developed from simplified representations may be an illusion. We illustrate this by training Transformer models on controlled datasets with systematic generalization splits. First, we train models on the Dyck balanced-parenthesis languages. We simplify these models using tools like dimensionality reduction and clustering, and then explicitly test how these simplified proxies match the behavior of the original model on various out-of-distribution test sets. We find that the simplified proxies are generally less faithful out of distribution. In cases where the original model generalizes to novel structures or deeper depths, the simplified versions may fail, or generalize better. This finding holds even if the simplified representations do not directly depend on the training distribution. Next, we study a more naturalistic task: predicting the next character in a dataset of computer code. We find similar generalization gaps between the original model and simplified proxies, and conduct further analysis to investigate which aspects of the code completion task are associated with the largest gaps. Together, our results raise questions about the extent to which mechanistic interpretations derived using tools like SVD can reliably predict what a model will do in novel situations.
Embers of Autoregression: Understanding Large Language Models Through the Problem They are Trained to Solve
Sep 24, 2023


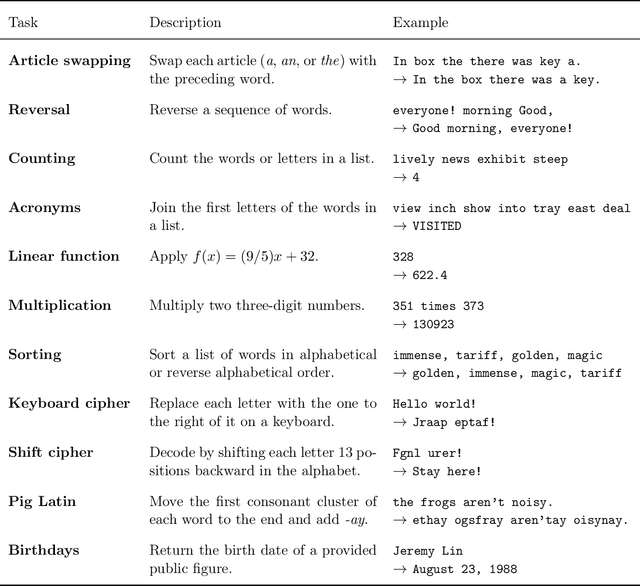
The widespread adoption of large language models (LLMs) makes it important to recognize their strengths and limitations. We argue that in order to develop a holistic understanding of these systems we need to consider the problem that they were trained to solve: next-word prediction over Internet text. By recognizing the pressures that this task exerts we can make predictions about the strategies that LLMs will adopt, allowing us to reason about when they will succeed or fail. This approach - which we call the teleological approach - leads us to identify three factors that we hypothesize will influence LLM accuracy: the probability of the task to be performed, the probability of the target output, and the probability of the provided input. We predict that LLMs will achieve higher accuracy when these probabilities are high than when they are low - even in deterministic settings where probability should not matter. To test our predictions, we evaluate two LLMs (GPT-3.5 and GPT-4) on eleven tasks, and we find robust evidence that LLMs are influenced by probability in the ways that we have hypothesized. In many cases, the experiments reveal surprising failure modes. For instance, GPT-4's accuracy at decoding a simple cipher is 51% when the output is a high-probability word sequence but only 13% when it is low-probability. These results show that AI practitioners should be careful about using LLMs in low-probability situations. More broadly, we conclude that we should not evaluate LLMs as if they are humans but should instead treat them as a distinct type of system - one that has been shaped by its own particular set of pressures.
Learning Transformer Programs
Jun 01, 2023Recent research in mechanistic interpretability has attempted to reverse-engineer Transformer models by carefully inspecting network weights and activations. However, these approaches require considerable manual effort and still fall short of providing complete, faithful descriptions of the underlying algorithms. In this work, we introduce a procedure for training Transformers that are mechanistically interpretable by design. We build on RASP [Weiss et al., 2021], a programming language that can be compiled into Transformer weights. Instead of compiling human-written programs into Transformers, we design a modified Transformer that can be trained using gradient-based optimization and then be automatically converted into a discrete, human-readable program. We refer to these models as Transformer Programs. To validate our approach, we learn Transformer Programs for a variety of problems, including an in-context learning task, a suite of algorithmic problems (e.g. sorting, recognizing Dyck-languages), and NLP tasks including named entity recognition and text classification. The Transformer Programs can automatically find reasonable solutions, performing on par with standard Transformers of comparable size; and, more importantly, they are easy to interpret. To demonstrate these advantages, we convert Transformers into Python programs and use off-the-shelf code analysis tools to debug model errors and identify the ``circuits'' used to solve different sub-problems. We hope that Transformer Programs open a new path toward the goal of intrinsically interpretable machine learning.
Measuring Inductive Biases of In-Context Learning with Underspecified Demonstrations
May 22, 2023



In-context learning (ICL) is an important paradigm for adapting large language models (LLMs) to new tasks, but the generalization behavior of ICL remains poorly understood. We investigate the inductive biases of ICL from the perspective of feature bias: which feature ICL is more likely to use given a set of underspecified demonstrations in which two features are equally predictive of the labels. First, we characterize the feature biases of GPT-3 models by constructing underspecified demonstrations from a range of NLP datasets and feature combinations. We find that LLMs exhibit clear feature biases - for example, demonstrating a strong bias to predict labels according to sentiment rather than shallow lexical features, like punctuation. Second, we evaluate the effect of different interventions that are designed to impose an inductive bias in favor of a particular feature, such as adding a natural language instruction or using semantically relevant label words. We find that, while many interventions can influence the learner to prefer a particular feature, it can be difficult to overcome strong prior biases. Overall, our results provide a broader picture of the types of features that ICL may be more likely to exploit and how to impose inductive biases that are better aligned with the intended task.