 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Vendi Score: A Diversity Evaluation Metric for Machine Learning
Paper and Code
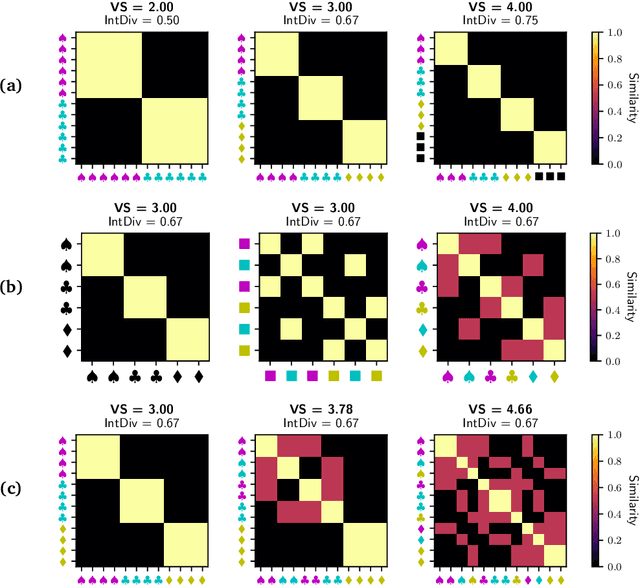
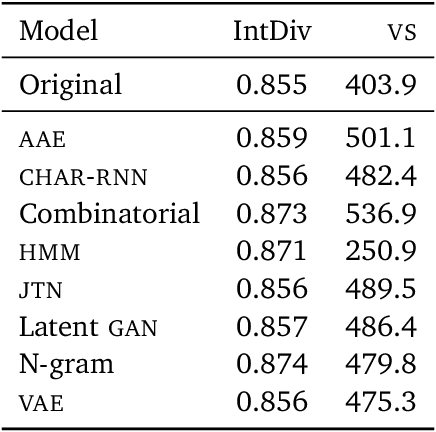
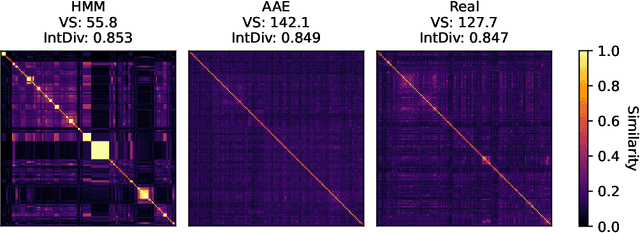
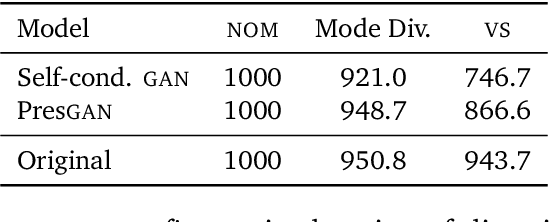
Diversity is an important criterion for many areas of machine learning (ML), including generative modeling and dataset curation. Yet little work has gone into understanding, formalizing, and measuring diversity in ML. In this paper, we address the diversity evaluation problem by proposing the Vendi Score, which connects and extends ideas from ecology and quantum statistical mechanics to ML. The Vendi Score is defined as the exponential of the Shannon entropy of the eigenvalues of a similarity matrix. This matrix is induced by a user-defined similarity function applied to the sample to be evaluated for diversity. In taking a similarity function as input, the Vendi Score enables its user to specify any desired form of diversity. Importantly, unlike many existing metrics in ML, the Vendi Score doesn't require a reference dataset or distribution over samples or labels, it is therefore general and applicable to any generative model, decoding algorithm, and dataset from any domain where similarity can be defined. We showcased the Vendi Score on molecular generative modeling, a domain where diversity plays an important role in enabling the discovery of novel molecules. We found that the Vendi Score addresses shortcomings of the current diversity metric of choice in that domain. We also applied the Vendi Score to generative models of images and decoding algorithms of text and found it confirms known results about diversity in those domains. Furthermore, we used the Vendi Score to measure mode collapse, a known limitation of generative adversarial networks (GANs). In particular, the Vendi Score revealed that even GANs that capture all the modes of a labeled dataset can be less diverse than the original dataset. Finally, the interpretability of the Vendi Score allowed us to diagnose several benchmark ML datasets for diversity, opening the door for diversity-informed data augmentation.