 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretability Illusions in the Generalization of Simplified Models
Paper and Code
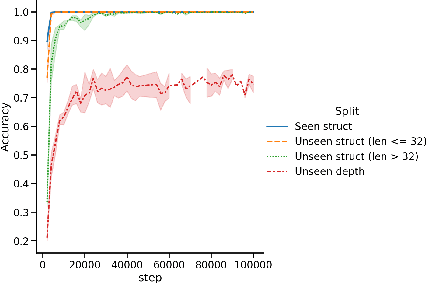
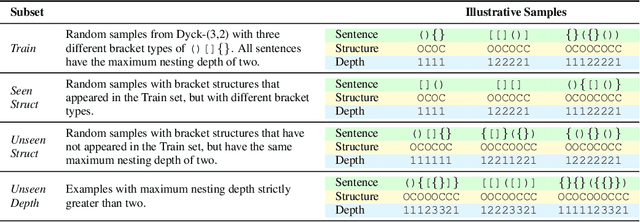
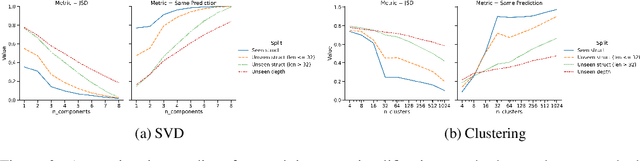

A common method to study deep learning systems is to use simplified model representations -- for example, using singular value decomposition to visualize the model's hidden states in a lower dimensional space. This approach assumes that the results of these simplified are faithful to the original model. Here, we illustrate an important caveat to this assumption: even if the simplified representations can accurately approximate the full model on the training set, they may fail to accurately capture the model's behavior out of distribution -- the understanding developed from simplified representations may be an illusion. We illustrate this by training Transformer models on controlled datasets with systematic generalization splits. First, we train models on the Dyck balanced-parenthesis languages. We simplify these models using tools like dimensionality reduction and clustering, and then explicitly test how these simplified proxies match the behavior of the original model on various out-of-distribution test sets. We find that the simplified proxies are generally less faithful out of distribution. In cases where the original model generalizes to novel structures or deeper depths, the simplified versions may fail, or generalize better. This finding holds even if the simplified representations do not directly depend on the training distribution. Next, we study a more naturalistic task: predicting the next character in a dataset of computer code. We find similar generalization gaps between the original model and simplified proxies, and conduct further analysis to investigate which aspects of the code completion task are associated with the largest gaps. Together, our results raise questions about the extent to which mechanistic interpretations derived using tools like SVD can reliably predict what a model will do in novel situations.