 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Latent Generalization Using Test-time Compute
Apr 01, 2026Language Models (LMs) exhibit two distinct mechanisms for knowledge acquisition: in-weights learning (i.e., encoding information within the model weights) and in-context learning (ICL). Although these two modes offer complementary strengths, in-weights learning frequently struggles to facilitate deductive reasoning over the internalized knowledge. We characterize this limitation as a deficit in latent generalization, of which the reversal curse is one example. Conversely, in-context learning demonstrates highly robust latent generalization capabilities. To improve latent generalization from in-weights knowledge, prior approaches rely on train-time data augmentation, yet these techniques are task-specific, scale poorly, and fail to generalize to out-of-distribution knowledge. To overcome these shortcomings, this work studies how models can be taught to use test-time compute, or 'thinking', specifically to improve latent generalization. We use Reinforcement Learning (RL) from correctness feedback to train models to produce long chains-of-thought (CoTs) to improve latent generalization. Our experiments show that this thinking approach not only resolves many instances of latent generalization failures on in-distribution knowledge but also, unlike augmentation baselines, generalizes to new knowledge for which no RL was performed. Nevertheless, on pure reversal tasks, we find that thinking does not unlock direct knowledge inversion, but the generate-and-verify ability of thinking models enables them to get well above chance performance. The brittleness of factual self-verification means thinking models still remain well below the performance of in-context learning for this task. Overall, our results establish test-time thinking as a flexible and promising direction for improving the latent generalization of LMs.
How do language models learn facts? Dynamics, curricula and hallucinations
Mar 27, 2025



Large language models accumulate vast knowledge during pre-training, yet the dynamics governing this acquisition remain poorly understood. This work investigates the learning dynamics of language models on a synthetic factual recall task, uncovering three key findings: First, language models learn in three phases, exhibiting a performance plateau before acquiring precise factual knowledge. Mechanistically, this plateau coincides with the formation of attention-based circuits that support recall. Second, the training data distribution significantly impacts learning dynamics, as imbalanced distributions lead to shorter plateaus. Finally, hallucinations emerge simultaneously with knowledge, and integrating new knowledge into the model through fine-tuning is challenging, as it quickly corrupts its existing parametric memories. Our results emphasize the importance of data distribution in knowledge acquisition and suggest novel data scheduling strategies to accelerate neural network training.
Naturalistic Computational Cognitive Science: Towards generalizable models and theories that capture the full range of natural behavior
Feb 27, 2025Artificial Intelligence increasingly pursues large, complex models that perform many tasks within increasingly realistic domains. How, if at all, should these developments in AI influence cognitive science? We argue that progress in AI offers timely opportunities for cognitive science to embrace experiments with increasingly naturalistic stimuli, tasks, and behaviors; and computational models that can accommodate these changes. We first review a growing body of research spanning neuroscience, cognitive science, and AI that suggests that incorporating a broader range of naturalistic experimental paradigms (and models that accommodate them) may be necessary to resolve some aspects of natural intelligence and ensure that our theories generalize. We then suggest that integrating recent progress in AI and cognitive science will enable us to engage with more naturalistic phenomena without giving up experimental control or the pursuit of theoretically grounded understanding. We offer practical guidance on how methodological practices can contribute to cumulative progress in naturalistic computational cognitive science, and illustrate a path towards building computational models that solve the real problems of natural cognition - together with a reductive understanding of the processes and principles by which they do so.
Interpretability Illusions in the Generalization of Simplified Models
Dec 06, 2023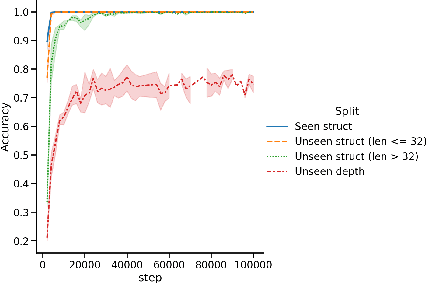
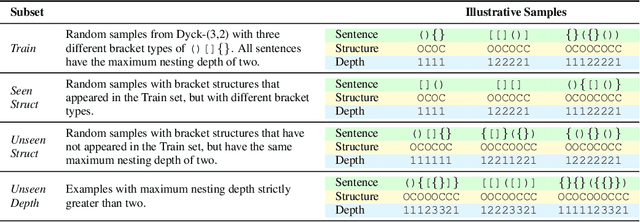
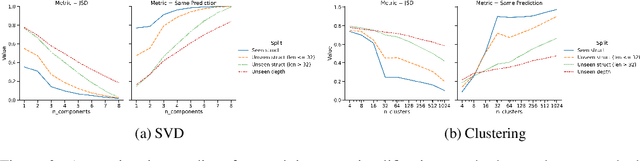

A common method to study deep learning systems is to use simplified model representations -- for example, using singular value decomposition to visualize the model's hidden states in a lower dimensional space. This approach assumes that the results of these simplified are faithful to the original model. Here, we illustrate an important caveat to this assumption: even if the simplified representations can accurately approximate the full model on the training set, they may fail to accurately capture the model's behavior out of distribution -- the understanding developed from simplified representations may be an illusion. We illustrate this by training Transformer models on controlled datasets with systematic generalization splits. First, we train models on the Dyck balanced-parenthesis languages. We simplify these models using tools like dimensionality reduction and clustering, and then explicitly test how these simplified proxies match the behavior of the original model on various out-of-distribution test sets. We find that the simplified proxies are generally less faithful out of distribution. In cases where the original model generalizes to novel structures or deeper depths, the simplified versions may fail, or generalize better. This finding holds even if the simplified representations do not directly depend on the training distribution. Next, we study a more naturalistic task: predicting the next character in a dataset of computer code. We find similar generalization gaps between the original model and simplified proxies, and conduct further analysis to investigate which aspects of the code completion task are associated with the largest gaps. Together, our results raise questions about the extent to which mechanistic interpretations derived using tools like SVD can reliably predict what a model will do in novel situations.
Symbol tuning improves in-context learning in language models
May 15, 2023



We present symbol tuning - finetuning language models on in-context input-label pairs where natural language labels (e.g., "positive/negative sentiment") are replaced with arbitrary symbols (e.g., "foo/bar"). Symbol tuning leverages the intuition that when a model cannot use instructions or natural language labels to figure out a task, it must instead do so by learning the input-label mappings. We experiment with symbol tuning across Flan-PaLM models up to 540B parameters and observe benefits across various settings. First, symbol tuning boosts performance on unseen in-context learning tasks and is much more robust to underspecified prompts, such as those without instructions or without natural language labels. Second, symbol-tuned models are much stronger at algorithmic reasoning tasks, with up to 18.2% better performance on the List Functions benchmark and up to 15.3% better performance on the Simple Turing Concepts benchmark. Finally, symbol-tuned models show large improvements in following flipped-labels presented in-context, meaning that they are more capable of using in-context information to override prior semantic knowledge.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
Feature-Attending Recurrent Modules for Generalization in Reinforcement Learning
Dec 15, 2021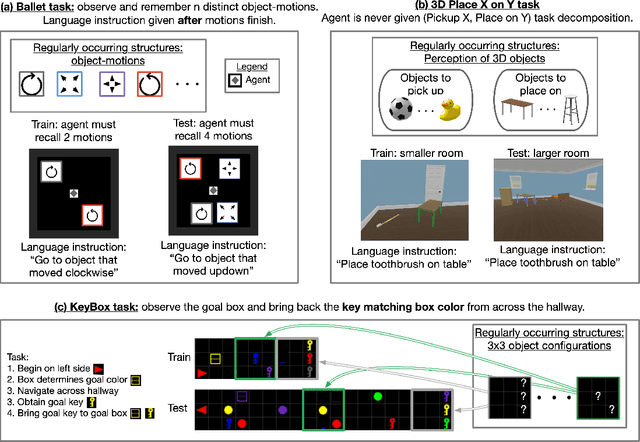
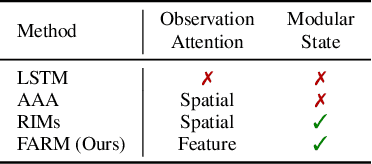
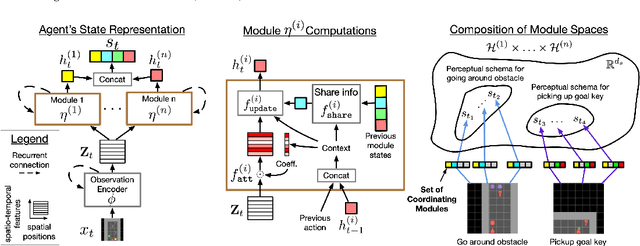
Deep reinforcement learning (Deep RL) has recently seen significant progress in developing algorithms for generalization. However, most algorithms target a single type of generalization setting. In this work, we study generalization across three disparate task structures: (a) tasks composed of spatial and temporal compositions of regularly occurring object motions; (b) tasks composed of active perception of and navigation towards regularly occurring 3D objects; and (c) tasks composed of remembering goal-information over sequences of regularly occurring object-configurations. These diverse task structures all share an underlying idea of compositionality: task completion always involves combining recurring segments of task-oriented perception and behavior. We hypothesize that an agent can generalize within a task structure if it can discover representations that capture these recurring task-segments. For our tasks, this corresponds to representations for recognizing individual object motions, for navigation towards 3D objects, and for navigating through object-configurations. Taking inspiration from cognitive science, we term representations for recurring segments of an agent's experience, "perceptual schemas". We propose Feature Attending Recurrent Modules (FARM), which learns a state representation where perceptual schemas are distributed across multiple, relatively small recurrent modules. We compare FARM to recurrent architectures that leverage spatial attention, which reduces observation features to a weighted average over spatial positions. Our experiments indicate that our feature-attention mechanism better enables FARM to generalize across the diverse object-centric domains we study.
Symbolic Behaviour in Artificial Intelligence
Feb 05, 2021The ability to use symbols is the pinnacle of human intelligence, but has yet to be fully replicated in machines. Here we argue that the path towards symbolically fluent artificial intelligence (AI) begins with a reinterpretation of what symbols are, how they come to exist, and how a system behaves when it uses them. We begin by offering an interpretation of symbols as entities whose meaning is established by convention. But crucially, something is a symbol only for those who demonstrably and actively participate in this convention. We then outline how this interpretation thematically unifies the behavioural traits humans exhibit when they use symbols. This motivates our proposal that the field place a greater emphasis on symbolic behaviour rather than particular computational mechanisms inspired by more restrictive interpretations of symbols. Finally, we suggest that AI research explore social and cultural engagement as a tool to develop the cognitive machinery necessary for symbolic behaviour to emerge. This approach will allow for AI to interpret something as symbolic on its own rather than simply manipulate things that are only symbols to human onlookers, and thus will ultimately lead to AI with more human-like symbolic fluency.
Emergent Systematic Generalization in a Situated Agent
Oct 28, 2019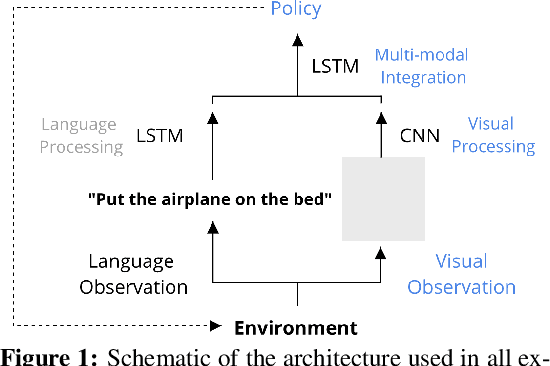
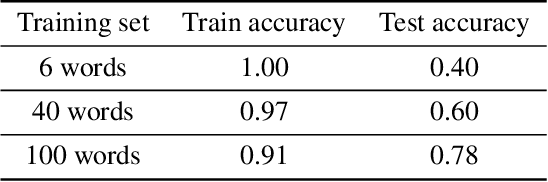
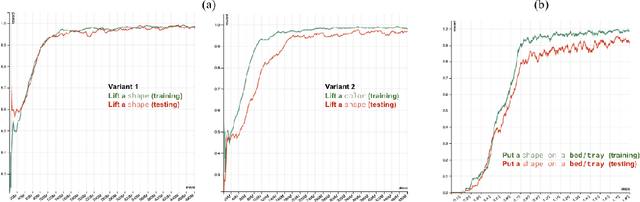
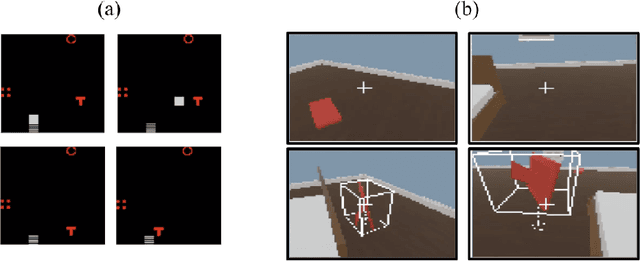
The question of whether deep neural networks are good at generalising beyond their immediate training experience is of critical importance for learning-based approaches to AI. Here, we demonstrate strong emergent systematic generalisation in a neural network agent and isolate the factors that support this ability. In environments ranging from a grid-world to a rich interactive 3D Unity room, we show that an agent can correctly exploit the compositional nature of a symbolic language to interpret never-seen-before instructions. We observe this capacity not only when instructions refer to object properties (colors and shapes) but also verb-like motor skills (lifting and putting) and abstract modifying operations (negation). We identify three factors that can contribute to this facility for systematic generalisation: (a) the number of object/word experiences in the training set; (b) the invariances afforded by a first-person, egocentric perspective; and (c) the variety of visual input experienced by an agent that perceives the world actively over time. Thus, while neural nets trained in idealised or reduced situations may fail to exhibit a compositional or systematic understanding of their experience, this competence can readily emerge when, like human learners, they have access to many examples of richly varying, multi-modal observations as they learn.