 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe emergence of sparse attention: impact of data distribution and benefits of repetition
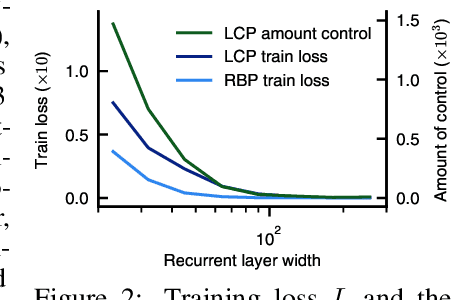
May 23, 2025Emergence is a fascinating property of large language models and neural networks more broadly: as models scale and train for longer, they sometimes develop new abilities in sudden ways. Despite initial studies, we still lack a comprehensive understanding of how and when these abilities emerge. To address this gap, we study the emergence over training of sparse attention, a critical and frequently observed attention pattern in Transformers. By combining theoretical analysis of a toy model with empirical observations on small Transformers trained on a linear regression variant, we uncover the mechanics driving sparse attention emergence and reveal that emergence timing follows power laws based on task structure, architecture, and optimizer choice. We additionally find that repetition can greatly speed up emergence. Finally, we confirm these results on a well-studied in-context associative recall task. Our findings provide a simple, theoretically grounded framework for understanding how data distributions and model design influence the learning dynamics behind one form of emergence.
How do language models learn facts? Dynamics, curricula and hallucinations
Mar 27, 2025Large language models accumulate vast knowledge during pre-training, yet the dynamics governing this acquisition remain poorly understood. This work investigates the learning dynamics of language models on a synthetic factual recall task, uncovering three key findings: First, language models learn in three phases, exhibiting a performance plateau before acquiring precise factual knowledge. Mechanistically, this plateau coincides with the formation of attention-based circuits that support recall. Second, the training data distribution significantly impacts learning dynamics, as imbalanced distributions lead to shorter plateaus. Finally, hallucinations emerge simultaneously with knowledge, and integrating new knowledge into the model through fine-tuning is challenging, as it quickly corrupts its existing parametric memories. Our results emphasize the importance of data distribution in knowledge acquisition and suggest novel data scheduling strategies to accelerate neural network training.
Recurrent neural networks: vanishing and exploding gradients are not the end of the story
May 31, 2024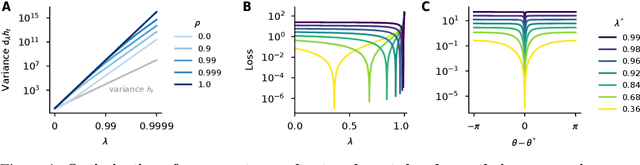

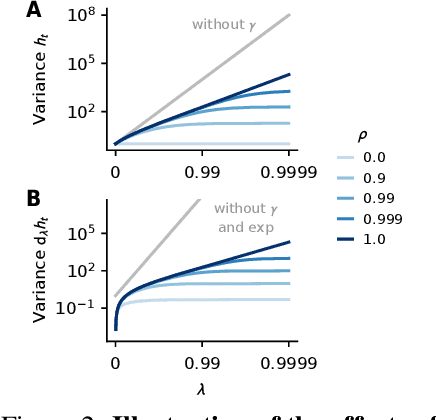
Recurrent neural networks (RNNs) notoriously struggle to learn long-term memories, primarily due to vanishing and exploding gradients. The recent success of state-space models (SSMs), a subclass of RNNs, to overcome such difficulties challenges our theoretical understanding. In this paper, we delve into the optimization challenges of RNNs and discover that, as the memory of a network increases, changes in its parameters result in increasingly large output variations, making gradient-based learning highly sensitive, even without exploding gradients. Our analysis further reveals the importance of the element-wise recurrence design pattern combined with careful parametrizations in mitigating this effect. This feature is present in SSMs, as well as in other architectures, such as LSTMs. Overall, our insights provide a new explanation for some of the difficulties in gradient-based learning of RNNs and why some architectures perform better than others.
Uncovering mesa-optimization algorithms in Transformers
Sep 11, 2023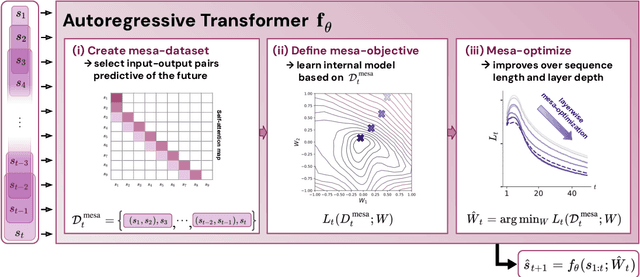
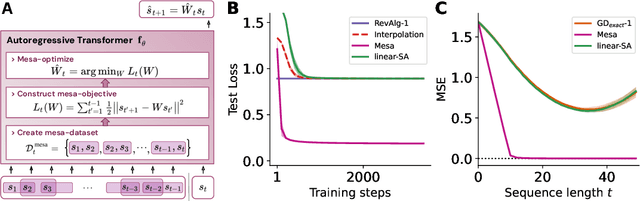
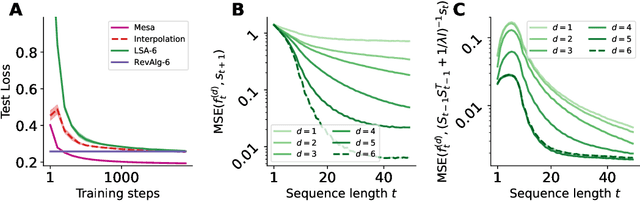
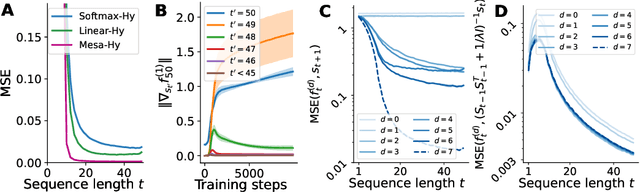
Transformers have become the dominant model in deep learning, but the reason for their superior performance is poorly understood. Here, we hypothesize that the strong performance of Transformers stems from an architectural bias towards mesa-optimization, a learned process running within the forward pass of a model consisting of the following two steps: (i) the construction of an internal learning objective, and (ii) its corresponding solution found through optimization. To test this hypothesis, we reverse-engineer a series of autoregressive Transformers trained on simple sequence modeling tasks, uncovering underlying gradient-based mesa-optimization algorithms driving the generation of predictions. Moreover, we show that the learned forward-pass optimization algorithm can be immediately repurposed to solve supervised few-shot tasks, suggesting that mesa-optimization might underlie the in-context learning capabilities of large language models. Finally, we propose a novel self-attention layer, the mesa-layer, that explicitly and efficiently solves optimization problems specified in context. We find that this layer can lead to improved performance in synthetic and preliminary language modeling experiments, adding weight to our hypothesis that mesa-optimization is an important operation hidden within the weights of trained Transformers.
Gated recurrent neural networks discover attention
Sep 04, 2023Recent architectural developments have enabled recurrent neural networks (RNNs) to reach and even surpass the performance of Transformers on certain sequence modeling tasks. These modern RNNs feature a prominent design pattern: linear recurrent layers interconnected by feedforward paths with multiplicative gating. Here, we show how RNNs equipped with these two design elements can exactly implement (linear) self-attention, the main building block of Transformers. By reverse-engineering a set of trained RNNs, we find that gradient descent in practice discovers our construction. In particular, we examine RNNs trained to solve simple in-context learning tasks on which Transformers are known to excel and find that gradient descent instills in our RNNs the same attention-based in-context learning algorithm used by Transformers. Our findings highlight the importance of multiplicative interactions in neural networks and suggest that certain RNNs might be unexpectedly implementing attention under the hood.
Online learning of long-range dependencies
May 25, 2023Online learning holds the promise of enabling efficient long-term credit assignment in recurrent neural networks. However, current algorithms fall short of offline backpropagation by either not being scalable or failing to learn long-range dependencies. Here we present a high-performance online learning algorithm that merely doubles the memory and computational requirements of a single inference pass. We achieve this by leveraging independent recurrent modules in multi-layer networks, an architectural motif that has recently been shown to be particularly powerful. Experiments on synthetic memory problems and on the challenging long-range arena benchmark suite reveal that our algorithm performs competitively, establishing a new standard for what can be achieved through online learning. This ability to learn long-range dependencies offers a new perspective on learning in the brain and opens a promising avenue in neuromorphic computing.
Random initialisations performing above chance and how to find them
Sep 15, 2022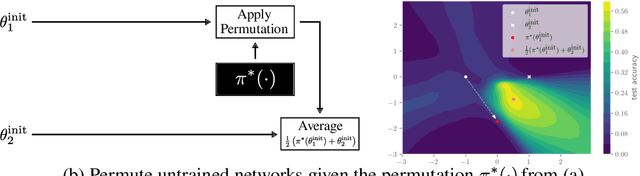
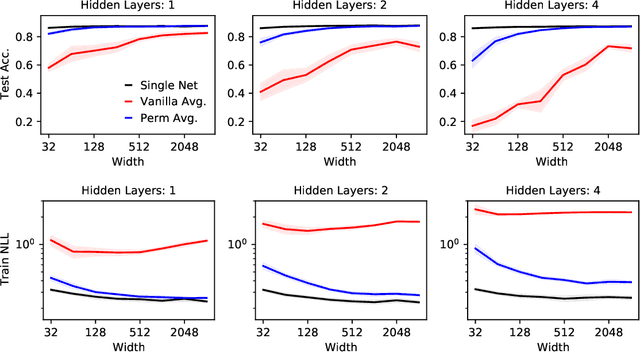
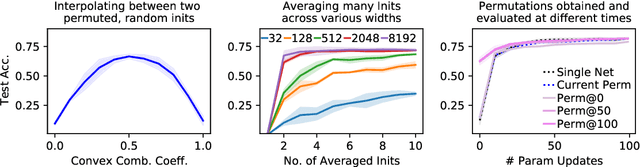
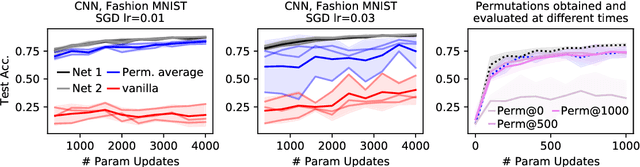
Neural networks trained with stochastic gradient descent (SGD) starting from different random initialisations typically find functionally very similar solutions, raising the question of whether there are meaningful differences between different SGD solutions. Entezari et al. recently conjectured that despite different initialisations, the solutions found by SGD lie in the same loss valley after taking into account the permutation invariance of neural networks. Concretely, they hypothesise that any two solutions found by SGD can be permuted such that the linear interpolation between their parameters forms a path without significant increases in loss. Here, we use a simple but powerful algorithm to find such permutations that allows us to obtain direct empirical evidence that the hypothesis is true in fully connected networks. Strikingly, we find that two networks already live in the same loss valley at the time of initialisation and averaging their random, but suitably permuted initialisation performs significantly above chance. In contrast, for convolutional architectures, our evidence suggests that the hypothesis does not hold. Especially in a large learning rate regime, SGD seems to discover diverse modes.
The least-control principle for learning at equilibrium
Jul 04, 2022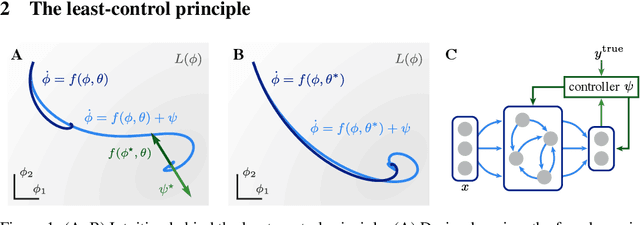


Equilibrium systems are a powerful way to express neural computations. As special cases, they include models of great current interest in both neuroscience and machine learning, such as equilibrium recurrent neural networks, deep equilibrium models, or meta-learning. Here, we present a new principle for learning such systems with a temporally- and spatially-local rule. Our principle casts learning as a least-control problem, where we first introduce an optimal controller to lead the system towards a solution state, and then define learning as reducing the amount of control needed to reach such a state. We show that incorporating learning signals within a dynamics as an optimal control enables transmitting credit assignment information in previously unknown ways, avoids storing intermediate states in memory, and does not rely on infinitesimal learning signals. In practice, our principle leads to strong performance matching that of leading gradient-based learning methods when applied to an array of problems involving recurrent neural networks and meta-learning. Our results shed light on how the brain might learn and offer new ways of approaching a broad class of machine learning problems.
Beyond backpropagation: implicit gradients for bilevel optimization
May 06, 2022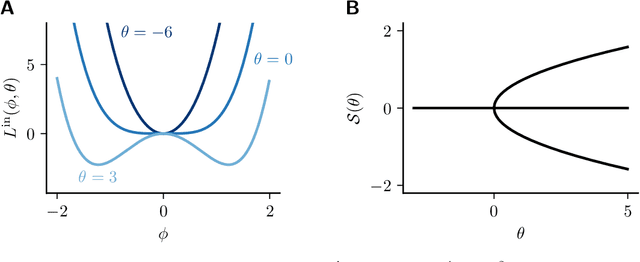
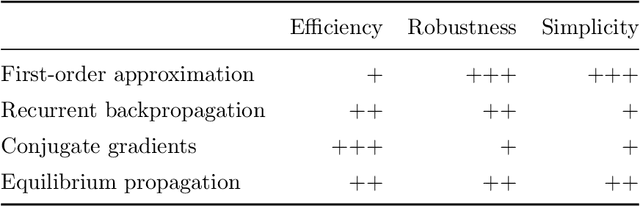
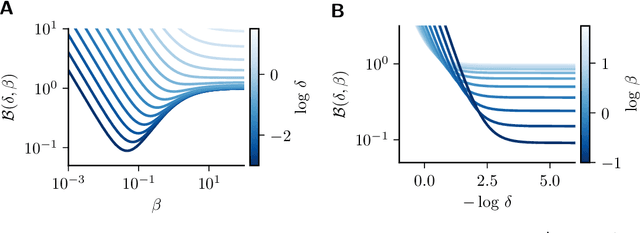
This paper reviews gradient-based techniques to solve bilevel optimization problems. Bilevel optimization is a general way to frame the learning of systems that are implicitly defined through a quantity that they minimize. This characterization can be applied to neural networks, optimizers, algorithmic solvers and even physical systems, and allows for greater modeling flexibility compared to an explicit definition of such systems. Here we focus on gradient-based approaches that solve such problems. We distinguish them in two categories: those rooted in implicit differentiation, and those that leverage the equilibrium propagation theorem. We present the mathematical foundations that are behind such methods, introduce the gradient-estimation algorithms in detail and compare the competitive advantages of the different approaches.
Learning where to learn: Gradient sparsity in meta and continual learning
Oct 27, 2021
Finding neural network weights that generalize well from small datasets is difficult. A promising approach is to learn a weight initialization such that a small number of weight changes results in low generalization error. We show that this form of meta-learning can be improved by letting the learning algorithm decide which weights to change, i.e., by learning where to learn. We find that patterned sparsity emerges from this process, with the pattern of sparsity varying on a problem-by-problem basis. This selective sparsity results in better generalization and less interference in a range of few-shot and continual learning problems. Moreover, we find that sparse learning also emerges in a more expressive model where learning rates are meta-learned. Our results shed light on an ongoing debate on whether meta-learning can discover adaptable features and suggest that learning by sparse gradient descent is a powerful inductive bias for meta-learning systems.