 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Attention Encoder Decoder
Jun 01, 2023Recent advances in large language models have shown that autoregressive modeling can generate complex and novel sequences that have many real-world applications. However, these models must generate outputs autoregressively, which becomes time-consuming when dealing with long sequences. Hierarchical autoregressive approaches that compress data have been proposed as a solution, but these methods still generate outputs at the original data frequency, resulting in slow and memory-intensive models. In this paper, we propose a model based on the Hierarchical Recurrent Encoder Decoder (HRED) architecture. This model independently encodes input sub-sequences without global context, processes these sequences using a lower-frequency model, and decodes outputs at the original data frequency. By interpreting the encoder as an implicitly defined embedding matrix and using sampled softmax estimation, we develop a training algorithm that can train the entire model without a high-frequency decoder, which is the most memory and compute-intensive part of hierarchical approaches. In a final, brief phase, we train the decoder to generate data at the original granularity. Our algorithm significantly reduces memory requirements for training autoregressive models and it also improves the total training wall-clock time.
Online learning of long-range dependencies
May 25, 2023Online learning holds the promise of enabling efficient long-term credit assignment in recurrent neural networks. However, current algorithms fall short of offline backpropagation by either not being scalable or failing to learn long-range dependencies. Here we present a high-performance online learning algorithm that merely doubles the memory and computational requirements of a single inference pass. We achieve this by leveraging independent recurrent modules in multi-layer networks, an architectural motif that has recently been shown to be particularly powerful. Experiments on synthetic memory problems and on the challenging long-range arena benchmark suite reveal that our algorithm performs competitively, establishing a new standard for what can be achieved through online learning. This ability to learn long-range dependencies offers a new perspective on learning in the brain and opens a promising avenue in neuromorphic computing.
Open-Ended Reinforcement Learning with Neural Reward Functions
Feb 16, 2022
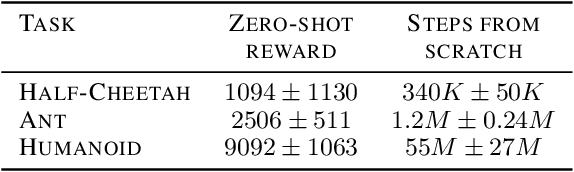


Inspired by the great success of unsupervised learning in Computer Vision and Natural Language Processing, the Reinforcement Learning community has recently started to focus more on unsupervised discovery of skills. Most current approaches, like DIAYN or DADS, optimize some form of mutual information objective. We propose a different approach that uses reward functions encoded by neural networks. These are trained iteratively to reward more complex behavior. In high-dimensional robotic environments our approach learns a wide range of interesting skills including front-flips for Half-Cheetah and one-legged running for Humanoid. In the pixel-based Montezuma's Revenge environment our method also works with minimal changes and it learns complex skills that involve interacting with items and visiting diverse locations. A web version of this paper which shows animations for the different skills is available in https://as.inf.ethz.ch/research/open_ended_RL/main.html
Improving Gradient Estimation in Evolutionary Strategies With Past Descent Directions
Oct 11, 2019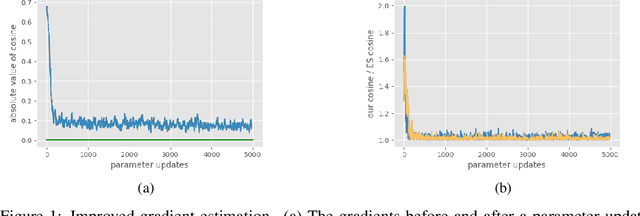

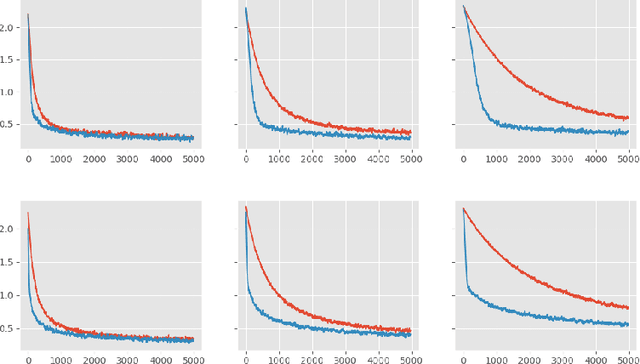
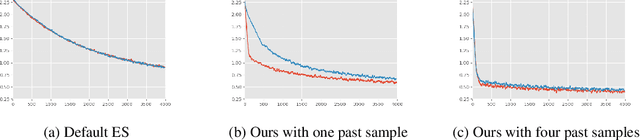
Evolutionary Strategies (ES) are known to be an effective black-box optimization technique for deep neural networks when the true gradients cannot be computed, such as in Reinforcement Learning. We continue a recent line of research that uses surrogate gradients to improve the gradient estimation of ES. We propose a novel method to optimally incorporate surrogate gradient information. Our approach, unlike previous work, needs no information about the quality of the surrogate gradients and is always guaranteed to find a descent direction that is better than the surrogate gradient. This allows to iteratively use the previous gradient estimate as surrogate gradient for the current search point. We theoretically prove that this yields fast convergence to the true gradient for linear functions and show under simplifying assumptions that it significantly improves gradient estimates for general functions. Finally, we evaluate our approach empirically on MNIST and reinforcement learning tasks and show that it considerably improves the gradient estimation of ES at no extra computational cost.
Decoupling Hierarchical Recurrent Neural Networks With Locally Computable Losses
Oct 11, 2019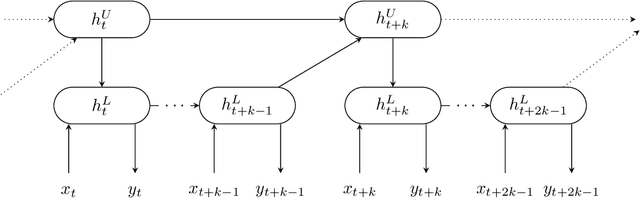
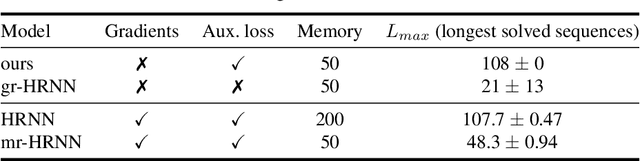
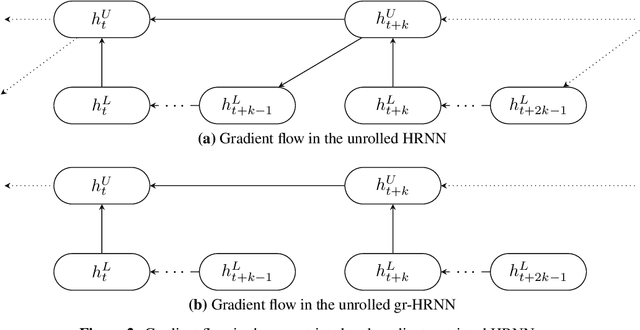
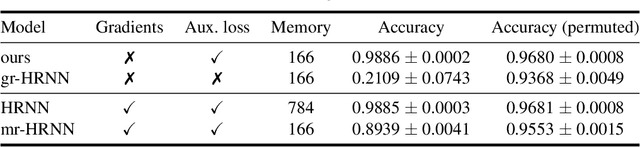
Learning long-term dependencies is a key long-standing challenge of recurrent neural networks (RNNs). Hierarchical recurrent neural networks (HRNNs) have been considered a promising approach as long-term dependencies are resolved through shortcuts up and down the hierarchy. Yet, the memory requirements of Truncated Backpropagation Through Time (TBPTT) still prevent training them on very long sequences. In this paper, we empirically show that in (deep) HRNNs, propagating gradients back from higher to lower levels can be replaced by locally computable losses, without harming the learning capability of the network, over a wide range of tasks. This decoupling by local losses reduces the memory requirements of training by a factor exponential in the depth of the hierarchy in comparison to standard TBPTT.
Optimal Kronecker-Sum Approximation of Real Time Recurrent Learning
Feb 11, 2019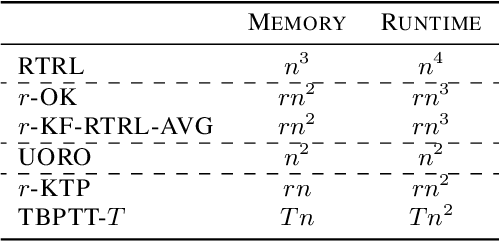
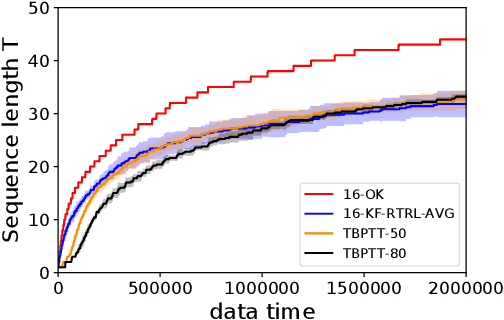
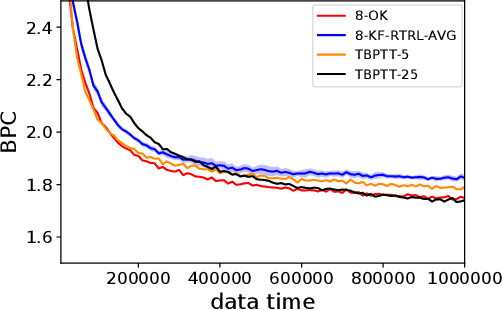

One of the central goals of Recurrent Neural Networks (RNNs) is to learn long-term dependencies in sequential data. Nevertheless, the most popular training method, Truncated Backpropagation through Time (TBPTT), categorically forbids learning dependencies beyond the truncation horizon. In contrast, the online training algorithm Real Time Recurrent Learning (RTRL) provides untruncated gradients, with the disadvantage of impractically large computational costs. Recently published approaches reduce these costs by providing noisy approximations of RTRL. We present a new approximation algorithm of RTRL, Optimal Kronecker-Sum Approximation (OK). We prove that OK is optimal for a class of approximations of RTRL, which includes all approaches published so far. Additionally, we show that OK has empirically negligible noise: Unlike previous algorithms it matches TBPTT in a real world task (character-level Penn TreeBank) and can exploit online parameter updates to outperform TBPTT in a synthetic string memorization task.
The linear hidden subset problem for the EA with scheduled and adaptive mutation rates
Aug 16, 2018We study unbiased $(1+1)$ evolutionary algorithms on linear functions with an unknown number $n$ of bits with non-zero weight. Static algorithms achieve an optimal runtime of $O(n (\ln n)^{2+\epsilon})$, however, it remained unclear whether more dynamic parameter policies could yield better runtime guarantees. We consider two setups: one where the mutation rate follows a fixed schedule, and one where it may be adapted depending on the history of the run. For the first setup, we give a schedule that achieves a runtime of $(1\pm o(1))\beta n \ln n$, where $\beta \approx 3.552$, which is an asymptotic improvement over the runtime of the static setup. Moreover, we show that no schedule admits a better runtime guarantee and that the optimal schedule is essentially unique. For the second setup, we show that the runtime can be further improved to $(1\pm o(1)) e n \ln n$, which matches the performance of algorithms that know $n$ in advance. Finally, we study the related model of initial segment uncertainty with static position-dependent mutation rates, and derive asymptotically optimal lower bounds. This answers a question by Doerr, Doerr, and K\"otzing.
Approximating Real-Time Recurrent Learning with Random Kronecker Factors
May 28, 2018



Despite all the impressive advances of recurrent neural networks, sequential data is still in need of better modelling. Truncated backpropagation through time (TBPTT), the learning algorithm most widely used in practice, suffers from the truncation bias, which drastically limits its ability to learn long-term dependencies.The Real-Time Recurrent Learning algorithm (RTRL) addresses this issue, but its high computational requirements make it infeasible in practice. The Unbiased Online Recurrent Optimization algorithm (UORO) approximates RTRL with a smaller runtime and memory cost, but with the disadvantage of obtaining noisy gradients that also limit its practical applicability. In this paper we propose the Kronecker Factored RTRL (KF-RTRL) algorithm that uses a Kronecker product decomposition to approximate the gradients for a large class of RNNs. We show that KF-RTRL is an unbiased and memory efficient online learning algorithm. Our theoretical analysis shows that, under reasonable assumptions, the noise introduced by our algorithm is not only stable over time but also asymptotically much smaller than the one of the UORO algorithm. We also confirm these theoretical results experimentally. Further, we show empirically that the KF-RTRL algorithm captures long-term dependencies and almost matches the performance of TBPTT on real world tasks by training Recurrent Highway Networks on a synthetic string memorization task and on the Penn TreeBank task, respectively. These results indicate that RTRL based approaches might be a promising future alternative to TBPTT.
Fast-Slow Recurrent Neural Networks
Jun 09, 2017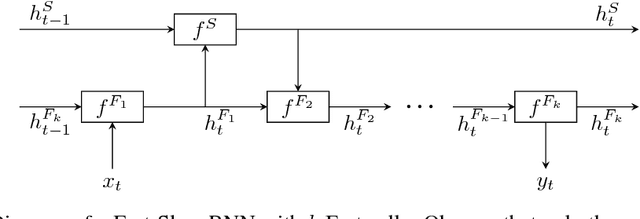
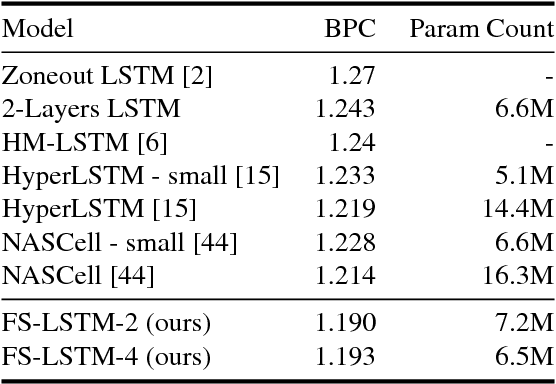
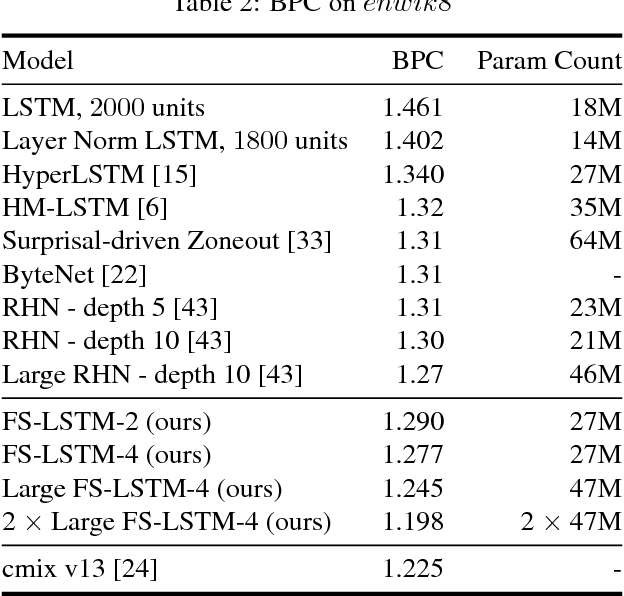
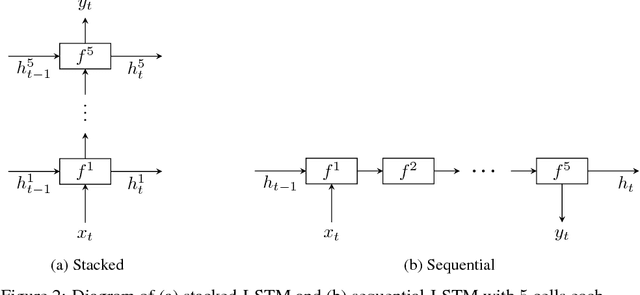
Processing sequential data of variable length is a major challenge in a wide range of applications, such as speech recognition, language modeling, generative image modeling and machine translation. Here, we address this challenge by proposing a novel recurrent neural network (RNN) architecture, the Fast-Slow RNN (FS-RNN). The FS-RNN incorporates the strengths of both multiscale RNNs and deep transition RNNs as it processes sequential data on different timescales and learns complex transition functions from one time step to the next. We evaluate the FS-RNN on two character level language modeling data sets, Penn Treebank and Hutter Prize Wikipedia, where we improve state of the art results to $1.19$ and $1.25$ bits-per-character (BPC), respectively. In addition, an ensemble of two FS-RNNs achieves $1.20$ BPC on Hutter Prize Wikipedia outperforming the best known compression algorithm with respect to the BPC measure. We also present an empirical investigation of the learning and network dynamics of the FS-RNN, which explains the improved performance compared to other RNN architectures. Our approach is general as any kind of RNN cell is a possible building block for the FS-RNN architecture, and thus can be flexibly applied to different tasks.
Multi-task learning with deep model based reinforcement learning
May 23, 2017

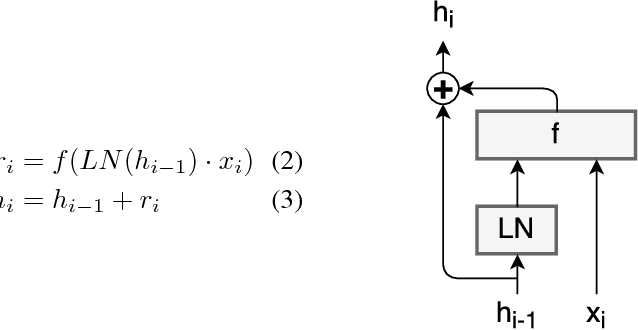
In recent years, model-free methods that use deep learning have achieved great success in many different reinforcement learning environments. Most successful approaches focus on solving a single task, while multi-task reinforcement learning remains an open problem. In this paper, we present a model based approach to deep reinforcement learning which we use to solve different tasks simultaneously. We show that our approach not only does not degrade but actually benefits from learning multiple tasks. For our model, we also present a new kind of recurrent neural network inspired by residual networks that decouples memory from computation allowing to model complex environments that do not require lots of memory.