 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMazeEval: A Benchmark for Testing Sequential Decision-Making in Language Models
Jul 27, 2025As Large Language Models (LLMs) increasingly power autonomous agents in robotics and embodied AI, understanding their spatial reasoning capabilities becomes crucial for ensuring reliable real-world deployment. Despite advances in language understanding, current research lacks evaluation of how LLMs perform spatial navigation without visual cues, a fundamental requirement for agents operating with limited sensory information. This paper addresses this gap by introducing MazeEval, a benchmark designed to isolate and evaluate pure spatial reasoning in LLMs through coordinate-based maze navigation tasks. Our methodology employs a function-calling interface where models navigate mazes of varying complexity ($5\times 5$ to $15\times 15$ grids) using only coordinate feedback and distance-to-wall information, excluding visual input to test fundamental spatial cognition. We evaluate eight state-of-the-art LLMs across identical mazes in both English and Icelandic to assess cross-linguistic transfer of spatial abilities. Our findings reveal striking disparities: while OpenAI's O3 achieves perfect navigation for mazes up to size $30\times 30$, other models exhibit catastrophic failure beyond $9\times 9$ mazes, with 100% of failures attributed to excessive looping behavior where models revisit a cell at least 10 times. We document a significant performance degradation in Icelandic, with models solving mazes 3-4 sizes smaller than in English, suggesting spatial reasoning in LLMs emerges from linguistic patterns rather than language-agnostic mechanisms. These results have important implications for global deployment of LLM-powered autonomous systems, showing spatial intelligence remains fundamentally constrained by training data availability and highlighting the need for architectural innovations to achieve reliable navigation across linguistic contexts.
Hotter and Colder: A New Approach to Annotating Sentiment, Emotions, and Bias in Icelandic Blog Comments
Feb 24, 2025



This paper presents Hotter and Colder, a dataset designed to analyze various types of online behavior in Icelandic blog comments. Building on previous work, we used GPT-4o mini to annotate approximately 800,000 comments for 25 tasks, including sentiment analysis, emotion detection, hate speech, and group generalizations. Each comment was automatically labeled on a 5-point Likert scale. In a second annotation stage, comments with high or low probabilities of containing each examined behavior were subjected to manual revision. By leveraging crowdworkers to refine these automatically labeled comments, we ensure the quality and accuracy of our dataset resulting in 12,232 uniquely annotated comments and 19,301 annotations. Hotter and Colder provides an essential resource for advancing research in content moderation and automatically detectiong harmful online behaviors in Icelandic.
FoQA: A Faroese Question-Answering Dataset
Feb 11, 2025We present FoQA, a Faroese extractive question-answering (QA) dataset with 2,000 samples, created using a semi-automated approach combining Large Language Models (LLMs) and human validation. The dataset was generated from Faroese Wikipedia articles using GPT-4-turbo for initial QA generation, followed by question rephrasing to increase complexity and native speaker validation to ensure quality. We provide baseline performance metrics for FoQA across multiple models, including LLMs and BERT, demonstrating its effectiveness in evaluating Faroese QA performance. The dataset is released in three versions: a validated set of 2,000 samples, a complete set of all 10,001 generated samples, and a set of 2,395 rejected samples for error analysis.
Cross-Lingual QA as a Stepping Stone for Monolingual Open QA in Icelandic
Jul 05, 2022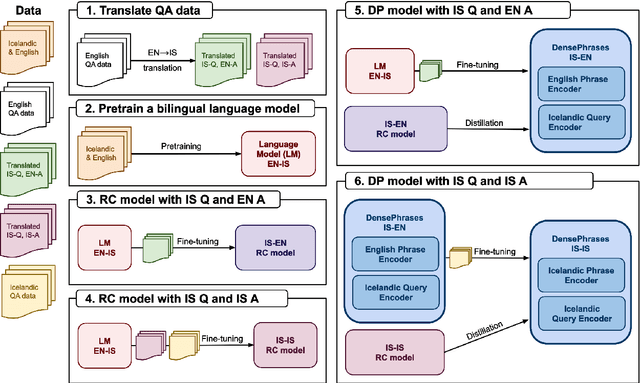
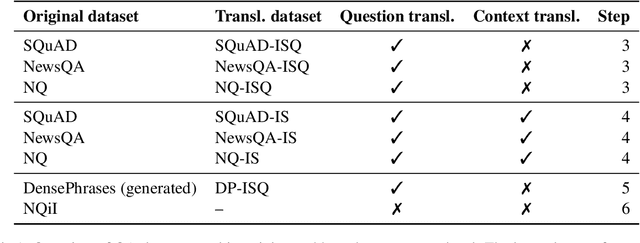
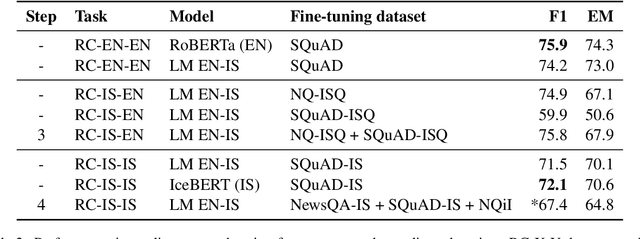
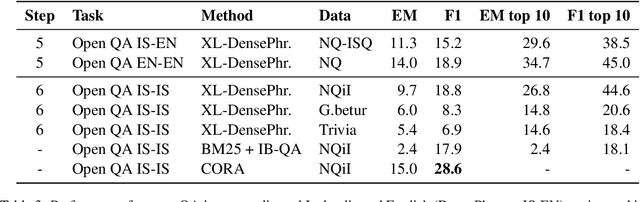
It can be challenging to build effective open question answering (open QA) systems for languages other than English, mainly due to a lack of labeled data for training. We present a data efficient method to bootstrap such a system for languages other than English. Our approach requires only limited QA resources in the given language, along with machine-translated data, and at least a bilingual language model. To evaluate our approach, we build such a system for the Icelandic language and evaluate performance over trivia style datasets. The corpora used for training are English in origin but machine translated into Icelandic. We train a bilingual Icelandic/English language model to embed English context and Icelandic questions following methodology introduced with DensePhrases (Lee et al., 2021). The resulting system is an open domain cross-lingual QA system between Icelandic and English. Finally, the system is adapted for Icelandic only open QA, demonstrating how it is possible to efficiently create an open QA system with limited access to curated datasets in the language of interest.
Building an Icelandic Entity Linking Corpus
Jun 10, 2022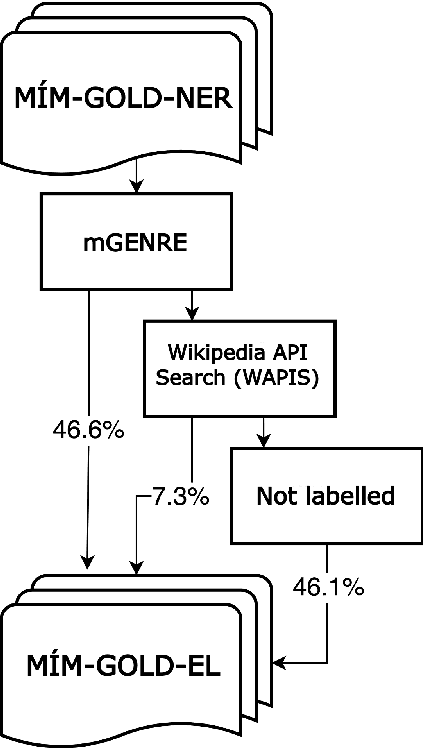
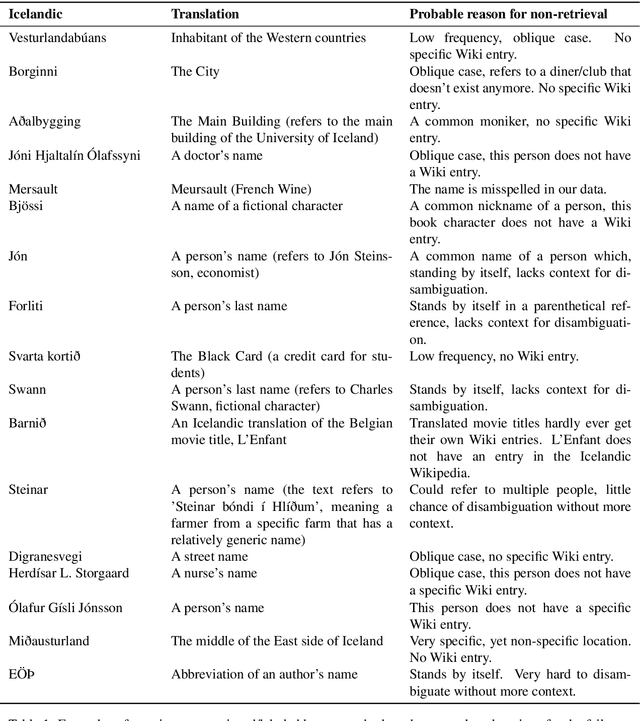
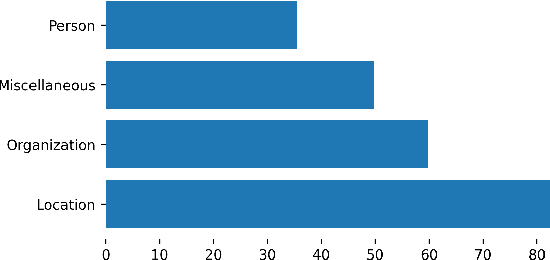
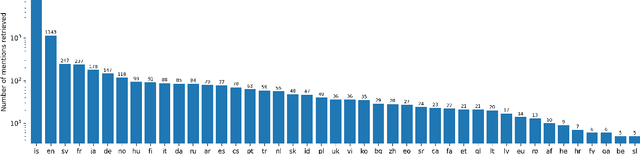
In this paper, we present the first Entity Linking corpus for Icelandic. We describe our approach of using a multilingual entity linking model (mGENRE) in combination with Wikipedia API Search (WAPIS) to label our data and compare it to an approach using WAPIS only. We find that our combined method reaches 53.9% coverage on our corpus, compared to 30.9% using only WAPIS. We analyze our results and explain the value of using a multilingual system when working with Icelandic. Additionally, we analyze the data that remain unlabeled, identify patterns and discuss why they may be more difficult to annotate.
A Warm Start and a Clean Crawled Corpus -- A Recipe for Good Language Models
Jan 18, 2022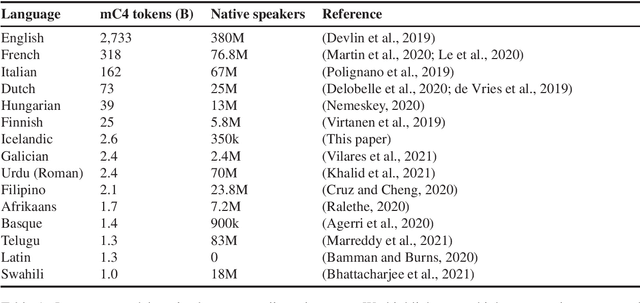
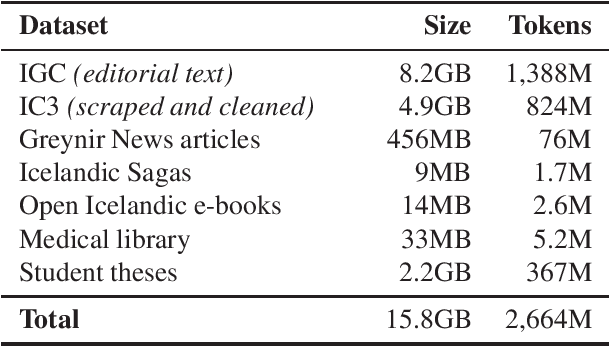

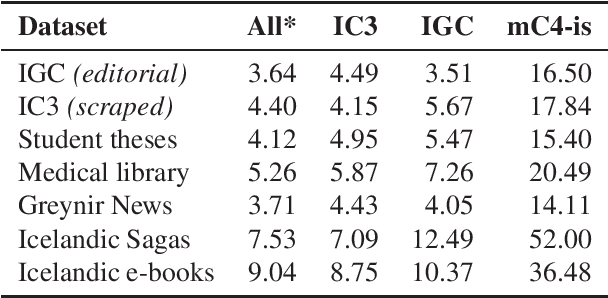
We train several language models for Icelandic, including IceBERT, that achieve state-of-the-art performance in a variety of downstream tasks, including part-of-speech tagging, named entity recognition, grammatical error detection and constituency parsing. To train the models we introduce a new corpus of Icelandic text, the Icelandic Common Crawl Corpus (IC3), a collection of high quality texts found online by targeting the Icelandic top-level-domain (TLD). Several other public data sources are also collected for a total of 16GB of Icelandic text. To enhance the evaluation of model performance and to raise the bar in baselines for Icelandic, we translate and adapt the WinoGrande dataset for co-reference resolution. Through these efforts we demonstrate that a properly cleaned crawled corpus is sufficient to achieve state-of-the-art results in NLP applications for low to medium resource languages, by comparison with models trained on a curated corpus. We further show that initializing models using existing multilingual models can lead to state-of-the-art results for some downstream tasks.
The linear hidden subset problem for the EA with scheduled and adaptive mutation rates
Aug 16, 2018We study unbiased $(1+1)$ evolutionary algorithms on linear functions with an unknown number $n$ of bits with non-zero weight. Static algorithms achieve an optimal runtime of $O(n (\ln n)^{2+\epsilon})$, however, it remained unclear whether more dynamic parameter policies could yield better runtime guarantees. We consider two setups: one where the mutation rate follows a fixed schedule, and one where it may be adapted depending on the history of the run. For the first setup, we give a schedule that achieves a runtime of $(1\pm o(1))\beta n \ln n$, where $\beta \approx 3.552$, which is an asymptotic improvement over the runtime of the static setup. Moreover, we show that no schedule admits a better runtime guarantee and that the optimal schedule is essentially unique. For the second setup, we show that the runtime can be further improved to $(1\pm o(1)) e n \ln n$, which matches the performance of algorithms that know $n$ in advance. Finally, we study the related model of initial segment uncertainty with static position-dependent mutation rates, and derive asymptotically optimal lower bounds. This answers a question by Doerr, Doerr, and K\"otzing.