 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHotter and Colder: A New Approach to Annotating Sentiment, Emotions, and Bias in Icelandic Blog Comments
Feb 24, 2025



This paper presents Hotter and Colder, a dataset designed to analyze various types of online behavior in Icelandic blog comments. Building on previous work, we used GPT-4o mini to annotate approximately 800,000 comments for 25 tasks, including sentiment analysis, emotion detection, hate speech, and group generalizations. Each comment was automatically labeled on a 5-point Likert scale. In a second annotation stage, comments with high or low probabilities of containing each examined behavior were subjected to manual revision. By leveraging crowdworkers to refine these automatically labeled comments, we ensure the quality and accuracy of our dataset resulting in 12,232 uniquely annotated comments and 19,301 annotations. Hotter and Colder provides an essential resource for advancing research in content moderation and automatically detectiong harmful online behaviors in Icelandic.
FoQA: A Faroese Question-Answering Dataset
Feb 11, 2025We present FoQA, a Faroese extractive question-answering (QA) dataset with 2,000 samples, created using a semi-automated approach combining Large Language Models (LLMs) and human validation. The dataset was generated from Faroese Wikipedia articles using GPT-4-turbo for initial QA generation, followed by question rephrasing to increase complexity and native speaker validation to ensure quality. We provide baseline performance metrics for FoQA across multiple models, including LLMs and BERT, demonstrating its effectiveness in evaluating Faroese QA performance. The dataset is released in three versions: a validated set of 2,000 samples, a complete set of all 10,001 generated samples, and a set of 2,395 rejected samples for error analysis.
Encoder vs Decoder: Comparative Analysis of Encoder and Decoder Language Models on Multilingual NLU Tasks
Jun 19, 2024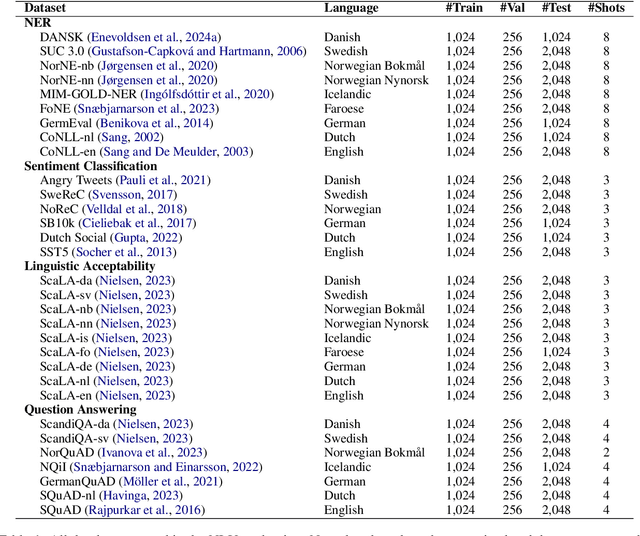
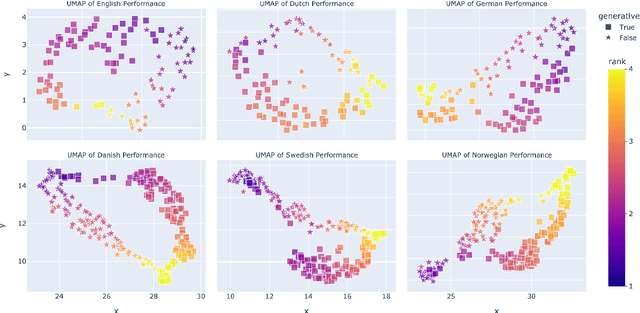

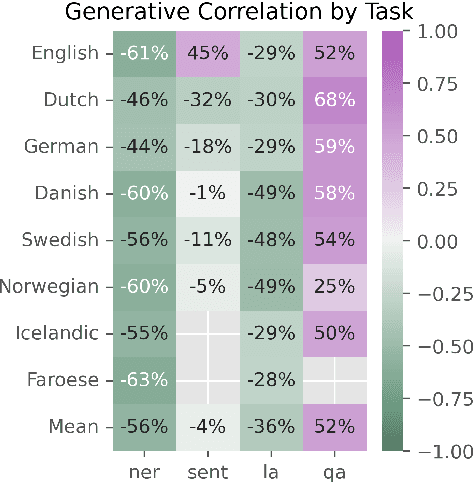
This paper explores the performance of encoder and decoder language models on multilingual Natural Language Understanding (NLU) tasks, with a broad focus on Germanic languages. Building upon the ScandEval benchmark, which initially was restricted to evaluating encoder models, we extend the evaluation framework to include decoder models. We introduce a method for evaluating decoder models on NLU tasks and apply it to the languages Danish, Swedish, Norwegian, Icelandic, Faroese, German, Dutch, and English. Through a series of experiments and analyses, we address key research questions regarding the comparative performance of encoder and decoder models, the impact of NLU task types, and the variation across language resources. Our findings reveal that decoder models can achieve significantly better NLU performance than encoder models, with nuances observed across different tasks and languages. Additionally, we investigate the correlation between decoders and task performance via a UMAP analysis, shedding light on the unique capabilities of decoder and encoder models. This study contributes to a deeper understanding of language model paradigms in NLU tasks and provides valuable insights for model selection and evaluation in multilingual settings.
Model Agnostic Explainable Selective Regression via Uncertainty Estimation
Nov 15, 2023With the wide adoption of machine learning techniques, requirements have evolved beyond sheer high performance, often requiring models to be trustworthy. A common approach to increase the trustworthiness of such systems is to allow them to refrain from predicting. Such a framework is known as selective prediction. While selective prediction for classification tasks has been widely analyzed, the problem of selective regression is understudied. This paper presents a novel approach to selective regression that utilizes model-agnostic non-parametric uncertainty estimation. Our proposed framework showcases superior performance compared to state-of-the-art selective regressors, as demonstrated through comprehensive benchmarking on 69 datasets. Finally, we use explainable AI techniques to gain an understanding of the drivers behind selective regression. We implement our selective regression method in the open-source Python package doubt and release the code used to reproduce our experiments.
ScandEval: A Benchmark for Scandinavian Natural Language Processing
Apr 03, 2023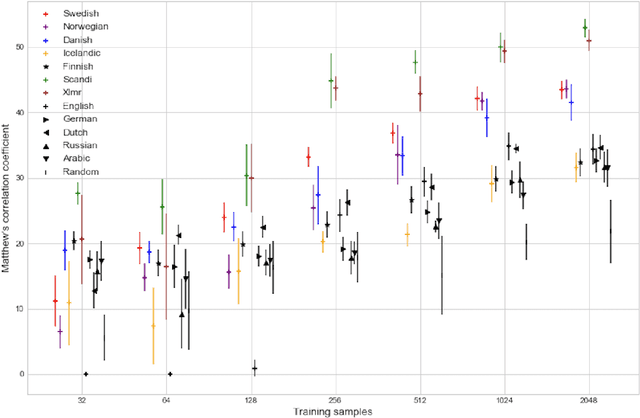


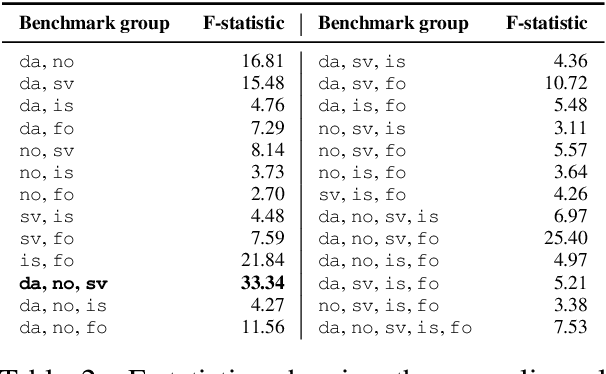
This paper introduces a Scandinavian benchmarking platform, ScandEval, which can benchmark any pretrained model on four different tasks in the Scandinavian languages. The datasets used in two of the tasks, linguistic acceptability and question answering, are new. We develop and release a Python package and command-line interface, scandeval, which can benchmark any model that has been uploaded to the Hugging Face Hub, with reproducible results. Using this package, we benchmark more than 100 Scandinavian or multilingual models and present the results of these in an interactive online leaderboard, as well as provide an analysis of the results. The analysis shows that there is substantial cross-lingual transfer among the Mainland Scandinavian languages (Danish, Swedish and Norwegian), with limited cross-lingual transfer between the group of Mainland Scandinavian languages and the group of Insular Scandinavian languages (Icelandic and Faroese). The benchmarking results also show that the investment in language technology in Norway, Sweden and Denmark has led to language models that outperform massively multilingual models such as XLM-RoBERTa and mDeBERTaV3. We release the source code for both the package and leaderboard.
MuMiN: A Large-Scale Multilingual Multimodal Fact-Checked Misinformation Social Network Dataset
Mar 08, 2022
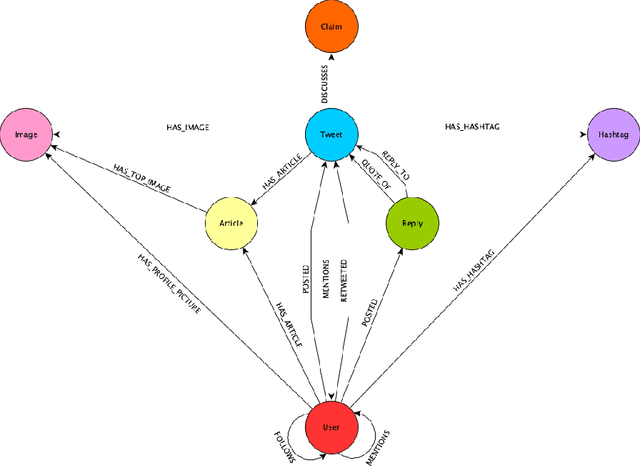
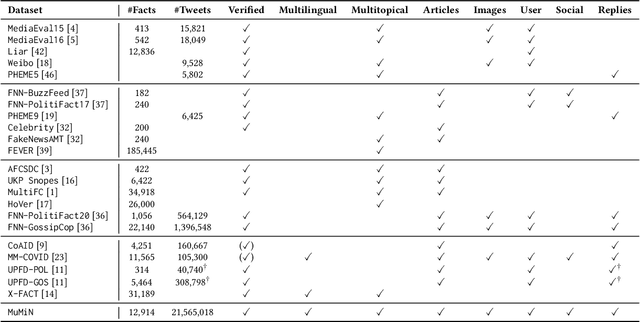
Misinformation is becoming increasingly prevalent on social media and in news articles. It has become so widespread that we require algorithmic assistance utilising machine learning to detect such content. Training these machine learning models require datasets of sufficient scale, diversity and quality. However, datasets in the field of automatic misinformation detection are predominantly monolingual, include a limited amount of modalities and are not of sufficient scale and quality. Addressing this, we develop a data collection and linking system (MuMiN-trawl), to build a public misinformation graph dataset (MuMiN), containing rich social media data (tweets, replies, users, images, articles, hashtags) spanning 21 million tweets belonging to 26 thousand Twitter threads, each of which have been semantically linked to 13 thousand fact-checked claims across dozens of topics, events and domains, in 41 different languages, spanning more than a decade. The dataset is made available as a heterogeneous graph via a Python package (mumin). We provide baseline results for two node classification tasks related to the veracity of a claim involving social media, and demonstrate that these are challenging tasks, with the highest macro-average F1-score being 62.55% and 61.45% for the two tasks, respectively. The MuMiN ecosystem is available at https://mumin-dataset.github.io/, including the data, documentation, tutorials and leaderboards.
Monitoring Model Deterioration with Explainable Uncertainty Estimation via Non-parametric Bootstrap
Jan 27, 2022Monitoring machine learning models once they are deployed is challenging. It is even more challenging to decide when to retrain models in real-case scenarios when labeled data is beyond reach, and monitoring performance metrics becomes unfeasible. In this work, we use non-parametric bootstrapped uncertainty estimates and SHAP values to provide explainable uncertainty estimation as a technique that aims to monitor the deterioration of machine learning models in deployment environments, as well as determine the source of model deterioration when target labels are not available. Classical methods are purely aimed at detecting distribution shift, which can lead to false positives in the sense that the model has not deteriorated despite a shift in the data distribution. To estimate model uncertainty we construct prediction intervals using a novel bootstrap method, which improves upon the work of Kumar & Srivastava (2012). We show that both our model deterioration detection system as well as our uncertainty estimation method achieve better performance than the current state-of-the-art. Finally, we use explainable AI techniques to gain an understanding of the drivers of model deterioration. We release an open source Python package, doubt, which implements our proposed methods, as well as the code used to reproduce our experiments.