 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide et Calibra: Multiclass Local Calibration via Vector Quantization
May 20, 2026Accurate and well-calibrated Machine Learning (ML) models are mandatory in high-stakes settings, yet effective multiclass calibration remains challenging: global approaches assume calibration errors are homogeneous across the latent space, while local methods often rely on latent-space dimensionality reduction, which leads to information loss. To address these issues, we propose a compositional approach to multiclass calibration, where region-specific calibration maps are constructed from shared codeword-dependent factors. We instantiate this idea via Vector Quantization (VQ), which induces a structured partition of the representation space, and an indexed parameterization of Dirichlet concentrations that enables parameter sharing across regions. Our approach learns heterogeneous calibration maps that generalize well even to sparse regions of the latent space. Experiments on benchmark datasets show significant improvements in local calibration while maintaining competitive global calibration and predictive performance.
Concise and Logically Consistent Conformal Sets for Neuro-Symbolic Concept-Based Models
May 18, 2026Neuro-Symbolic Concept-based Models (NeSy-CBMs) are a family of architectures that integrate neural networks with symbolic reasoning for enhanced reliability in high-stakes applications. They work by first extracting high-level concepts from the input and then inferring a task label from these compatibly with given logical constraints. Yet, their label and concept predictions can be overconfident, making it difficult for stakeholders to gauge when the model's decisions can be trusted. We address this issue by integrating ideas from Conformal Prediction (CP), a framework providing rigorous, distribution-free coverage guarantees. We formalize three desiderata -- consistency, coverage, and conciseness -- that any conformal method for NeSy-CBMs should satisfy, and show that existing approaches fall short of at least one. We then introduce COCOCO, a post-hoc framework that conformalizes concepts and labels jointly and reconciles them via a single deduction-abduction revision step. COCOCO satisfies all three desiderata, retains distribution-free coverage, is robust to imperfect knowledge and supports user-specified size budgets. Our experiments on 8 data sets highlight how COCOCO compares favorably against competitors and natural baselines in terms of performance and set size.
Bounded-Abstention Multi-horizon Time-series Forecasting
Feb 04, 2026Multi-horizon time-series forecasting involves simultaneously making predictions for a consecutive sequence of subsequent time steps. This task arises in many application domains, such as healthcare and finance, where mispredictions can have a high cost and reduce trust. The learning with abstention framework tackles these problems by allowing a model to abstain from offering a prediction when it is at an elevated risk of making a misprediction. Unfortunately, existing abstention strategies are ill-suited for the multi-horizon setting: they target problems where a model offers a single prediction for each instance. Hence, they ignore the structured and correlated nature of the predictions offered by a multi-horizon forecaster. We formalize the problem of learning with abstention for multi-horizon forecasting setting and show that its structured nature admits a richer set of abstention problems. Concretely, we propose three natural notions of how a model could abstain for multi-horizon forecasting. We theoretically analyze each problem to derive the optimal abstention strategy and propose an algorithm that implements it. Extensive evaluation on 24 datasets shows that our proposed algorithms significantly outperforms existing baselines.
Multiclass Local Calibration With the Jensen-Shannon Distance
Oct 30, 2025Developing trustworthy Machine Learning (ML) models requires their predicted probabilities to be well-calibrated, meaning they should reflect true-class frequencies. Among calibration notions in multiclass classification, strong calibration is the most stringent, as it requires all predicted probabilities to be simultaneously calibrated across all classes. However, existing approaches to multiclass calibration lack a notion of distance among inputs, which makes them vulnerable to proximity bias: predictions in sparse regions of the feature space are systematically miscalibrated. This is especially relevant in high-stakes settings, such as healthcare, where the sparse instances are exactly those most at risk of biased treatment. In this work, we address this main shortcoming by introducing a local perspective on multiclass calibration. First, we formally define multiclass local calibration and establish its relationship with strong calibration. Second, we theoretically analyze the pitfalls of existing evaluation metrics when applied to multiclass local calibration. Third, we propose a practical method for enhancing local calibration in Neural Networks, which enforces alignment between predicted probabilities and local estimates of class frequencies using the Jensen-Shannon distance. Finally, we empirically validate our approach against existing multiclass calibration techniques.
Bounded-Abstention Pairwise Learning to Rank
May 29, 2025


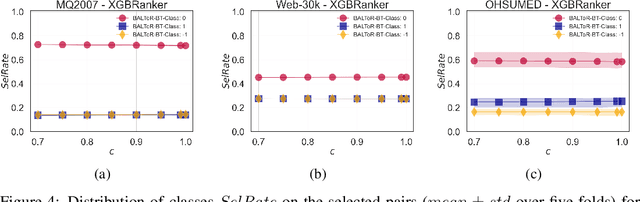
Ranking systems influence decision-making in high-stakes domains like health, education, and employment, where they can have substantial economic and social impacts. This makes the integration of safety mechanisms essential. One such mechanism is $\textit{abstention}$, which enables algorithmic decision-making system to defer uncertain or low-confidence decisions to human experts. While abstention have been predominantly explored in the context of classification tasks, its application to other machine learning paradigms remains underexplored. In this paper, we introduce a novel method for abstention in pairwise learning-to-rank tasks. Our approach is based on thresholding the ranker's conditional risk: the system abstains from making a decision when the estimated risk exceeds a predefined threshold. Our contributions are threefold: a theoretical characterization of the optimal abstention strategy, a model-agnostic, plug-in algorithm for constructing abstaining ranking models, and a comprehensive empirical evaluations across multiple datasets, demonstrating the effectiveness of our approach.
Interpretable and Fair Mechanisms for Abstaining Classifiers
Mar 24, 2025Abstaining classifiers have the option to refrain from providing a prediction for instances that are difficult to classify. The abstention mechanism is designed to trade off the classifier's performance on the accepted data while ensuring a minimum number of predictions. In this setting, often fairness concerns arise when the abstention mechanism solely reduces errors for the majority groups of the data, resulting in increased performance differences across demographic groups. While there exist a bunch of methods that aim to reduce discrimination when abstaining, there is no mechanism that can do so in an explainable way. In this paper, we fill this gap by introducing Interpretable and Fair Abstaining Classifier IFAC, an algorithm that can reject predictions both based on their uncertainty and their unfairness. By rejecting possibly unfair predictions, our method reduces error and positive decision rate differences across demographic groups of the non-rejected data. Since the unfairness-based rejections are based on an interpretable-by-design method, i.e., rule-based fairness checks and situation testing, we create a transparent process that can empower human decision-makers to review the unfair predictions and make more just decisions for them. This explainable aspect is especially important in light of recent AI regulations, mandating that any high-risk decision task should be overseen by human experts to reduce discrimination risks.
Deferring Concept Bottleneck Models: Learning to Defer Interventions to Inaccurate Experts
Mar 20, 2025Concept Bottleneck Models (CBMs) are machine learning models that improve interpretability by grounding their predictions on human-understandable concepts, allowing for targeted interventions in their decision-making process. However, when intervened on, CBMs assume the availability of humans that can identify the need to intervene and always provide correct interventions. Both assumptions are unrealistic and impractical, considering labor costs and human error-proneness. In contrast, Learning to Defer (L2D) extends supervised learning by allowing machine learning models to identify cases where a human is more likely to be correct than the model, thus leading to deferring systems with improved performance. In this work, we gain inspiration from L2D and propose Deferring CBMs (DCBMs), a novel framework that allows CBMs to learn when an intervention is needed. To this end, we model DCBMs as a composition of deferring systems and derive a consistent L2D loss to train them. Moreover, by relying on a CBM architecture, DCBMs can explain why defer occurs on the final task. Our results show that DCBMs achieve high predictive performance and interpretability at the cost of deferring more to humans.
A Causal Framework for Evaluating Deferring Systems
May 29, 2024Deferring systems extend supervised Machine Learning (ML) models with the possibility to defer predictions to human experts. However, evaluating the impact of a deferring strategy on system accuracy is still an overlooked area. This paper fills this gap by evaluating deferring systems through a causal lens. We link the potential outcomes framework for causal inference with deferring systems. This allows us to identify the causal impact of the deferring strategy on predictive accuracy. We distinguish two scenarios. In the first one, we can access both the human and the ML model predictions for the deferred instances. In such a case, we can identify the individual causal effects for deferred instances and aggregates of them. In the second scenario, only human predictions are available for the deferred instances. In this case, we can resort to regression discontinuity design to estimate a local causal effect. We empirically evaluate our approach on synthetic and real datasets for seven deferring systems from the literature.
Deep Neural Network Benchmarks for Selective Classification
Jan 23, 2024With the increasing deployment of machine learning models in many socially-sensitive tasks, there is a growing demand for reliable and trustworthy predictions. One way to accomplish these requirements is to allow a model to abstain from making a prediction when there is a high risk of making an error. This requires adding a selection mechanism to the model, which selects those examples for which the model will provide a prediction. The selective classification framework aims to design a mechanism that balances the fraction of rejected predictions (i.e., the proportion of examples for which the model does not make a prediction) versus the improvement in predictive performance on the selected predictions. Multiple selective classification frameworks exist, most of which rely on deep neural network architectures. However, the empirical evaluation of the existing approaches is still limited to partial comparisons among methods and settings, providing practitioners with little insight into their relative merits. We fill this gap by benchmarking 18 baselines on a diverse set of 44 datasets that includes both image and tabular data. Moreover, there is a mix of binary and multiclass tasks. We evaluate these approaches using several criteria, including selective error rate, empirical coverage, distribution of rejected instance's classes, and performance on out-of-distribution instances. The results indicate that there is not a single clear winner among the surveyed baselines, and the best method depends on the users' objectives.
Model Agnostic Explainable Selective Regression via Uncertainty Estimation
Nov 15, 2023With the wide adoption of machine learning techniques, requirements have evolved beyond sheer high performance, often requiring models to be trustworthy. A common approach to increase the trustworthiness of such systems is to allow them to refrain from predicting. Such a framework is known as selective prediction. While selective prediction for classification tasks has been widely analyzed, the problem of selective regression is understudied. This paper presents a novel approach to selective regression that utilizes model-agnostic non-parametric uncertainty estimation. Our proposed framework showcases superior performance compared to state-of-the-art selective regressors, as demonstrated through comprehensive benchmarking on 69 datasets. Finally, we use explainable AI techniques to gain an understanding of the drivers behind selective regression. We implement our selective regression method in the open-source Python package doubt and release the code used to reproduce our experiments.