 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Concept-Based Models: Interpretable models with distributed supervision
Feb 04, 2026Concept-based models (CMs) enhance interpretability in deep learning by grounding predictions in human-understandable concepts. However, concept annotations are expensive to obtain and rarely available at scale within a single data source. Federated learning (FL) could alleviate this limitation by enabling cross-institutional training that leverages concept annotations distributed across multiple data owners. Yet, FL lacks interpretable modeling paradigms. Integrating CMs with FL is non-trivial: CMs assume a fixed concept space and a predefined model architecture, whereas real-world FL is heterogeneous and non-stationary, with institutions joining over time and bringing new supervision. In this work, we propose Federated Concept-based Models (F-CMs), a new methodology for deploying CMs in evolving FL settings. F-CMs aggregate concept-level information across institutions and efficiently adapt the model architecture in response to changes in the available concept supervision, while preserving institutional privacy. Empirically, F-CMs preserve the accuracy and intervention effectiveness of training settings with full concept supervision, while outperforming non-adaptive federated baselines. Notably, F-CMs enable interpretable inference on concepts not available to a given institution, a key novelty with respect to existing approaches.
Mixture of Concept Bottleneck Experts
Feb 02, 2026Concept Bottleneck Models (CBMs) promote interpretability by grounding predictions in human-understandable concepts. However, existing CBMs typically fix their task predictor to a single linear or Boolean expression, limiting both predictive accuracy and adaptability to diverse user needs. We propose Mixture of Concept Bottleneck Experts (M-CBEs), a framework that generalizes existing CBMs along two dimensions: the number of experts and the functional form of each expert, exposing an underexplored region of the design space. We investigate this region by instantiating two novel models: Linear M-CBE, which learns a finite set of linear expressions, and Symbolic M-CBE, which leverages symbolic regression to discover expert functions from data under user-specified operator vocabularies. Empirical evaluation demonstrates that varying the mixture size and functional form provides a robust framework for navigating the accuracy-interpretability trade-off, adapting to different user and task needs.
Interpretability in Deep Time Series Models Demands Semantic Alignment
Feb 02, 2026Deep time series models continue to improve predictive performance, yet their deployment remains limited by their black-box nature. In response, existing interpretability approaches in the field keep focusing on explaining the internal model computations, without addressing whether they align or not with how a human would reason about the studied phenomenon. Instead, we state interpretability in deep time series models should pursue semantic alignment: predictions should be expressed in terms of variables that are meaningful to the end user, mediated by spatial and temporal mechanisms that admit user-dependent constraints. In this paper, we formalize this requirement and require that, once established, semantic alignment must be preserved under temporal evolution: a constraint with no analog in static settings. Provided with this definition, we outline a blueprint for semantically aligned deep time series models, identify properties that support trust, and discuss implications for model design.
Actionable Interpretability Must Be Defined in Terms of Symmetries
Jan 19, 2026This paper argues that interpretability research in Artificial Intelligence is fundamentally ill-posed as existing definitions of interpretability are not *actionable*: they fail to provide formal principles from which concrete modelling and inferential rules can be derived. We posit that for a definition of interpretability to be actionable, it must be given in terms of *symmetries*. We hypothesise that four symmetries suffice to (i) motivate core interpretability properties, (ii) characterize the class of interpretable models, and (iii) derive a unified formulation of interpretable inference (e.g., alignment, interventions, and counterfactuals) as a form of Bayesian inversion.
If Concept Bottlenecks are the Question, are Foundation Models the Answer?
Apr 29, 2025Concept Bottleneck Models (CBMs) are neural networks designed to conjoin high performance with ante-hoc interpretability. CBMs work by first mapping inputs (e.g., images) to high-level concepts (e.g., visible objects and their properties) and then use these to solve a downstream task (e.g., tagging or scoring an image) in an interpretable manner. Their performance and interpretability, however, hinge on the quality of the concepts they learn. The go-to strategy for ensuring good quality concepts is to leverage expert annotations, which are expensive to collect and seldom available in applications. Researchers have recently addressed this issue by introducing "VLM-CBM" architectures that replace manual annotations with weak supervision from foundation models. It is however unclear what is the impact of doing so on the quality of the learned concepts. To answer this question, we put state-of-the-art VLM-CBMs to the test, analyzing their learned concepts empirically using a selection of significant metrics. Our results show that, depending on the task, VLM supervision can sensibly differ from expert annotations, and that concept accuracy and quality are not strongly correlated. Our code is available at https://github.com/debryu/CQA.
Avoiding Leakage Poisoning: Concept Interventions Under Distribution Shifts
Apr 24, 2025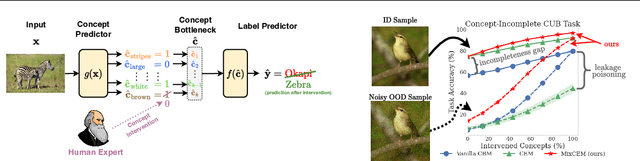
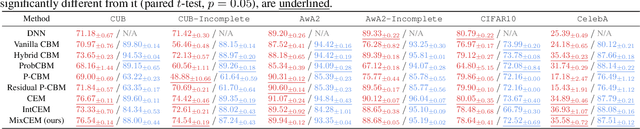
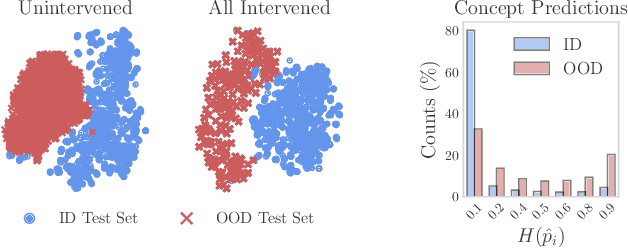

In this paper, we investigate how concept-based models (CMs) respond to out-of-distribution (OOD) inputs. CMs are interpretable neural architectures that first predict a set of high-level concepts (e.g., stripes, black) and then predict a task label from those concepts. In particular, we study the impact of concept interventions (i.e., operations where a human expert corrects a CM's mispredicted concepts at test time) on CMs' task predictions when inputs are OOD. Our analysis reveals a weakness in current state-of-the-art CMs, which we term leakage poisoning, that prevents them from properly improving their accuracy when intervened on for OOD inputs. To address this, we introduce MixCEM, a new CM that learns to dynamically exploit leaked information missing from its concepts only when this information is in-distribution. Our results across tasks with and without complete sets of concept annotations demonstrate that MixCEMs outperform strong baselines by significantly improving their accuracy for both in-distribution and OOD samples in the presence and absence of concept interventions.
Logic Explanation of AI Classifiers by Categorical Explaining Functors
Mar 20, 2025The most common methods in explainable artificial intelligence are post-hoc techniques which identify the most relevant features used by pretrained opaque models. Some of the most advanced post hoc methods can generate explanations that account for the mutual interactions of input features in the form of logic rules. However, these methods frequently fail to guarantee the consistency of the extracted explanations with the model's underlying reasoning. To bridge this gap, we propose a theoretically grounded approach to ensure coherence and fidelity of the extracted explanations, moving beyond the limitations of current heuristic-based approaches. To this end, drawing from category theory, we introduce an explaining functor which structurally preserves logical entailment between the explanation and the opaque model's reasoning. As a proof of concept, we validate the proposed theoretical constructions on a synthetic benchmark verifying how the proposed approach significantly mitigates the generation of contradictory or unfaithful explanations.
Deferring Concept Bottleneck Models: Learning to Defer Interventions to Inaccurate Experts
Mar 20, 2025Concept Bottleneck Models (CBMs) are machine learning models that improve interpretability by grounding their predictions on human-understandable concepts, allowing for targeted interventions in their decision-making process. However, when intervened on, CBMs assume the availability of humans that can identify the need to intervene and always provide correct interventions. Both assumptions are unrealistic and impractical, considering labor costs and human error-proneness. In contrast, Learning to Defer (L2D) extends supervised learning by allowing machine learning models to identify cases where a human is more likely to be correct than the model, thus leading to deferring systems with improved performance. In this work, we gain inspiration from L2D and propose Deferring CBMs (DCBMs), a novel framework that allows CBMs to learn when an intervention is needed. To this end, we model DCBMs as a composition of deferring systems and derive a consistent L2D loss to train them. Moreover, by relying on a CBM architecture, DCBMs can explain why defer occurs on the final task. Our results show that DCBMs achieve high predictive performance and interpretability at the cost of deferring more to humans.
Causally Reliable Concept Bottleneck Models
Mar 06, 2025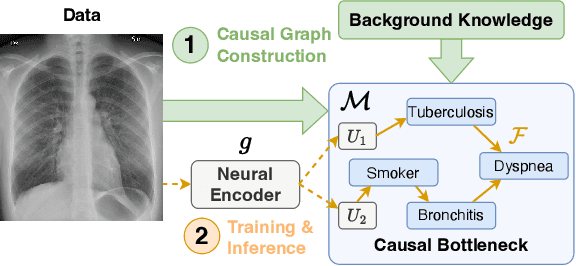



Concept-based models are an emerging paradigm in deep learning that constrains the inference process to operate through human-interpretable concepts, facilitating explainability and human interaction. However, these architectures, on par with popular opaque neural models, fail to account for the true causal mechanisms underlying the target phenomena represented in the data. This hampers their ability to support causal reasoning tasks, limits out-of-distribution generalization, and hinders the implementation of fairness constraints. To overcome these issues, we propose \emph{Causally reliable Concept Bottleneck Models} (C$^2$BMs), a class of concept-based architectures that enforce reasoning through a bottleneck of concepts structured according to a model of the real-world causal mechanisms. We also introduce a pipeline to automatically learn this structure from observational data and \emph{unstructured} background knowledge (e.g., scientific literature). Experimental evidence suggest that C$^2$BM are more interpretable, causally reliable, and improve responsiveness to interventions w.r.t. standard opaque and concept-based models, while maintaining their accuracy.
Neural Interpretable Reasoning
Feb 17, 2025

We formalize a novel modeling framework for achieving interpretability in deep learning, anchored in the principle of inference equivariance. While the direct verification of interpretability scales exponentially with the number of variables of the system, we show that this complexity can be mitigated by treating interpretability as a Markovian property and employing neural re-parametrization techniques. Building on these insights, we propose a new modeling paradigm -- neural generation and interpretable execution -- that enables scalable verification of equivariance. This paradigm provides a general approach for designing Neural Interpretable Reasoners that are not only expressive but also transparent.