 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Concept-Based Models: Interpretable models with distributed supervision
Feb 04, 2026Concept-based models (CMs) enhance interpretability in deep learning by grounding predictions in human-understandable concepts. However, concept annotations are expensive to obtain and rarely available at scale within a single data source. Federated learning (FL) could alleviate this limitation by enabling cross-institutional training that leverages concept annotations distributed across multiple data owners. Yet, FL lacks interpretable modeling paradigms. Integrating CMs with FL is non-trivial: CMs assume a fixed concept space and a predefined model architecture, whereas real-world FL is heterogeneous and non-stationary, with institutions joining over time and bringing new supervision. In this work, we propose Federated Concept-based Models (F-CMs), a new methodology for deploying CMs in evolving FL settings. F-CMs aggregate concept-level information across institutions and efficiently adapt the model architecture in response to changes in the available concept supervision, while preserving institutional privacy. Empirically, F-CMs preserve the accuracy and intervention effectiveness of training settings with full concept supervision, while outperforming non-adaptive federated baselines. Notably, F-CMs enable interpretable inference on concepts not available to a given institution, a key novelty with respect to existing approaches.
Avoiding Leakage Poisoning: Concept Interventions Under Distribution Shifts
Apr 24, 2025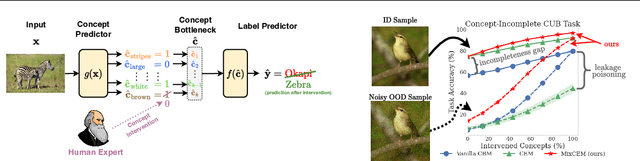
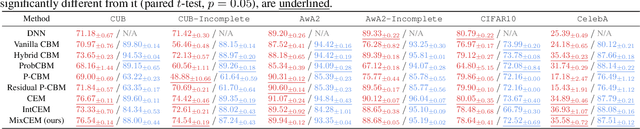
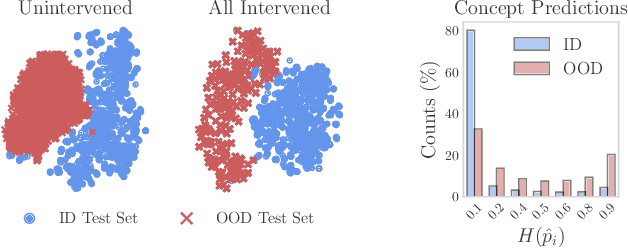

In this paper, we investigate how concept-based models (CMs) respond to out-of-distribution (OOD) inputs. CMs are interpretable neural architectures that first predict a set of high-level concepts (e.g., stripes, black) and then predict a task label from those concepts. In particular, we study the impact of concept interventions (i.e., operations where a human expert corrects a CM's mispredicted concepts at test time) on CMs' task predictions when inputs are OOD. Our analysis reveals a weakness in current state-of-the-art CMs, which we term leakage poisoning, that prevents them from properly improving their accuracy when intervened on for OOD inputs. To address this, we introduce MixCEM, a new CM that learns to dynamically exploit leaked information missing from its concepts only when this information is in-distribution. Our results across tasks with and without complete sets of concept annotations demonstrate that MixCEMs outperform strong baselines by significantly improving their accuracy for both in-distribution and OOD samples in the presence and absence of concept interventions.
Deferring Concept Bottleneck Models: Learning to Defer Interventions to Inaccurate Experts
Mar 20, 2025Concept Bottleneck Models (CBMs) are machine learning models that improve interpretability by grounding their predictions on human-understandable concepts, allowing for targeted interventions in their decision-making process. However, when intervened on, CBMs assume the availability of humans that can identify the need to intervene and always provide correct interventions. Both assumptions are unrealistic and impractical, considering labor costs and human error-proneness. In contrast, Learning to Defer (L2D) extends supervised learning by allowing machine learning models to identify cases where a human is more likely to be correct than the model, thus leading to deferring systems with improved performance. In this work, we gain inspiration from L2D and propose Deferring CBMs (DCBMs), a novel framework that allows CBMs to learn when an intervention is needed. To this end, we model DCBMs as a composition of deferring systems and derive a consistent L2D loss to train them. Moreover, by relying on a CBM architecture, DCBMs can explain why defer occurs on the final task. Our results show that DCBMs achieve high predictive performance and interpretability at the cost of deferring more to humans.
Evaluating Explanations Through LLMs: Beyond Traditional User Studies
Oct 23, 2024



As AI becomes fundamental in sectors like healthcare, explainable AI (XAI) tools are essential for trust and transparency. However, traditional user studies used to evaluate these tools are often costly, time consuming, and difficult to scale. In this paper, we explore the use of Large Language Models (LLMs) to replicate human participants to help streamline XAI evaluation. We reproduce a user study comparing counterfactual and causal explanations, replicating human participants with seven LLMs under various settings. Our results show that (i) LLMs can replicate most conclusions from the original study, (ii) different LLMs yield varying levels of alignment in the results, and (iii) experimental factors such as LLM memory and output variability affect alignment with human responses. These initial findings suggest that LLMs could provide a scalable and cost-effective way to simplify qualitative XAI evaluation.
DC3DO: Diffusion Classifier for 3D Objects
Aug 13, 2024



Inspired by Geoffrey Hinton emphasis on generative modeling, To recognize shapes, first learn to generate them, we explore the use of 3D diffusion models for object classification. Leveraging the density estimates from these models, our approach, the Diffusion Classifier for 3D Objects (DC3DO), enables zero-shot classification of 3D shapes without additional training. On average, our method achieves a 12.5 percent improvement compared to its multiview counterparts, demonstrating superior multimodal reasoning over discriminative approaches. DC3DO employs a class-conditional diffusion model trained on ShapeNet, and we run inferences on point clouds of chairs and cars. This work highlights the potential of generative models in 3D object classification.
Causal Concept Embedding Models: Beyond Causal Opacity in Deep Learning
May 28, 2024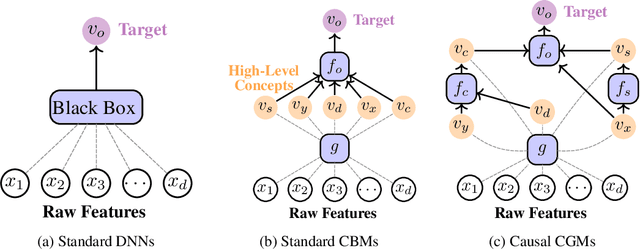



Causal opacity denotes the difficulty in understanding the "hidden" causal structure underlying a deep neural network's (DNN) reasoning. This leads to the inability to rely on and verify state-of-the-art DNN-based systems especially in high-stakes scenarios. For this reason, causal opacity represents a key open challenge at the intersection of deep learning, interpretability, and causality. This work addresses this gap by introducing Causal Concept Embedding Models (Causal CEMs), a class of interpretable models whose decision-making process is causally transparent by design. The results of our experiments show that Causal CEMs can: (i) match the generalization performance of causally-opaque models, (ii) support the analysis of interventional and counterfactual scenarios, thereby improving the model's causal interpretability and supporting the effective verification of its reliability and fairness, and (iii) enable human-in-the-loop corrections to mispredicted intermediate reasoning steps, boosting not just downstream accuracy after corrections but also accuracy of the explanation provided for a specific instance.
AnyCBMs: How to Turn Any Black Box into a Concept Bottleneck Model
May 26, 2024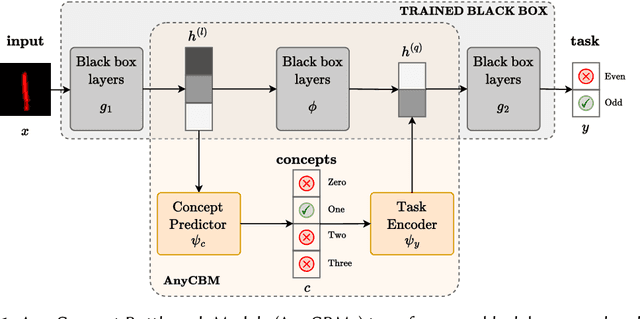

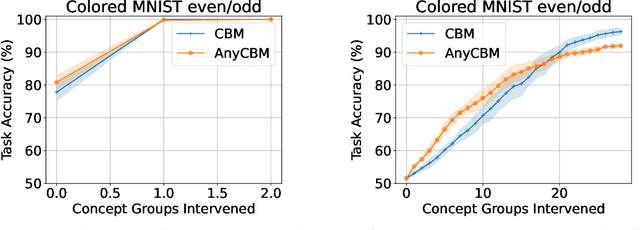

Interpretable deep learning aims at developing neural architectures whose decision-making processes could be understood by their users. Among these techniqes, Concept Bottleneck Models enhance the interpretability of neural networks by integrating a layer of human-understandable concepts. These models, however, necessitate training a new model from the beginning, consuming significant resources and failing to utilize already trained large models. To address this issue, we introduce "AnyCBM", a method that transforms any existing trained model into a Concept Bottleneck Model with minimal impact on computational resources. We provide both theoretical and experimental insights showing the effectiveness of AnyCBMs in terms of classification performances and effectivenss of concept-based interventions on downstream tasks.
Federated Behavioural Planes: Explaining the Evolution of Client Behaviour in Federated Learning
May 24, 2024Federated Learning (FL), a privacy-aware approach in distributed deep learning environments, enables many clients to collaboratively train a model without sharing sensitive data, thereby reducing privacy risks. However, enabling human trust and control over FL systems requires understanding the evolving behaviour of clients, whether beneficial or detrimental for the training, which still represents a key challenge in the current literature. To address this challenge, we introduce Federated Behavioural Planes (FBPs), a novel method to analyse, visualise, and explain the dynamics of FL systems, showing how clients behave under two different lenses: predictive performance (error behavioural space) and decision-making processes (counterfactual behavioural space). Our experiments demonstrate that FBPs provide informative trajectories describing the evolving states of clients and their contributions to the global model, thereby enabling the identification of clusters of clients with similar behaviours. Leveraging the patterns identified by FBPs, we propose a robust aggregation technique named Federated Behavioural Shields to detect malicious or noisy client models, thereby enhancing security and surpassing the efficacy of existing state-of-the-art FL defense mechanisms.
Climbing the Ladder of Interpretability with Counterfactual Concept Bottleneck Models
Feb 02, 2024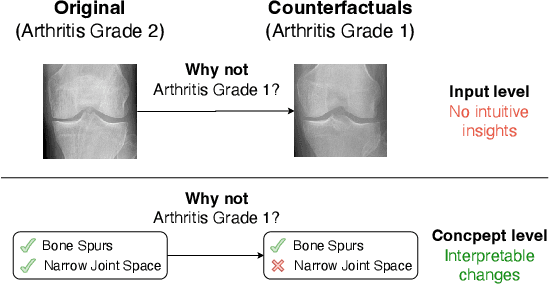
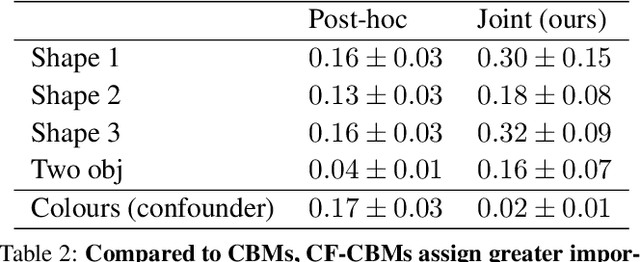
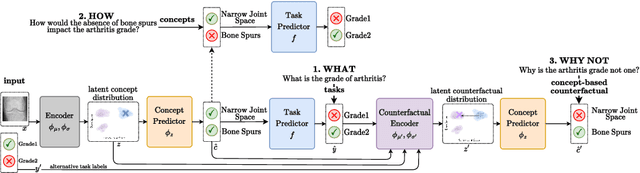

Current deep learning models are not designed to simultaneously address three fundamental questions: predict class labels to solve a given classification task (the "What?"), explain task predictions (the "Why?"), and imagine alternative scenarios that could result in different predictions (the "What if?"). The inability to answer these questions represents a crucial gap in deploying reliable AI agents, calibrating human trust, and deepening human-machine interaction. To bridge this gap, we introduce CounterFactual Concept Bottleneck Models (CF-CBMs), a class of models designed to efficiently address the above queries all at once without the need to run post-hoc searches. Our results show that CF-CBMs produce: accurate predictions (the "What?"), simple explanations for task predictions (the "Why?"), and interpretable counterfactuals (the "What if?"). CF-CBMs can also sample or estimate the most probable counterfactual to: (i) explain the effect of concept interventions on tasks, (ii) show users how to get a desired class label, and (iii) propose concept interventions via "task-driven" interventions.
SHARCS: Shared Concept Space for Explainable Multimodal Learning
Jul 01, 2023


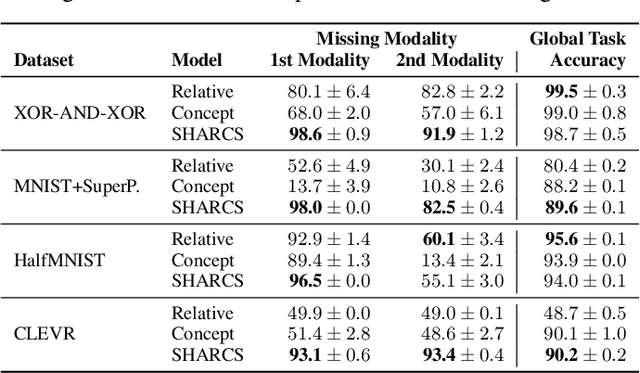
Multimodal learning is an essential paradigm for addressing complex real-world problems, where individual data modalities are typically insufficient to accurately solve a given modelling task. While various deep learning approaches have successfully addressed these challenges, their reasoning process is often opaque; limiting the capabilities for a principled explainable cross-modal analysis and any domain-expert intervention. In this paper, we introduce SHARCS (SHARed Concept Space) -- a novel concept-based approach for explainable multimodal learning. SHARCS learns and maps interpretable concepts from different heterogeneous modalities into a single unified concept-manifold, which leads to an intuitive projection of semantically similar cross-modal concepts. We demonstrate that such an approach can lead to inherently explainable task predictions while also improving downstream predictive performance. Moreover, we show that SHARCS can operate and significantly outperform other approaches in practically significant scenarios, such as retrieval of missing modalities and cross-modal explanations. Our approach is model-agnostic and easily applicable to different types (and number) of modalities, thus advancing the development of effective, interpretable, and trustworthy multimodal approaches.