 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Hearthstone Agents using an Evolutionary Algorithm
Oct 25, 2024



Digital collectible card games are not only a growing part of the video game industry, but also an interesting research area for the field of computational intelligence. This game genre allows researchers to deal with hidden information, uncertainty and planning, among other aspects. This paper proposes the use of evolutionary algorithms (EAs) to develop agents who play a card game, Hearthstone, by optimizing a data-driven decision-making mechanism that takes into account all the elements currently in play. Agents feature self-learning by means of a competitive coevolutionary training approach, whereby no external sparring element defined by the user is required for the optimization process. One of the agents developed through the proposed approach was runner-up (best 6%) in an international Hearthstone Artificial Intelligence (AI) competition. Our proposal performed remarkably well, even when it faced state-of-the-art techniques that attempted to take into account future game states, such as Monte-Carlo Tree search. This outcome shows how evolutionary computation could represent a considerable advantage in developing AIs for collectible card games such as Hearthstone.
* 43 pages, 11 figures
Federated Behavioural Planes: Explaining the Evolution of Client Behaviour in Federated Learning
May 24, 2024Federated Learning (FL), a privacy-aware approach in distributed deep learning environments, enables many clients to collaboratively train a model without sharing sensitive data, thereby reducing privacy risks. However, enabling human trust and control over FL systems requires understanding the evolving behaviour of clients, whether beneficial or detrimental for the training, which still represents a key challenge in the current literature. To address this challenge, we introduce Federated Behavioural Planes (FBPs), a novel method to analyse, visualise, and explain the dynamics of FL systems, showing how clients behave under two different lenses: predictive performance (error behavioural space) and decision-making processes (counterfactual behavioural space). Our experiments demonstrate that FBPs provide informative trajectories describing the evolving states of clients and their contributions to the global model, thereby enabling the identification of clusters of clients with similar behaviours. Leveraging the patterns identified by FBPs, we propose a robust aggregation technique named Federated Behavioural Shields to detect malicious or noisy client models, thereby enhancing security and surpassing the efficacy of existing state-of-the-art FL defense mechanisms.
Interpretable Neural-Symbolic Concept Reasoning
Apr 27, 2023



Deep learning methods are highly accurate, yet their opaque decision process prevents them from earning full human trust. Concept-based models aim to address this issue by learning tasks based on a set of human-understandable concepts. However, state-of-the-art concept-based models rely on high-dimensional concept embedding representations which lack a clear semantic meaning, thus questioning the interpretability of their decision process. To overcome this limitation, we propose the Deep Concept Reasoner (DCR), the first interpretable concept-based model that builds upon concept embeddings. In DCR, neural networks do not make task predictions directly, but they build syntactic rule structures using concept embeddings. DCR then executes these rules on meaningful concept truth degrees to provide a final interpretable and semantically-consistent prediction in a differentiable manner. Our experiments show that DCR: (i) improves up to +25% w.r.t. state-of-the-art interpretable concept-based models on challenging benchmarks (ii) discovers meaningful logic rules matching known ground truths even in the absence of concept supervision during training, and (iii), facilitates the generation of counterfactual examples providing the learnt rules as guidance.
Categorical Foundations of Explainable AI: A Unifying Formalism of Structures and Semantics
Apr 27, 2023Explainable AI (XAI) aims to answer ethical and legal questions associated with the deployment of AI models. However, a considerable number of domain-specific reviews highlight the need of a mathematical foundation for the key notions in the field, considering that even the term "explanation" still lacks a precise definition. These reviews also advocate for a sound and unifying formalism for explainable AI, to avoid the emergence of ill-posed questions, and to help researchers navigate a rapidly growing body of knowledge. To the authors knowledge, this paper is the first attempt to fill this gap by formalizing a unifying theory of XAI. Employing the framework of category theory, and feedback monoidal categories in particular, we first provide formal definitions for all essential terms in explainable AI. Then we propose a taxonomy of the field following the proposed structure, showing how the introduced theory can be used to categorize all the main classes of XAI systems currently studied in literature. In summary, the foundation of XAI proposed in this paper represents a significant tool to properly frame future research lines, and a precious guidance for new researchers approaching the field.
Direct Comparative Analysis of Nature-inspired Optimization Algorithms on Community Detection Problem in Social Networks
Dec 21, 2022Nature-inspired optimization Algorithms (NIOAs) are nowadays a popular choice for community detection in social networks. Community detection problem in social network is treated as optimization problem, where the objective is to either maximize the connection within the community or minimize connections between the communities. To apply NIOAs, either of the two, or both objectives are explored. Since NIOAs mostly exploit randomness in their strategies, it is necessary to analyze their performance for specific applications. In this paper, NIOAs are analyzed on the community detection problem. A direct comparison approach is followed to perform pairwise comparison of NIOAs. The performance is measured in terms of five scores designed based on prasatul matrix and also with average isolability. Three widely used real-world social networks and four NIOAs are considered for analyzing the quality of communities generated by NIOAs.
Modeling Generalization in Machine Learning: A Methodological and Computational Study
Jun 28, 2020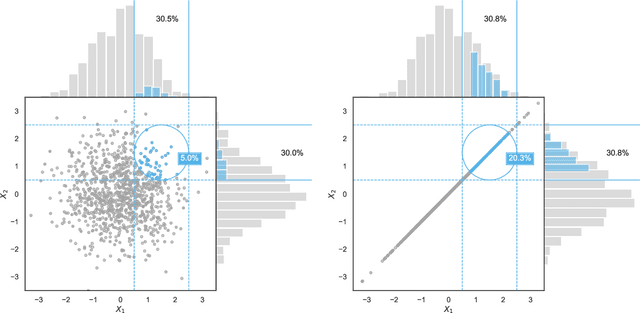
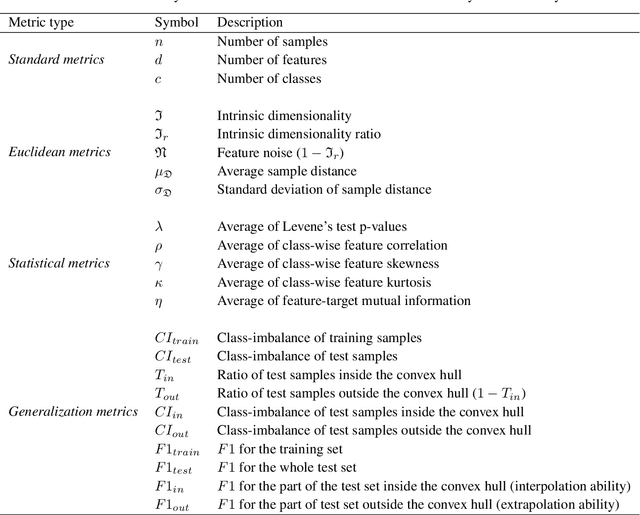
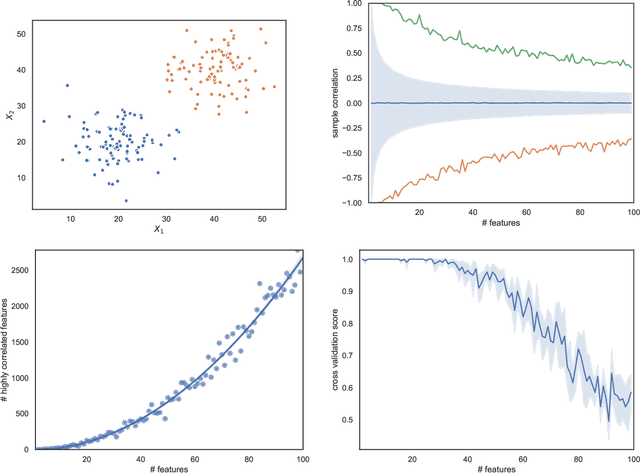
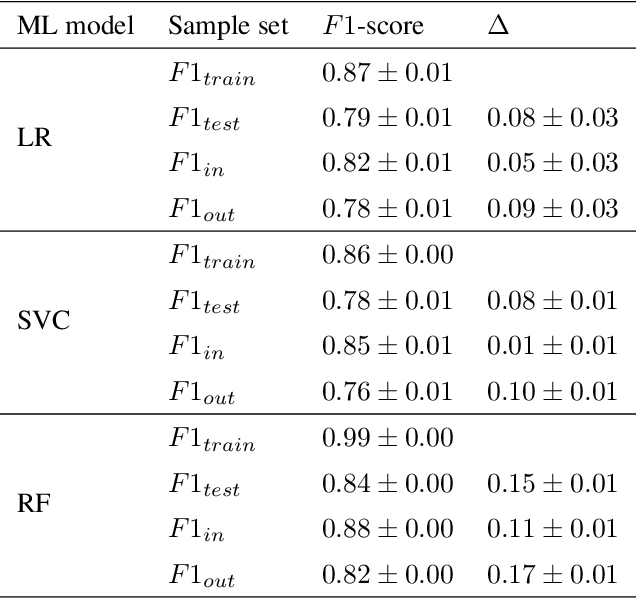
As machine learning becomes more and more available to the general public, theoretical questions are turning into pressing practical issues. Possibly, one of the most relevant concerns is the assessment of our confidence in trusting machine learning predictions. In many real-world cases, it is of utmost importance to estimate the capabilities of a machine learning algorithm to generalize, i.e., to provide accurate predictions on unseen data, depending on the characteristics of the target problem. In this work, we perform a meta-analysis of 109 publicly-available classification data sets, modeling machine learning generalization as a function of a variety of data set characteristics, ranging from number of samples to intrinsic dimensionality, from class-wise feature skewness to $F1$ evaluated on test samples falling outside the convex hull of the training set. Experimental results demonstrate the relevance of using the concept of the convex hull of the training data in assessing machine learning generalization, by emphasizing the difference between interpolated and extrapolated predictions. Besides several predictable correlations, we observe unexpectedly weak associations between the generalization ability of machine learning models and all metrics related to dimensionality, thus challenging the common assumption that the \textit{curse of dimensionality} might impair generalization in machine learning.
Uncovering Coresets for Classification With Multi-Objective Evolutionary Algorithms
Feb 20, 2020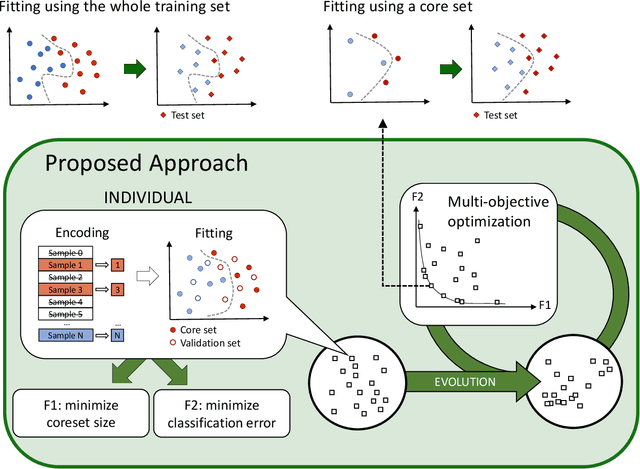
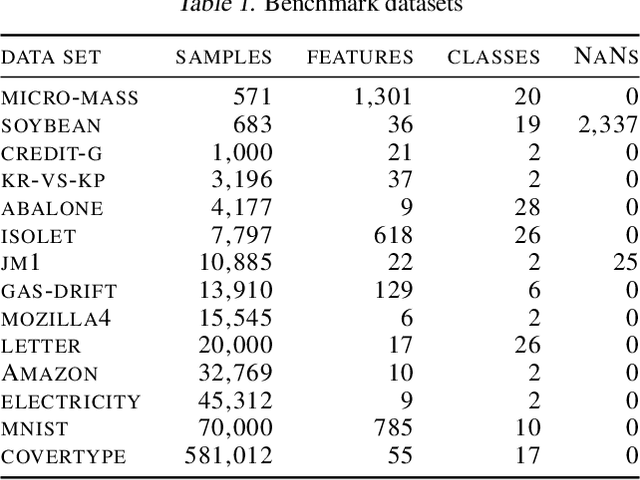
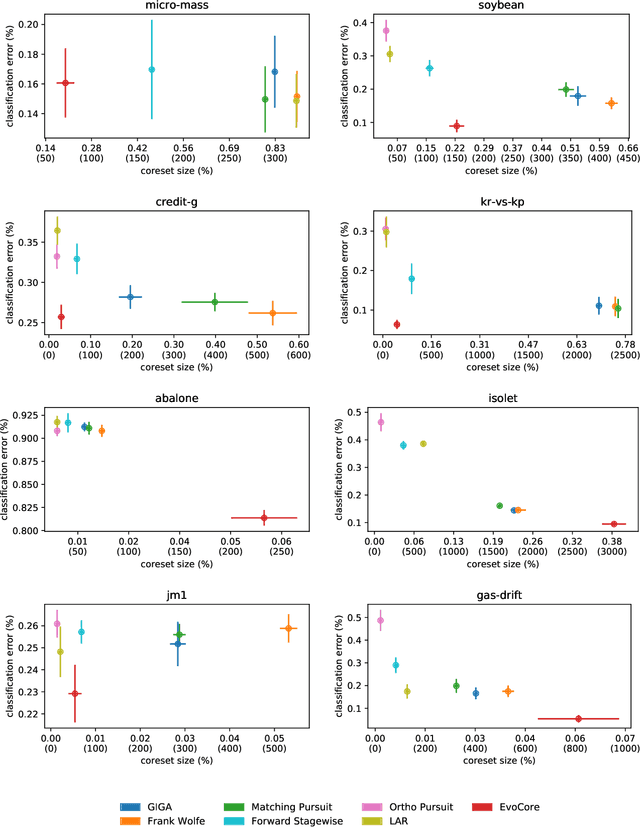
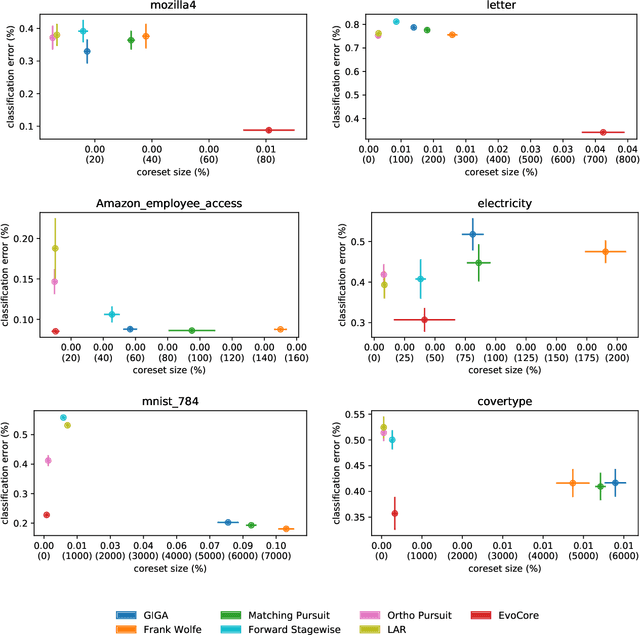
A coreset is a subset of the training set, using which a machine learning algorithm obtains performances similar to what it would deliver if trained over the whole original data. Coreset discovery is an active and open line of research as it allows improving training speed for the algorithms and may help human understanding the results. Building on previous works, a novel approach is presented: candidate corsets are iteratively optimized, adding and removing samples. As there is an obvious trade-off between limiting training size and quality of the results, a multi-objective evolutionary algorithm is used to minimize simultaneously the number of points in the set and the classification error. Experimental results on non-trivial benchmarks show that the proposed approach is able to deliver results that allow a classifier to obtain lower error and better ability of generalizing on unseen data than state-of-the-art coreset discovery techniques.