 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Small Language Models to Reverse-Engineer Machine Learning Pipelines Structures
Jan 07, 2026Background: Extracting the stages that structure Machine Learning (ML) pipelines from source code is key for gaining a deeper understanding of data science practices. However, the diversity caused by the constant evolution of the ML ecosystem (e.g., algorithms, libraries, datasets) makes this task challenging. Existing approaches either depend on non-scalable, manual labeling, or on ML classifiers that do not properly support the diversity of the domain. These limitations highlight the need for more flexible and reliable solutions. Objective: We evaluate whether Small Language Models (SLMs) can leverage their code understanding and classification abilities to address these limitations, and subsequently how they can advance our understanding of data science practices. Method: We conduct a confirmatory study based on two reference works selected for their relevance regarding current state-of-the-art's limitations. First, we compare several SLMs using Cochran's Q test. The best-performing model is then evaluated against the reference studies using two distinct McNemar's tests. We further analyze how variations in taxonomy definitions affect performance through an additional Cochran's Q test. Finally, a goodness-of-fit analysis is conducted using Pearson's chi-squared tests to compare our insights on data science practices with those from prior studies.
MObyGaze: a film dataset of multimodal objectification densely annotated by experts
May 28, 2025



Characterizing and quantifying gender representation disparities in audiovisual storytelling contents is necessary to grasp how stereotypes may perpetuate on screen. In this article, we consider the high-level construct of objectification and introduce a new AI task to the ML community: characterize and quantify complex multimodal (visual, speech, audio) temporal patterns producing objectification in films. Building on film studies and psychology, we define the construct of objectification in a structured thesaurus involving 5 sub-constructs manifesting through 11 concepts spanning 3 modalities. We introduce the Multimodal Objectifying Gaze (MObyGaze) dataset, made of 20 movies annotated densely by experts for objectification levels and concepts over freely delimited segments: it amounts to 6072 segments over 43 hours of video with fine-grained localization and categorization. We formulate different learning tasks, propose and investigate best ways to learn from the diversity of labels among a low number of annotators, and benchmark recent vision, text and audio models, showing the feasibility of the task. We make our code and our dataset available to the community and described in the Croissant format: https://anonymous.4open.science/r/MObyGaze-F600/.
Layerwise Early Stopping for Test Time Adaptation
Apr 04, 2024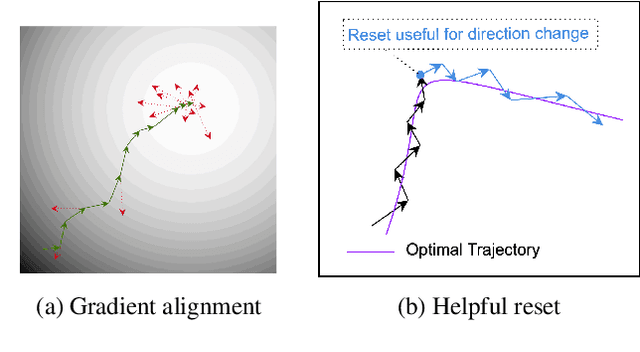



Test Time Adaptation (TTA) addresses the problem of distribution shift by enabling pretrained models to learn new features on an unseen domain at test time. However, it poses a significant challenge to maintain a balance between learning new features and retaining useful pretrained features. In this paper, we propose Layerwise EArly STopping (LEAST) for TTA to address this problem. The key idea is to stop adapting individual layers during TTA if the features being learned do not appear beneficial for the new domain. For that purpose, we propose using a novel gradient-based metric to measure the relevance of the current learnt features to the new domain without the need for supervised labels. More specifically, we propose to use this metric to determine dynamically when to stop updating each layer during TTA. This enables a more balanced adaptation, restricted to layers benefiting from it, and only for a certain number of steps. Such an approach also has the added effect of limiting the forgetting of pretrained features useful for dealing with new domains. Through extensive experiments, we demonstrate that Layerwise Early Stopping improves the performance of existing TTA approaches across multiple datasets, domain shifts, model architectures, and TTA losses.
Attention Meets Post-hoc Interpretability: A Mathematical Perspective
Feb 05, 2024
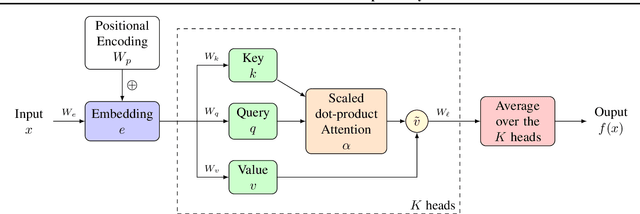
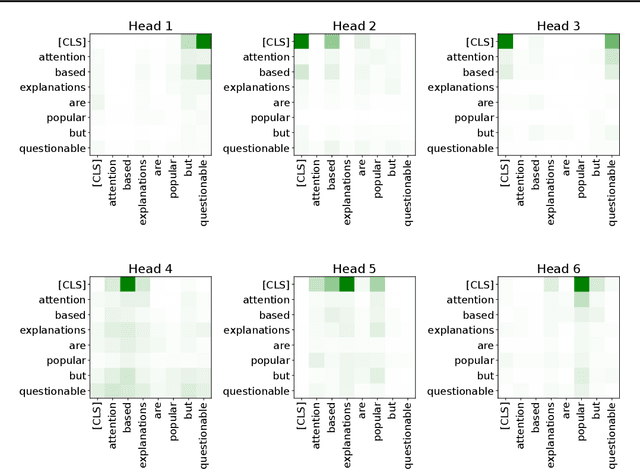
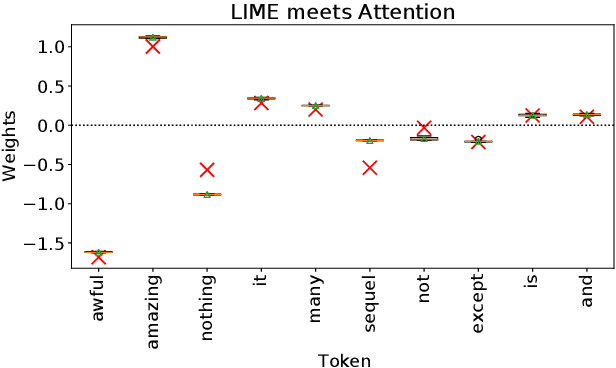
Attention-based architectures, in particular transformers, are at the heart of a technological revolution. Interestingly, in addition to helping obtain state-of-the-art results on a wide range of applications, the attention mechanism intrinsically provides meaningful insights on the internal behavior of the model. Can these insights be used as explanations? Debate rages on. In this paper, we mathematically study a simple attention-based architecture and pinpoint the differences between post-hoc and attention-based explanations. We show that they provide quite different results, and that, despite their limitations, post-hoc methods are capable of capturing more useful insights than merely examining the attention weights.
Visual Objectification in Films: Towards a New AI Task for Video Interpretation
Jan 24, 2024
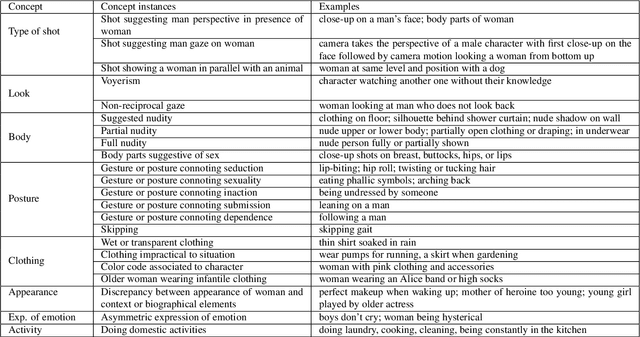
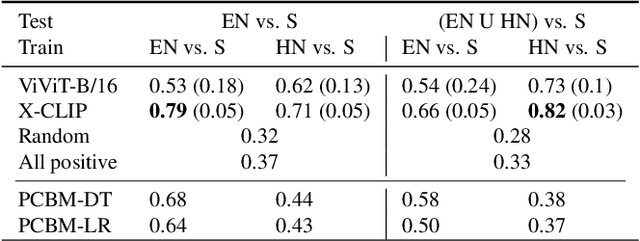
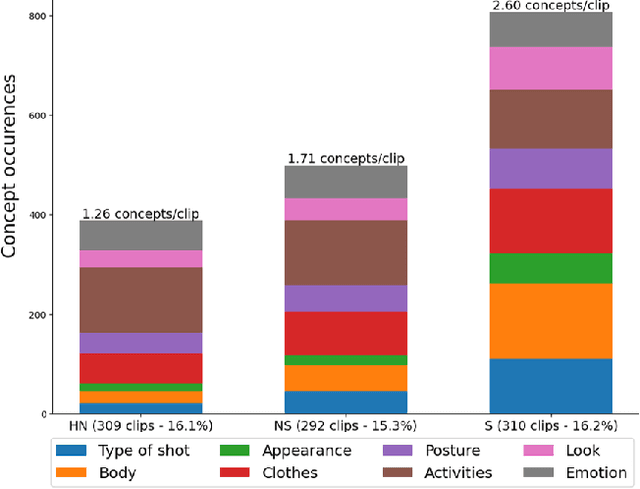
In film gender studies, the concept of 'male gaze' refers to the way the characters are portrayed on-screen as objects of desire rather than subjects. In this article, we introduce a novel video-interpretation task, to detect character objectification in films. The purpose is to reveal and quantify the usage of complex temporal patterns operated in cinema to produce the cognitive perception of objectification. We introduce the ObyGaze12 dataset, made of 1914 movie clips densely annotated by experts for objectification concepts identified in film studies and psychology. We evaluate recent vision models, show the feasibility of the task and where the challenges remain with concept bottleneck models. Our new dataset and code are made available to the community.
Faithful and Robust Local Interpretability for Textual Predictions
Oct 30, 2023Interpretability is essential for machine learning models to be trusted and deployed in critical domains. However, existing methods for interpreting text models are often complex, lack solid mathematical foundations, and their performance is not guaranteed. In this paper, we propose FRED (Faithful and Robust Explainer for textual Documents), a novel method for interpreting predictions over text. FRED identifies key words in a document that significantly impact the prediction when removed. We establish the reliability of FRED through formal definitions and theoretical analyses on interpretable classifiers. Additionally, our empirical evaluation against state-of-the-art methods demonstrates the effectiveness of FRED in providing insights into text models.
Interpretable Neural-Symbolic Concept Reasoning
Apr 27, 2023



Deep learning methods are highly accurate, yet their opaque decision process prevents them from earning full human trust. Concept-based models aim to address this issue by learning tasks based on a set of human-understandable concepts. However, state-of-the-art concept-based models rely on high-dimensional concept embedding representations which lack a clear semantic meaning, thus questioning the interpretability of their decision process. To overcome this limitation, we propose the Deep Concept Reasoner (DCR), the first interpretable concept-based model that builds upon concept embeddings. In DCR, neural networks do not make task predictions directly, but they build syntactic rule structures using concept embeddings. DCR then executes these rules on meaningful concept truth degrees to provide a final interpretable and semantically-consistent prediction in a differentiable manner. Our experiments show that DCR: (i) improves up to +25% w.r.t. state-of-the-art interpretable concept-based models on challenging benchmarks (ii) discovers meaningful logic rules matching known ground truths even in the absence of concept supervision during training, and (iii), facilitates the generation of counterfactual examples providing the learnt rules as guidance.
Understanding Post-hoc Explainers: The Case of Anchors
Mar 15, 2023In many scenarios, the interpretability of machine learning models is a highly required but difficult task. To explain the individual predictions of such models, local model-agnostic approaches have been proposed. However, the process generating the explanations can be, for a user, as mysterious as the prediction to be explained. Furthermore, interpretability methods frequently lack theoretical guarantees, and their behavior on simple models is frequently unknown. While it is difficult, if not impossible, to ensure that an explainer behaves as expected on a cutting-edge model, we can at least ensure that everything works on simple, already interpretable models. In this paper, we present a theoretical analysis of Anchors (Ribeiro et al., 2018): a popular rule-based interpretability method that highlights a small set of words to explain a text classifier's decision. After formalizing its algorithm and providing useful insights, we demonstrate mathematically that Anchors produces meaningful results when used with linear text classifiers on top of a TF-IDF vectorization. We believe that our analysis framework can aid in the development of new explainability methods based on solid theoretical foundations.
Generalised Mutual Information for Discriminative Clustering
Oct 14, 2022

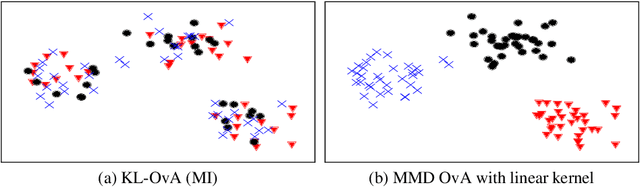
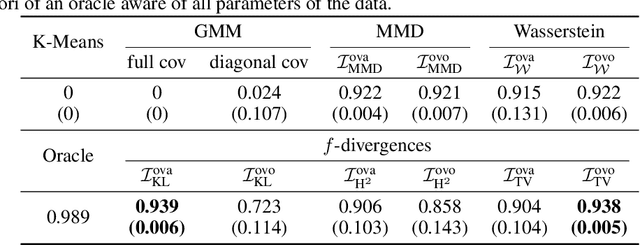
In the last decade, recent successes in deep clustering majorly involved the mutual information (MI) as an unsupervised objective for training neural networks with increasing regularisations. While the quality of the regularisations have been largely discussed for improvements, little attention has been dedicated to the relevance of MI as a clustering objective. In this paper, we first highlight how the maximisation of MI does not lead to satisfying clusters. We identified the Kullback-Leibler divergence as the main reason of this behaviour. Hence, we generalise the mutual information by changing its core distance, introducing the generalised mutual information (GEMINI): a set of metrics for unsupervised neural network training. Unlike MI, some GEMINIs do not require regularisations when training. Some of these metrics are geometry-aware thanks to distances or kernels in the data space. Finally, we highlight that GEMINIs can automatically select a relevant number of clusters, a property that has been little studied in deep clustering context where the number of clusters is a priori unknown.
Concept Embedding Models
Sep 19, 2022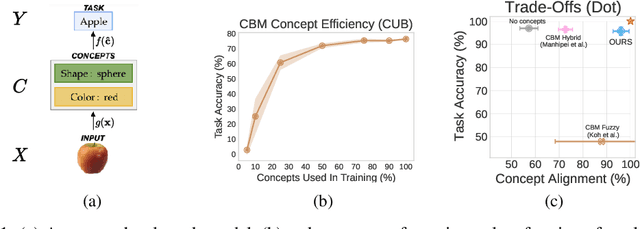

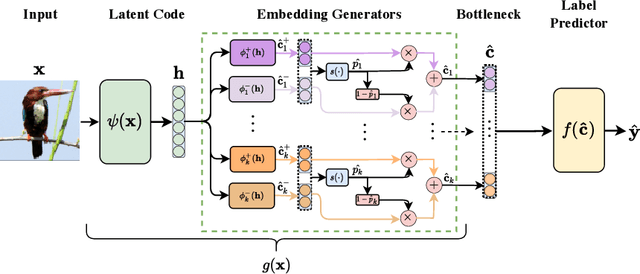

Deploying AI-powered systems requires trustworthy models supporting effective human interactions, going beyond raw prediction accuracy. Concept bottleneck models promote trustworthiness by conditioning classification tasks on an intermediate level of human-like concepts. This enables human interventions which can correct mispredicted concepts to improve the model's performance. However, existing concept bottleneck models are unable to find optimal compromises between high task accuracy, robust concept-based explanations, and effective interventions on concepts -- particularly in real-world conditions where complete and accurate concept supervisions are scarce. To address this, we propose Concept Embedding Models, a novel family of concept bottleneck models which goes beyond the current accuracy-vs-interpretability trade-off by learning interpretable high-dimensional concept representations. Our experiments demonstrate that Concept Embedding Models (1) attain better or competitive task accuracy w.r.t. standard neural models without concepts, (2) provide concept representations capturing meaningful semantics including and beyond their ground truth labels, (3) support test-time concept interventions whose effect in test accuracy surpasses that in standard concept bottleneck models, and (4) scale to real-world conditions where complete concept supervisions are scarce.