 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStick-Breaking Embedded Topic Model with Continuous Optimal Transport for Online Analysis of Document Streams
Oct 21, 2025Online topic models are unsupervised algorithms to identify latent topics in data streams that continuously evolve over time. Although these methods naturally align with real-world scenarios, they have received considerably less attention from the community compared to their offline counterparts, due to specific additional challenges. To tackle these issues, we present SB-SETM, an innovative model extending the Embedded Topic Model (ETM) to process data streams by merging models formed on successive partial document batches. To this end, SB-SETM (i) leverages a truncated stick-breaking construction for the topic-per-document distribution, enabling the model to automatically infer from the data the appropriate number of active topics at each timestep; and (ii) introduces a merging strategy for topic embeddings based on a continuous formulation of optimal transport adapted to the high dimensionality of the latent topic space. Numerical experiments show SB-SETM outperforming baselines on simulated scenarios. We extensively test it on a real-world corpus of news articles covering the Russian-Ukrainian war throughout 2022-2023.
Parsimonious Gaussian mixture models with piecewise-constant eigenvalue profiles
Jul 02, 2025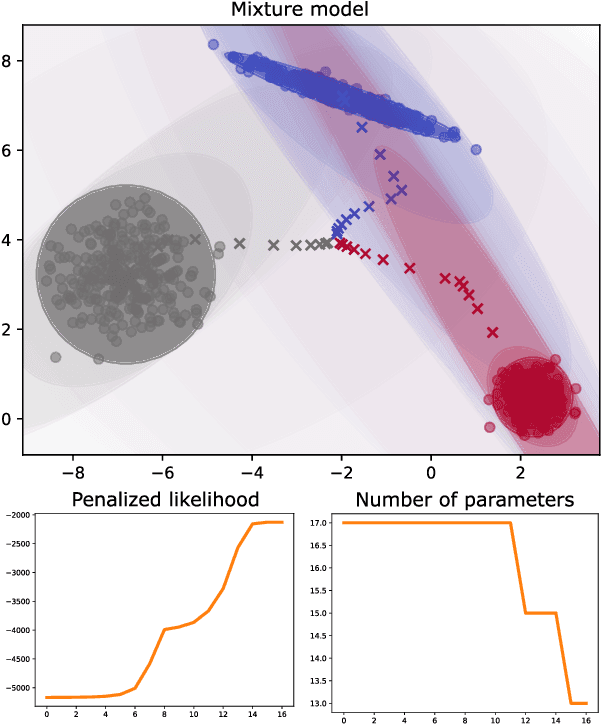



Gaussian mixture models (GMMs) are ubiquitous in statistical learning, particularly for unsupervised problems. While full GMMs suffer from the overparameterization of their covariance matrices in high-dimensional spaces, spherical GMMs (with isotropic covariance matrices) certainly lack flexibility to fit certain anisotropic distributions. Connecting these two extremes, we introduce a new family of parsimonious GMMs with piecewise-constant covariance eigenvalue profiles. These extend several low-rank models like the celebrated mixtures of probabilistic principal component analyzers (MPPCA), by enabling any possible sequence of eigenvalue multiplicities. If the latter are prespecified, then we can naturally derive an expectation-maximization (EM) algorithm to learn the mixture parameters. Otherwise, to address the notoriously-challenging issue of jointly learning the mixture parameters and hyperparameters, we propose a componentwise penalized EM algorithm, whose monotonicity is proven. We show the superior likelihood-parsimony tradeoffs achieved by our models on a variety of unsupervised experiments: density fitting, clustering and single-image denoising.
Merging Embedded Topics with Optimal Transport for Online Topic Modeling on Data Streams
Apr 10, 2025



Topic modeling is a key component in unsupervised learning, employed to identify topics within a corpus of textual data. The rapid growth of social media generates an ever-growing volume of textual data daily, making online topic modeling methods essential for managing these data streams that continuously arrive over time. This paper introduces a novel approach to online topic modeling named StreamETM. This approach builds on the Embedded Topic Model (ETM) to handle data streams by merging models learned on consecutive partial document batches using unbalanced optimal transport. Additionally, an online change point detection algorithm is employed to identify shifts in topics over time, enabling the identification of significant changes in the dynamics of text streams. Numerical experiments on simulated and real-world data show StreamETM outperforming competitors.
Generalised Mutual Information: a Framework for Discriminative Clustering
Sep 06, 2023



In the last decade, recent successes in deep clustering majorly involved the Mutual Information (MI) as an unsupervised objective for training neural networks with increasing regularisations. While the quality of the regularisations have been largely discussed for improvements, little attention has been dedicated to the relevance of MI as a clustering objective. In this paper, we first highlight how the maximisation of MI does not lead to satisfying clusters. We identified the Kullback-Leibler divergence as the main reason of this behaviour. Hence, we generalise the mutual information by changing its core distance, introducing the Generalised Mutual Information (GEMINI): a set of metrics for unsupervised neural network training. Unlike MI, some GEMINIs do not require regularisations when training as they are geometry-aware thanks to distances or kernels in the data space. Finally, we highlight that GEMINIs can automatically select a relevant number of clusters, a property that has been little studied in deep discriminative clustering context where the number of clusters is a priori unknown.
The Deep Latent Position Topic Model for Clustering and Representation of Networks with Textual Edges
Apr 14, 2023Numerical interactions leading to users sharing textual content published by others are naturally represented by a network where the individuals are associated with the nodes and the exchanged texts with the edges. To understand those heterogeneous and complex data structures, clustering nodes into homogeneous groups as well as rendering a comprehensible visualisation of the data is mandatory. To address both issues, we introduce Deep-LPTM, a model-based clustering strategy relying on a variational graph auto-encoder approach as well as a probabilistic model to characterise the topics of discussion. Deep-LPTM allows to build a joint representation of the nodes and of the edges in two embeddings spaces. The parameters are inferred using a variational inference algorithm. We also introduce IC2L, a model selection criterion specifically designed to choose models with relevant clustering and visualisation properties. An extensive benchmark study on synthetic data is provided. In particular, we find that Deep-LPTM better recovers the partitions of the nodes than the state-of-the art ETSBM and STBM. Eventually, the emails of the Enron company are analysed and visualisations of the results are presented, with meaningful highlights of the graph structure.
Are labels informative in semi-supervised learning? -- Estimating and leveraging the missing-data mechanism
Feb 15, 2023Semi-supervised learning is a powerful technique for leveraging unlabeled data to improve machine learning models, but it can be affected by the presence of ``informative'' labels, which occur when some classes are more likely to be labeled than others. In the missing data literature, such labels are called missing not at random. In this paper, we propose a novel approach to address this issue by estimating the missing-data mechanism and using inverse propensity weighting to debias any SSL algorithm, including those using data augmentation. We also propose a likelihood ratio test to assess whether or not labels are indeed informative. Finally, we demonstrate the performance of the proposed methods on different datasets, in particular on two medical datasets for which we design pseudo-realistic missing data scenarios.
Sparse GEMINI for Joint Discriminative Clustering and Feature Selection
Feb 07, 2023Feature selection in clustering is a hard task which involves simultaneously the discovery of relevant clusters as well as relevant variables with respect to these clusters. While feature selection algorithms are often model-based through optimised model selection or strong assumptions on $p(\pmb{x})$, we introduce a discriminative clustering model trying to maximise a geometry-aware generalisation of the mutual information called GEMINI with a simple $\ell_1$ penalty: the Sparse GEMINI. This algorithm avoids the burden of combinatorial feature subset exploration and is easily scalable to high-dimensional data and large amounts of samples while only designing a clustering model $p_\theta(y|\pmb{x})$. We demonstrate the performances of Sparse GEMINI on synthetic datasets as well as large-scale datasets. Our results show that Sparse GEMINI is a competitive algorithm and has the ability to select relevant subsets of variables with respect to the clustering without using relevance criteria or prior hypotheses.
Generalised Mutual Information for Discriminative Clustering
Oct 14, 2022

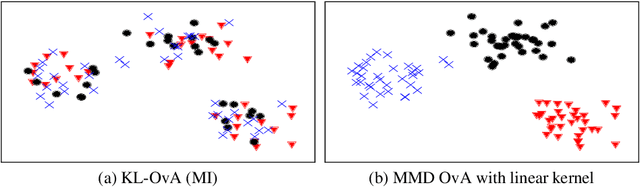
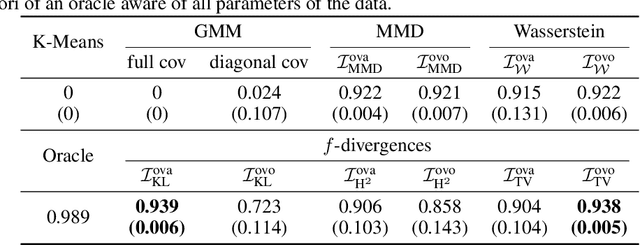
In the last decade, recent successes in deep clustering majorly involved the mutual information (MI) as an unsupervised objective for training neural networks with increasing regularisations. While the quality of the regularisations have been largely discussed for improvements, little attention has been dedicated to the relevance of MI as a clustering objective. In this paper, we first highlight how the maximisation of MI does not lead to satisfying clusters. We identified the Kullback-Leibler divergence as the main reason of this behaviour. Hence, we generalise the mutual information by changing its core distance, introducing the generalised mutual information (GEMINI): a set of metrics for unsupervised neural network training. Unlike MI, some GEMINIs do not require regularisations when training. Some of these metrics are geometry-aware thanks to distances or kernels in the data space. Finally, we highlight that GEMINIs can automatically select a relevant number of clusters, a property that has been little studied in deep clustering context where the number of clusters is a priori unknown.
Active Speaker Detection as a Multi-Objective Optimization with Uncertainty-based Multimodal Fusion
Jun 07, 2021
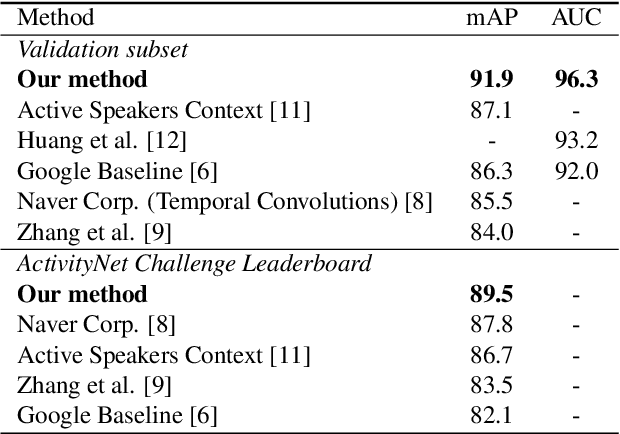
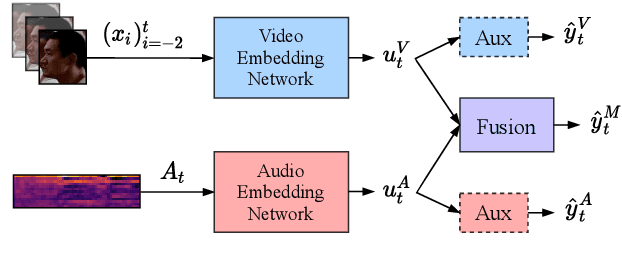
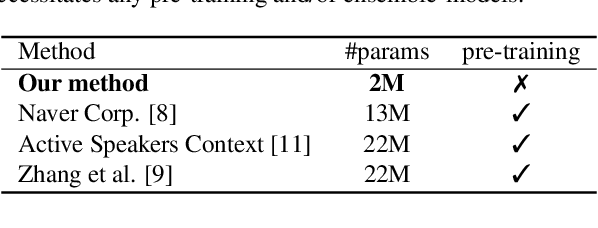
It is now well established from a variety of studies that there is a significant benefit from combining video and audio data in detecting active speakers. However, either of the modalities can potentially mislead audiovisual fusion by inducing unreliable or deceptive information. This paper outlines active speaker detection as a multi-objective learning problem to leverage best of each modalities using a novel self-attention, uncertainty-based multimodal fusion scheme. Results obtained show that the proposed multi-objective learning architecture outperforms traditional approaches in improving both mAP and AUC scores. We further demonstrate that our fusion strategy surpasses, in active speaker detection, other modality fusion methods reported in various disciplines. We finally show that the proposed method significantly improves the state-of-the-art on the AVA-ActiveSpeaker dataset.
Unobserved classes and extra variables in high-dimensional discriminant analysis
Feb 03, 2021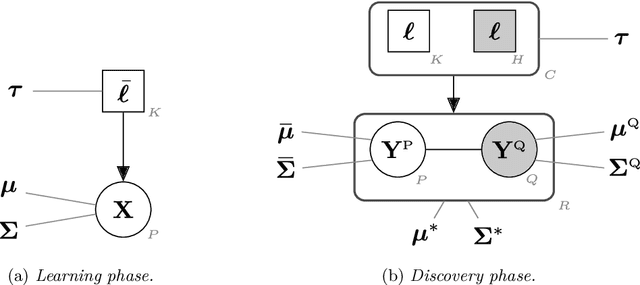
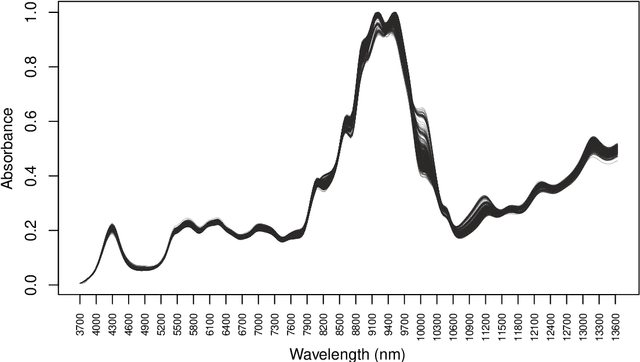
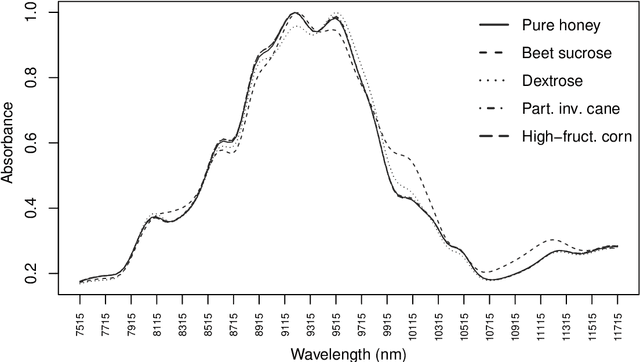
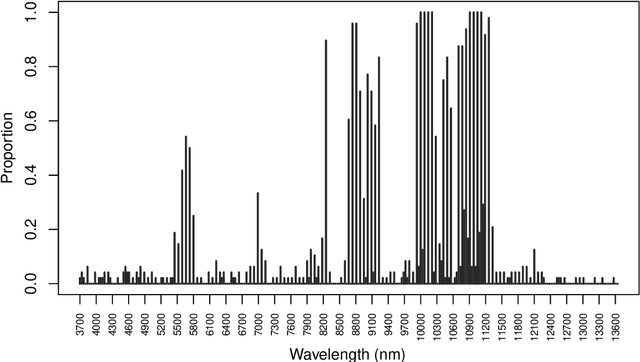
In supervised classification problems, the test set may contain data points belonging to classes not observed in the learning phase. Moreover, the same units in the test data may be measured on a set of additional variables recorded at a subsequent stage with respect to when the learning sample was collected. In this situation, the classifier built in the learning phase needs to adapt to handle potential unknown classes and the extra dimensions. We introduce a model-based discriminant approach, Dimension-Adaptive Mixture Discriminant Analysis (D-AMDA), which can detect unobserved classes and adapt to the increasing dimensionality. Model estimation is carried out via a full inductive approach based on an EM algorithm. The method is then embedded in a more general framework for adaptive variable selection and classification suitable for data of large dimensions. A simulation study and an artificial experiment related to classification of adulterated honey samples are used to validate the ability of the proposed framework to deal with complex situations.