 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards More General Control of Diffusion Models Using Jeffrey Guidance
Jun 11, 2026A key strength of diffusion models lies in their flexibility, since their outputs can be controlled at sampling time through guidance. However, beyond simple cases such as conditional sampling, the target distribution is often left implicit, defined only through a sampling rule or a heuristic energy function. To address this, we propose Jeffrey guidance, a principled framework that extends diffusion-model control to applications beyond what standard guidance can express. It leverages Jeffrey's rule of conditioning to update marginal distributions towards a prescribed target, preserving the conditional structure and minimally perturbing the joint distribution. We first demonstrate Jeffrey guidance by targeting a prescribed embedding distribution. With Inception embeddings as the target, this leads to substantial reductions in FID on both CIFAR-10 and FFHQ. We further apply Jeffrey guidance to fairness on CelebA-HQ, updating an unconditional diffusion model to enforce independence between attributes.
Beyond Mixtures and Products for Ensemble Aggregation: A Likelihood Perspective on Generalized Means
Mar 04, 2026Density aggregation is a central problem in machine learning, for instance when combining predictions from a Deep Ensemble. The choice of aggregation remains an open question with two commonly proposed approaches being linear pooling (probability averaging) and geometric pooling (logit averaging). In this work, we address this question by studying the normalized generalized mean of order $r \in \mathbb{R} \cup \{-\infty,+\infty\}$ through the lens of log-likelihood, the standard evaluation criterion in machine learning. This provides a unifying aggregation formalism and shows different optimal configurations for different situations. We show that the regime $r \in [0,1]$ is the only range ensuring systematic improvements relative to individual distributions, thereby providing a principled justification for the reliability and widespread practical use of linear ($r=1$) and geometric ($r=0$) pooling. In contrast, we show that aggregation rules with $r \notin [0,1]$ may fail to provide consistent gains with explicit counterexamples. Finally, we corroborate our theoretical findings with empirical evaluations using Deep Ensembles on image and text classification benchmarks.
When Are Two Scores Better Than One? Investigating Ensembles of Diffusion Models
Jan 16, 2026Diffusion models now generate high-quality, diverse samples, with an increasing focus on more powerful models. Although ensembling is a well-known way to improve supervised models, its application to unconditional score-based diffusion models remains largely unexplored. In this work we investigate whether it provides tangible benefits for generative modelling. We find that while ensembling the scores generally improves the score-matching loss and model likelihood, it fails to consistently enhance perceptual quality metrics such as FID on image datasets. We confirm this observation across a breadth of aggregation rules using Deep Ensembles, Monte Carlo Dropout, on CIFAR-10 and FFHQ. We attempt to explain this discrepancy by investigating possible explanations, such as the link between score estimation and image quality. We also look into tabular data through random forests, and find that one aggregation strategy outperforms the others. Finally, we provide theoretical insights into the summing of score models, which shed light not only on ensembling but also on several model composition techniques (e.g. guidance).
A Tutorial on Discriminative Clustering and Mutual Information
May 07, 2025To cluster data is to separate samples into distinctive groups that should ideally have some cohesive properties. Today, numerous clustering algorithms exist, and their differences lie essentially in what can be perceived as ``cohesive properties''. Therefore, hypotheses on the nature of clusters must be set: they can be either generative or discriminative. As the last decade witnessed the impressive growth of deep clustering methods that involve neural networks to handle high-dimensional data often in a discriminative manner; we concentrate mainly on the discriminative hypotheses. In this paper, our aim is to provide an accessible historical perspective on the evolution of discriminative clustering methods and notably how the nature of assumptions of the discriminative models changed over time: from decision boundaries to invariance critics. We notably highlight how mutual information has been a historical cornerstone of the progress of (deep) discriminative clustering methods. We also show some known limitations of mutual information and how discriminative clustering methods tried to circumvent those. We then discuss the challenges that discriminative clustering faces with respect to the selection of the number of clusters. Finally, we showcase these techniques using the dedicated Python package, GemClus, that we have developed for discriminative clustering.
Leveraging multimodal explanatory annotations for video interpretation with Modality Specific Dataset
Apr 15, 2025We examine the impact of concept-informed supervision on multimodal video interpretation models using MOByGaze, a dataset containing human-annotated explanatory concepts. We introduce Concept Modality Specific Datasets (CMSDs), which consist of data subsets categorized by the modality (visual, textual, or audio) of annotated concepts. Models trained on CMSDs outperform those using traditional legacy training in both early and late fusion approaches. Notably, this approach enables late fusion models to achieve performance close to that of early fusion models. These findings underscore the importance of modality-specific annotations in developing robust, self-explainable video models and contribute to advancing interpretable multimodal learning in complex video analysis.
Domain-specific long text classification from sparse relevant information
Aug 23, 2024Large Language Models have undoubtedly revolutionized the Natural Language Processing field, the current trend being to promote one-model-for-all tasks (sentiment analysis, translation, etc.). However, the statistical mechanisms at work in the larger language models struggle to exploit the relevant information when it is very sparse, when it is a weak signal. This is the case, for example, for the classification of long domain-specific documents, when the relevance relies on a single relevant word or on very few relevant words from technical jargon. In the medical domain, it is essential to determine whether a given report contains critical information about a patient's condition. This critical information is often based on one or few specific isolated terms. In this paper, we propose a hierarchical model which exploits a short list of potential target terms to retrieve candidate sentences and represent them into the contextualized embedding of the target term(s) they contain. A pooling of the term(s) embedding(s) entails the document representation to be classified. We evaluate our model on one public medical document benchmark in English and on one private French medical dataset. We show that our narrower hierarchical model is better than larger language models for retrieving relevant long documents in a domain-specific context.
Detecting Brittle Decisions for Free: Leveraging Margin Consistency in Deep Robust Classifiers
Jun 26, 2024Despite extensive research on adversarial training strategies to improve robustness, the decisions of even the most robust deep learning models can still be quite sensitive to imperceptible perturbations, creating serious risks when deploying them for high-stakes real-world applications. While detecting such cases may be critical, evaluating a model's vulnerability at a per-instance level using adversarial attacks is computationally too intensive and unsuitable for real-time deployment scenarios. The input space margin is the exact score to detect non-robust samples and is intractable for deep neural networks. This paper introduces the concept of margin consistency -- a property that links the input space margins and the logit margins in robust models -- for efficient detection of vulnerable samples. First, we establish that margin consistency is a necessary and sufficient condition to use a model's logit margin as a score for identifying non-robust samples. Next, through comprehensive empirical analysis of various robustly trained models on CIFAR10 and CIFAR100 datasets, we show that they indicate strong margin consistency with a strong correlation between their input space margins and the logit margins. Then, we show that we can effectively use the logit margin to confidently detect brittle decisions with such models and accurately estimate robust accuracy on an arbitrarily large test set by estimating the input margins only on a small subset. Finally, we address cases where the model is not sufficiently margin-consistent by learning a pseudo-margin from the feature representation. Our findings highlight the potential of leveraging deep representations to efficiently assess adversarial vulnerability in deployment scenarios.
Kernel KMeans clustering splits for end-to-end unsupervised decision trees
Feb 19, 2024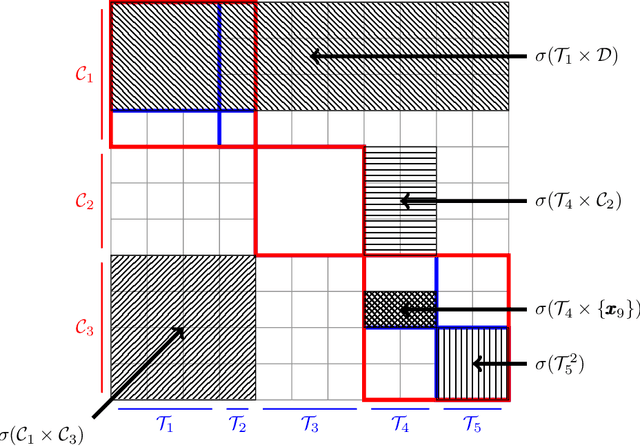
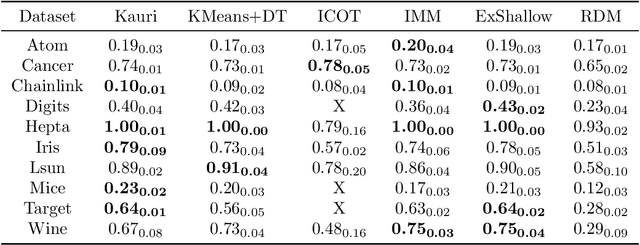
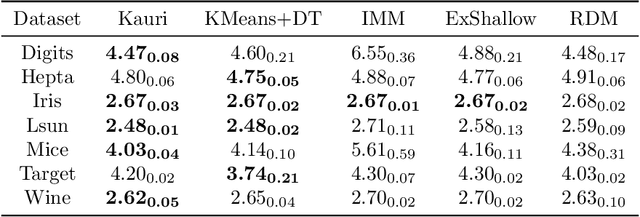
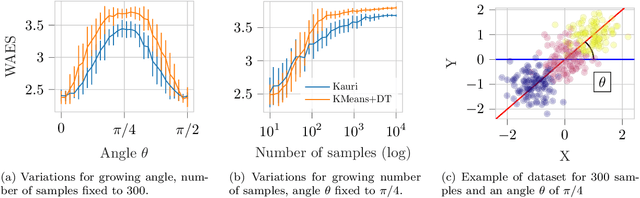
Trees are convenient models for obtaining explainable predictions on relatively small datasets. Although there are many proposals for the end-to-end construction of such trees in supervised learning, learning a tree end-to-end for clustering without labels remains an open challenge. As most works focus on interpreting with trees the result of another clustering algorithm, we present here a novel end-to-end trained unsupervised binary tree for clustering: Kauri. This method performs a greedy maximisation of the kernel KMeans objective without requiring the definition of centroids. We compare this model on multiple datasets with recent unsupervised trees and show that Kauri performs identically when using a linear kernel. For other kernels, Kauri often outperforms the concatenation of kernel KMeans and a CART decision tree.
Mind the map! Accounting for existing map information when estimating online HDMaps from sensor data
Nov 17, 2023Online High Definition Map (HDMap) estimation from sensors offers a low-cost alternative to manually acquired HDMaps. As such, it promises to lighten costs for already HDMap-reliant Autonomous Driving systems, and potentially even spread their use to new systems. In this paper, we propose to improve online HDMap estimation by accounting for already existing maps. We identify 3 reasonable types of useful existing maps (minimalist, noisy, and outdated). We also introduce MapEX, a novel online HDMap estimation framework that accounts for existing maps. MapEX achieves this by encoding map elements into query tokens and by refining the matching algorithm used to train classic query based map estimation models. We demonstrate that MapEX brings significant improvements on the nuScenes dataset. For instance, MapEX - given noisy maps - improves by 38% over the MapTRv2 detector it is based on and by 16% over the current SOTA.
Generalised Mutual Information: a Framework for Discriminative Clustering
Sep 06, 2023



In the last decade, recent successes in deep clustering majorly involved the Mutual Information (MI) as an unsupervised objective for training neural networks with increasing regularisations. While the quality of the regularisations have been largely discussed for improvements, little attention has been dedicated to the relevance of MI as a clustering objective. In this paper, we first highlight how the maximisation of MI does not lead to satisfying clusters. We identified the Kullback-Leibler divergence as the main reason of this behaviour. Hence, we generalise the mutual information by changing its core distance, introducing the Generalised Mutual Information (GEMINI): a set of metrics for unsupervised neural network training. Unlike MI, some GEMINIs do not require regularisations when training as they are geometry-aware thanks to distances or kernels in the data space. Finally, we highlight that GEMINIs can automatically select a relevant number of clusters, a property that has been little studied in deep discriminative clustering context where the number of clusters is a priori unknown.