 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-specific long text classification from sparse relevant information
Aug 23, 2024Large Language Models have undoubtedly revolutionized the Natural Language Processing field, the current trend being to promote one-model-for-all tasks (sentiment analysis, translation, etc.). However, the statistical mechanisms at work in the larger language models struggle to exploit the relevant information when it is very sparse, when it is a weak signal. This is the case, for example, for the classification of long domain-specific documents, when the relevance relies on a single relevant word or on very few relevant words from technical jargon. In the medical domain, it is essential to determine whether a given report contains critical information about a patient's condition. This critical information is often based on one or few specific isolated terms. In this paper, we propose a hierarchical model which exploits a short list of potential target terms to retrieve candidate sentences and represent them into the contextualized embedding of the target term(s) they contain. A pooling of the term(s) embedding(s) entails the document representation to be classified. We evaluate our model on one public medical document benchmark in English and on one private French medical dataset. We show that our narrower hierarchical model is better than larger language models for retrieving relevant long documents in a domain-specific context.
AnoRand: A Semi Supervised Deep Learning Anomaly Detection Method by Random Labeling
May 28, 2023



Anomaly detection or more generally outliers detection is one of the most popular and challenging subject in theoretical and applied machine learning. The main challenge is that in general we have access to very few labeled data or no labels at all. In this paper, we present a new semi-supervised anomaly detection method called \textbf{AnoRand} by combining a deep learning architecture with random synthetic label generation. The proposed architecture has two building blocks: (1) a noise detection (ND) block composed of feed forward ferceptron and (2) an autoencoder (AE) block. The main idea of this new architecture is to learn one class (e.g. the majority class in case of anomaly detection) as well as possible by taking advantage of the ability of auto encoders to represent data in a latent space and the ability of Feed Forward Perceptron (FFP) to learn one class when the data is highly imbalanced. First, we create synthetic anomalies by randomly disturbing (add noise) few samples (e.g. 2\%) from the training set. Second, we use the normal and the synthetic samples as input to our model. We compared the performance of the proposed method to 17 state-of-the-art unsupervised anomaly detection method on synthetic datasets and 57 real-world datasets. Our results show that this new method generally outperforms most of the state-of-the-art methods and has the best performance (AUC ROC and AUC PR) on the vast majority of reference datasets. We also tested our method in a supervised way by using the actual labels to train the model. The results show that it has very good performance compared to most of state-of-the-art supervised algorithms.
Multiple Inputs Neural Networks for Medicare fraud Detection
Mar 11, 2022

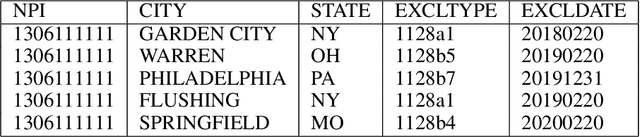
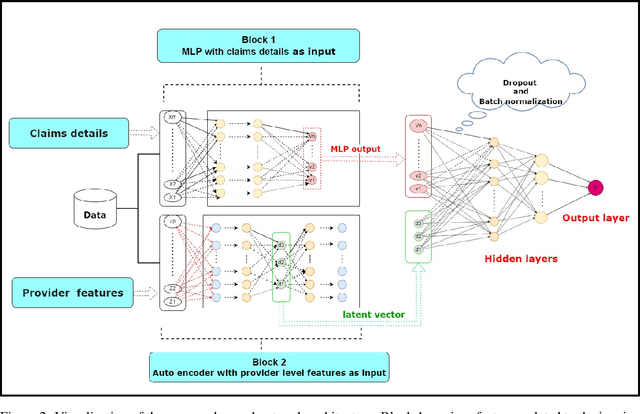
Medicare fraud results in considerable losses for governments and insurance companies and results in higher premiums from clients. Medicare fraud costs around 13 billion euros in Europe and between 21 billion and 71 billion US dollars per year in the United States. This study aims to use artificial neural network based classifiers to predict medicare fraud. The main difficulty using machine learning techniques in fraud detection or more generally anomaly detection is that the data sets are highly imbalanced. To detect medicare frauds, we propose a multiple inputs deep neural network based classifier with a Long-short Term Memory (LSTM) autoencoder component. This architecture makes it possible to take into account many sources of data without mixing them and makes the classification task easier for the final model. The latent features extracted from the LSTM autoencoder have a strong discriminating power and separate the providers into homogeneous clusters. We use the data sets from the Centers for Medicaid and Medicare Services (CMS) of the US federal government. The CMS provides publicly available data that brings together all of the cost price requests sent by American hospitals to medicare companies. Our results show that although baseline artificial neural network give good performances, they are outperformed by our multiple inputs neural networks. We have shown that using a LSTM autoencoder to embed the provider behavior gives better results and makes the classifiers more robust to class imbalance.
Autoregressive based Drift Detection Method
Mar 09, 2022
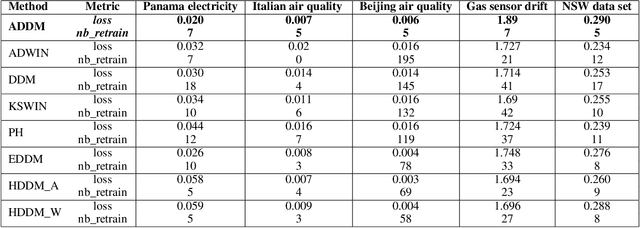
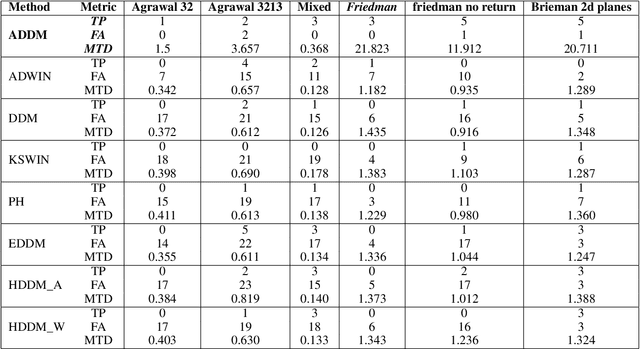
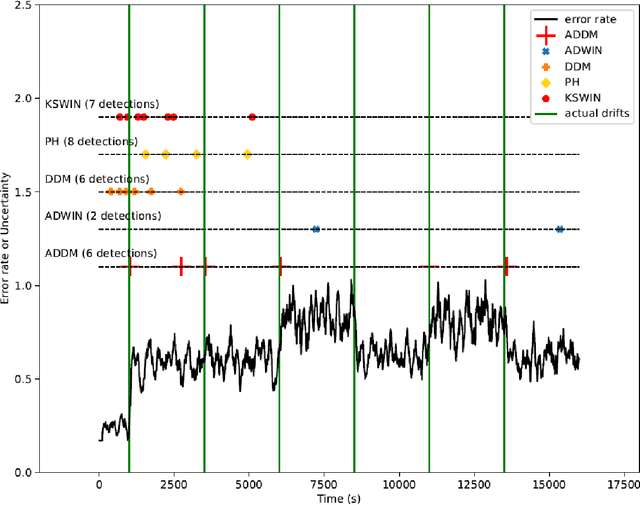
In the classic machine learning framework, models are trained on historical data and used to predict future values. It is assumed that the data distribution does not change over time (stationarity). However, in real-world scenarios, the data generation process changes over time and the model has to adapt to the new incoming data. This phenomenon is known as concept drift and leads to a decrease in the predictive model's performance. In this study, we propose a new concept drift detection method based on autoregressive models called ADDM. This method can be integrated into any machine learning algorithm from deep neural networks to simple linear regression model. Our results show that this new concept drift detection method outperforms the state-of-the-art drift detection methods, both on synthetic data sets and real-world data sets. Our approach is theoretically guaranteed as well as empirical and effective for the detection of various concept drifts. In addition to the drift detector, we proposed a new method of concept drift adaptation based on the severity of the drift.