 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Brittle Decisions for Free: Leveraging Margin Consistency in Deep Robust Classifiers
Jun 26, 2024Despite extensive research on adversarial training strategies to improve robustness, the decisions of even the most robust deep learning models can still be quite sensitive to imperceptible perturbations, creating serious risks when deploying them for high-stakes real-world applications. While detecting such cases may be critical, evaluating a model's vulnerability at a per-instance level using adversarial attacks is computationally too intensive and unsuitable for real-time deployment scenarios. The input space margin is the exact score to detect non-robust samples and is intractable for deep neural networks. This paper introduces the concept of margin consistency -- a property that links the input space margins and the logit margins in robust models -- for efficient detection of vulnerable samples. First, we establish that margin consistency is a necessary and sufficient condition to use a model's logit margin as a score for identifying non-robust samples. Next, through comprehensive empirical analysis of various robustly trained models on CIFAR10 and CIFAR100 datasets, we show that they indicate strong margin consistency with a strong correlation between their input space margins and the logit margins. Then, we show that we can effectively use the logit margin to confidently detect brittle decisions with such models and accurately estimate robust accuracy on an arbitrarily large test set by estimating the input margins only on a small subset. Finally, we address cases where the model is not sufficiently margin-consistent by learning a pseudo-margin from the feature representation. Our findings highlight the potential of leveraging deep representations to efficiently assess adversarial vulnerability in deployment scenarios.
Layerwise Early Stopping for Test Time Adaptation
Apr 04, 2024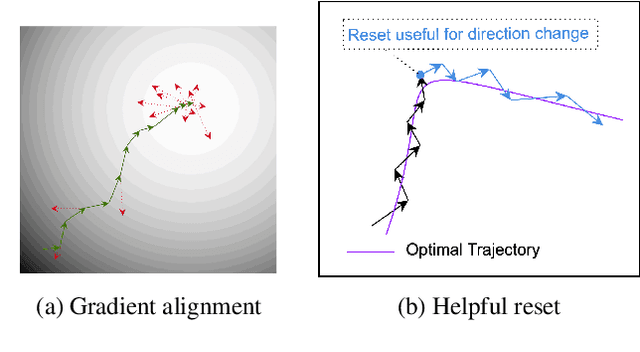



Test Time Adaptation (TTA) addresses the problem of distribution shift by enabling pretrained models to learn new features on an unseen domain at test time. However, it poses a significant challenge to maintain a balance between learning new features and retaining useful pretrained features. In this paper, we propose Layerwise EArly STopping (LEAST) for TTA to address this problem. The key idea is to stop adapting individual layers during TTA if the features being learned do not appear beneficial for the new domain. For that purpose, we propose using a novel gradient-based metric to measure the relevance of the current learnt features to the new domain without the need for supervised labels. More specifically, we propose to use this metric to determine dynamically when to stop updating each layer during TTA. This enables a more balanced adaptation, restricted to layers benefiting from it, and only for a certain number of steps. Such an approach also has the added effect of limiting the forgetting of pretrained features useful for dealing with new domains. Through extensive experiments, we demonstrate that Layerwise Early Stopping improves the performance of existing TTA approaches across multiple datasets, domain shifts, model architectures, and TTA losses.
GROOD: GRadient-aware Out-Of-Distribution detection in interpolated manifolds
Dec 22, 2023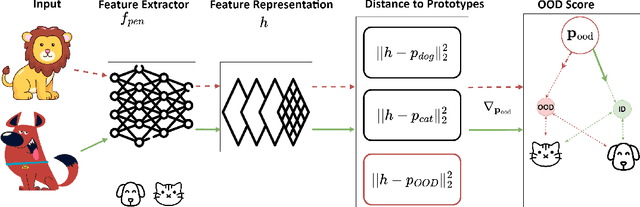
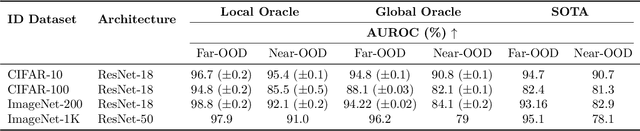
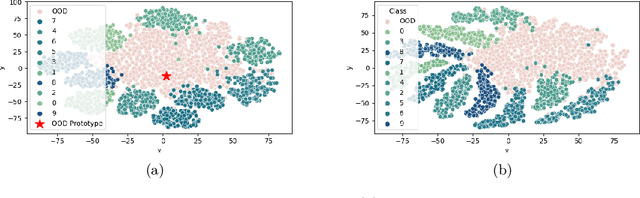
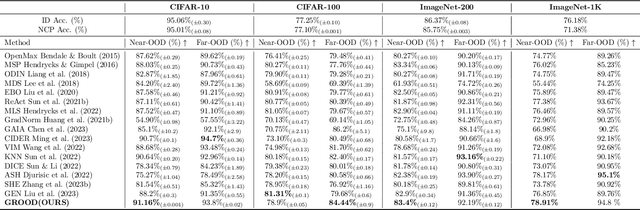
Deep neural networks (DNNs) often fail silently with over-confident predictions on out-of-distribution (OOD) samples, posing risks in real-world deployments. Existing techniques predominantly emphasize either the feature representation space or the gradient norms computed with respect to DNN parameters, yet they overlook the intricate gradient distribution and the topology of classification regions. To address this gap, we introduce GRadient-aware Out-Of-Distribution detection in interpolated manifolds (GROOD), a novel framework that relies on the discriminative power of gradient space to distinguish between in-distribution (ID) and OOD samples. To build this space, GROOD relies on class prototypes together with a prototype that specifically captures OOD characteristics. Uniquely, our approach incorporates a targeted mix-up operation at an early intermediate layer of the DNN to refine the separation of gradient spaces between ID and OOD samples. We quantify OOD detection efficacy using the distance to the nearest neighbor gradients derived from the training set, yielding a robust OOD score. Experimental evaluations substantiate that the introduction of targeted input mix-upamplifies the separation between ID and OOD in the gradient space, yielding impressive results across diverse datasets. Notably, when benchmarked against ImageNet-1k, GROOD surpasses the established robustness of state-of-the-art baselines. Through this work, we establish the utility of leveraging gradient spaces and class prototypes for enhanced OOD detection for DNN in image classification.
Hessian Aware Low-Rank Weight Perturbation for Continual Learning
Nov 26, 2023Continual learning aims to learn a series of tasks sequentially without forgetting the knowledge acquired from the previous ones. In this work, we propose the Hessian Aware Low-Rank Perturbation algorithm for continual learning. By modeling the parameter transitions along the sequential tasks with the weight matrix transformation, we propose to apply the low-rank approximation on the task-adaptive parameters in each layer of the neural networks. Specifically, we theoretically demonstrate the quantitative relationship between the Hessian and the proposed low-rank approximation. The approximation ranks are then globally determined according to the marginal increment of the empirical loss estimated by the layer-specific gradient and low-rank approximation error. Furthermore, we control the model capacity by pruning less important parameters to diminish the parameter growth. We conduct extensive experiments on various benchmarks, including a dataset with large-scale tasks, and compare our method against some recent state-of-the-art methods to demonstrate the effectiveness and scalability of our proposed method. Empirical results show that our method performs better on different benchmarks, especially in achieving task order robustness and handling the forgetting issue. A demo code can be found at https://github.com/lijiaqi/HALRP.
Differentiable SLAM Helps Deep Learning-based LiDAR Perception Tasks
Sep 17, 2023



We investigate a new paradigm that uses differentiable SLAM architectures in a self-supervised manner to train end-to-end deep learning models in various LiDAR based applications. To the best of our knowledge there does not exist any work that leverages SLAM as a training signal for deep learning based models. We explore new ways to improve the efficiency, robustness, and adaptability of LiDAR systems with deep learning techniques. We focus on the potential benefits of differentiable SLAM architectures for improving performance of deep learning tasks such as classification, regression as well as SLAM. Our experimental results demonstrate a non-trivial increase in the performance of two deep learning applications - Ground Level Estimation and Dynamic to Static LiDAR Translation, when used with differentiable SLAM architectures. Overall, our findings provide important insights that enhance the performance of LiDAR based navigation systems. We demonstrate that this new paradigm of using SLAM Loss signal while training LiDAR based models can be easily adopted by the community.
DSLR: Dynamic to Static LiDAR Scan Reconstruction Using Adversarially Trained Autoencoder
May 26, 2021

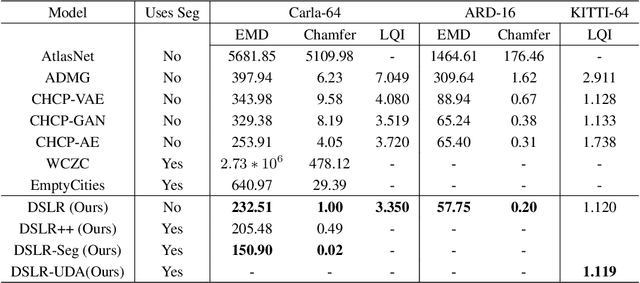
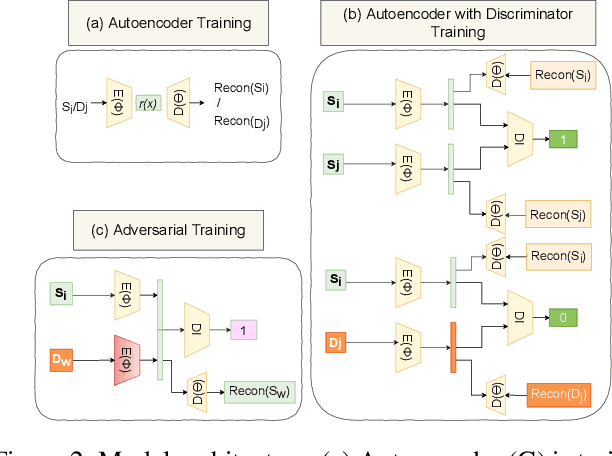
Accurate reconstruction of static environments from LiDAR scans of scenes containing dynamic objects, which we refer to as Dynamic to Static Translation (DST), is an important area of research in Autonomous Navigation. This problem has been recently explored for visual SLAM, but to the best of our knowledge no work has been attempted to address DST for LiDAR scans. The problem is of critical importance due to wide-spread adoption of LiDAR in Autonomous Vehicles. We show that state-of the art methods developed for the visual domain when adapted for LiDAR scans perform poorly. We develop DSLR, a deep generative model which learns a mapping between dynamic scan to its static counterpart through an adversarially trained autoencoder. Our model yields the first solution for DST on LiDAR that generates static scans without using explicit segmentation labels. DSLR cannot always be applied to real world data due to lack of paired dynamic-static scans. Using Unsupervised Domain Adaptation, we propose DSLR-UDA for transfer to real world data and experimentally show that this performs well in real world settings. Additionally, if segmentation information is available, we extend DSLR to DSLR-Seg to further improve the reconstruction quality. DSLR gives the state of the art performance on simulated and real-world datasets and also shows at least 4x improvement. We show that DSLR, unlike the existing baselines, is a practically viable model with its reconstruction quality within the tolerable limits for tasks pertaining to autonomous navigation like SLAM in dynamic environments.