 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Text-to-SQL with Dataset Selection: Leveraging LLMs for Adaptive Query Generation
Aug 08, 2025Text-to-SQL bridges the gap between natural language and structured database language, thus allowing non-technical users to easily query databases. Traditional approaches model text-to-SQL as a direct translation task, where a given Natural Language Query (NLQ) is mapped to an SQL command. Recent advances in large language models (LLMs) have significantly improved translation accuracy, however, these methods all require that the target database is pre-specified. This becomes problematic in scenarios with multiple extensive databases, where identifying the correct database becomes a crucial yet overlooked step. In this paper, we propose a three-stage end-to-end text-to-SQL framework to identify the user's intended database before generating SQL queries. Our approach leverages LLMs and prompt engineering to extract implicit information from natural language queries (NLQs) in the form of a ruleset. We then train a large db\_id prediction model, which includes a RoBERTa-based finetuned encoder, to predict the correct Database identifier (db\_id) based on both the NLQ and the LLM-generated rules. Finally, we refine the generated SQL by using critic agents to correct errors. Experimental results demonstrate that our framework outperforms the current state-of-the-art models in both database intent prediction and SQL generation accuracy.
DOPPLER: Dual-Policy Learning for Device Assignment in Asynchronous Dataflow Graphs
May 29, 2025We study the problem of assigning operations in a dataflow graph to devices to minimize execution time in a work-conserving system, with emphasis on complex machine learning workloads. Prior learning-based methods often struggle due to three key limitations: (1) reliance on bulk-synchronous systems like TensorFlow, which under-utilize devices due to barrier synchronization; (2) lack of awareness of the scheduling mechanism of underlying systems when designing learning-based methods; and (3) exclusive dependence on reinforcement learning, ignoring the structure of effective heuristics designed by experts. In this paper, we propose \textsc{Doppler}, a three-stage framework for training dual-policy networks consisting of 1) a $\mathsf{SEL}$ policy for selecting operations and 2) a $\mathsf{PLC}$ policy for placing chosen operations on devices. Our experiments show that \textsc{Doppler} outperforms all baseline methods across tasks by reducing system execution time and additionally demonstrates sampling efficiency by reducing per-episode training time.
Beyond Speaker Identity: Text Guided Target Speech Extraction
Jan 15, 2025Target Speech Extraction (TSE) traditionally relies on explicit clues about the speaker's identity like enrollment audio, face images, or videos, which may not always be available. In this paper, we propose a text-guided TSE model StyleTSE that uses natural language descriptions of speaking style in addition to the audio clue to extract the desired speech from a given mixture. Our model integrates a speech separation network adapted from SepFormer with a bi-modality clue network that flexibly processes both audio and text clues. To train and evaluate our model, we introduce a new dataset TextrolMix with speech mixtures and natural language descriptions. Experimental results demonstrate that our method effectively separates speech based not only on who is speaking, but also on how they are speaking, enhancing TSE in scenarios where traditional audio clues are absent. Demos are at: https://mingyue66.github.io/TextrolMix/demo/
DiffSign: AI-Assisted Generation of Customizable Sign Language Videos With Enhanced Realism
Dec 05, 2024



The proliferation of several streaming services in recent years has now made it possible for a diverse audience across the world to view the same media content, such as movies or TV shows. While translation and dubbing services are being added to make content accessible to the local audience, the support for making content accessible to people with different abilities, such as the Deaf and Hard of Hearing (DHH) community, is still lagging. Our goal is to make media content more accessible to the DHH community by generating sign language videos with synthetic signers that are realistic and expressive. Using the same signer for a given media content that is viewed globally may have limited appeal. Hence, our approach combines parametric modeling and generative modeling to generate realistic-looking synthetic signers and customize their appearance based on user preferences. We first retarget human sign language poses to 3D sign language avatars by optimizing a parametric model. The high-fidelity poses from the rendered avatars are then used to condition the poses of synthetic signers generated using a diffusion-based generative model. The appearance of the synthetic signer is controlled by an image prompt supplied through a visual adapter. Our results show that the sign language videos generated using our approach have better temporal consistency and realism than signing videos generated by a diffusion model conditioned only on text prompts. We also support multimodal prompts to allow users to further customize the appearance of the signer to accommodate diversity (e.g. skin tone, gender). Our approach is also useful for signer anonymization.
Prompt Tuning Strikes Back: Customizing Foundation Models with Low-Rank Prompt Adaptation
May 24, 2024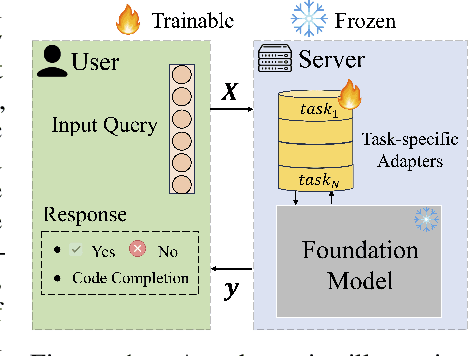
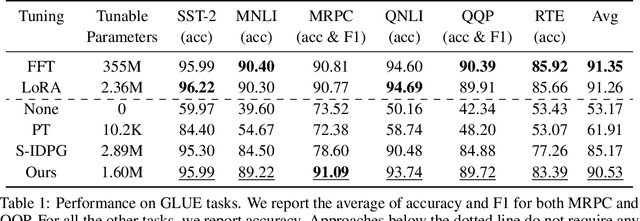
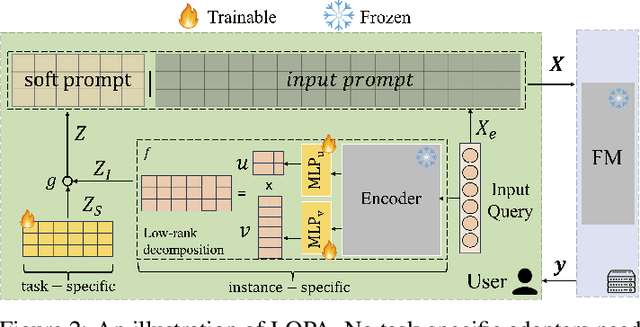
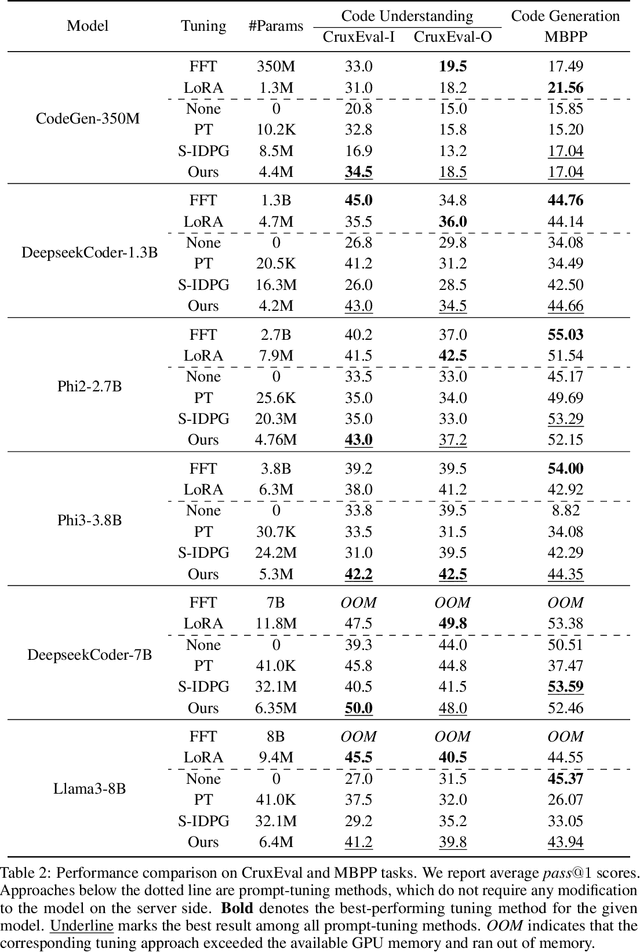
Parameter-Efficient Fine-Tuning (PEFT) has become the standard for customising Foundation Models (FMs) to user-specific downstream tasks. However, typical PEFT methods require storing multiple task-specific adapters, creating scalability issues as these adapters must be housed and run at the FM server. Traditional prompt tuning offers a potential solution by customising them through task-specific input prefixes, but it under-performs compared to other PEFT methods like LoRA. To address this gap, we propose Low-Rank Prompt Adaptation (LOPA), a prompt-tuning-based approach that performs on par with state-of-the-art PEFT methods and full fine-tuning while being more parameter-efficient and not requiring a server-based adapter. LOPA generates soft prompts by balancing between sharing task-specific information across instances and customization for each instance. It uses a low-rank decomposition of the soft-prompt component encoded for each instance to achieve parameter efficiency. We provide a comprehensive evaluation on multiple natural language understanding and code generation and understanding tasks across a wide range of foundation models with varying sizes.
Uncovering implementable dormant pruning decisions from three different stakeholder perspectives
May 07, 2024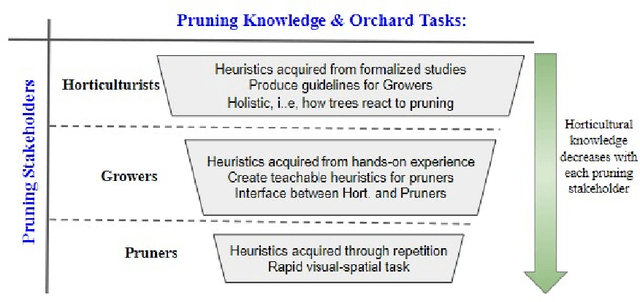

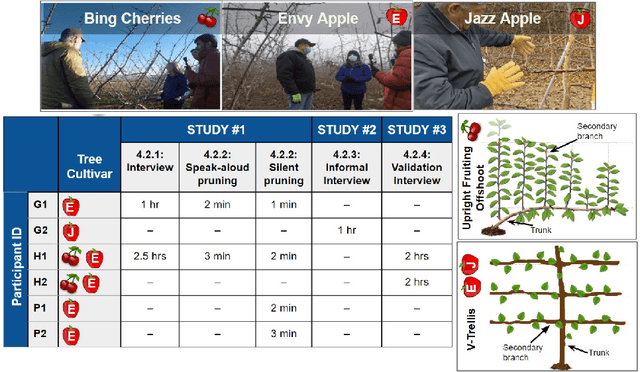

Dormant pruning, or the removal of unproductive portions of a tree while a tree is not actively growing, is an important orchard task to help maintain yield, requiring years to build expertise. Because of long training periods and an increasing labor shortage in agricultural jobs, pruning could benefit from robotic automation. However, to program robots to prune branches, we first need to understand how pruning decisions are made, and what variables in the environment (e.g., branch size and thickness) we need to capture. Working directly with three pruning stakeholders -- horticulturists, growers, and pruners -- we find that each group of human experts approaches pruning decision-making differently. To capture this knowledge, we present three studies and two extracted pruning protocols from field work conducted in Prosser, Washington in January 2022 and 2023. We interviewed six stakeholders (two in each group) and observed pruning across three cultivars -- Bing Cherries, Envy Apples, and Jazz Apples -- and two tree architectures -- Upright Fruiting Offshoot and V-Trellis. Leveraging participant interviews and video data, this analysis uses grounded coding to extract pruning terminology, discover horticultural contexts that influence pruning decisions, and find implementable pruning heuristics for autonomous systems. The results include a validated terminology set, which we offer for use by both pruning stakeholders and roboticists, to communicate general pruning concepts and heuristics. The results also highlight seven pruning heuristics utilizing this terminology set that would be relevant for use by future autonomous robot pruning systems, and characterize three discovered horticultural contexts (i.e., environmental management, crop-load management, and replacement wood) across all three cultivars.
GO-DICE: Goal-Conditioned Option-Aware Offline Imitation Learning via Stationary Distribution Correction Estimation
Dec 17, 2023



Offline imitation learning (IL) refers to learning expert behavior solely from demonstrations, without any additional interaction with the environment. Despite significant advances in offline IL, existing techniques find it challenging to learn policies for long-horizon tasks and require significant re-training when task specifications change. Towards addressing these limitations, we present GO-DICE an offline IL technique for goal-conditioned long-horizon sequential tasks. GO-DICE discerns a hierarchy of sub-tasks from demonstrations and uses these to learn separate policies for sub-task transitions and action execution, respectively; this hierarchical policy learning facilitates long-horizon reasoning. Inspired by the expansive DICE-family of techniques, policy learning at both the levels transpires within the space of stationary distributions. Further, both policies are learnt with goal conditioning to minimize need for retraining when task goals change. Experimental results substantiate that GO-DICE outperforms recent baselines, as evidenced by a marked improvement in the completion rate of increasingly challenging pick-and-place Mujoco robotic tasks. GO-DICE is also capable of leveraging imperfect demonstration and partial task segmentation when available, both of which boost task performance relative to learning from expert demonstrations alone.
Two Timin': Repairing Smart Contracts With A Two-Layered Approach
Sep 14, 2023Due to the modern relevance of blockchain technology, smart contracts present both substantial risks and benefits. Vulnerabilities within them can trigger a cascade of consequences, resulting in significant losses. Many current papers primarily focus on classifying smart contracts for malicious intent, often relying on limited contract characteristics, such as bytecode or opcode. This paper proposes a novel, two-layered framework: 1) classifying and 2) directly repairing malicious contracts. Slither's vulnerability report is combined with source code and passed through a pre-trained RandomForestClassifier (RFC) and Large Language Models (LLMs), classifying and repairing each suggested vulnerability. Experiments demonstrate the effectiveness of fine-tuned and prompt-engineered LLMs. The smart contract repair models, built from pre-trained GPT-3.5-Turbo and fine-tuned Llama-2-7B models, reduced the overall vulnerability count by 97.5% and 96.7% respectively. A manual inspection of repaired contracts shows that all retain functionality, indicating that the proposed method is appropriate for automatic batch classification and repair of vulnerabilities in smart contracts.
Tuning Models of Code with Compiler-Generated Reinforcement Learning Feedback
May 25, 2023Large Language Models (LLMs) pre-trained on code have recently emerged as the dominant approach to program synthesis. However, the code that these models produce can violate basic language-level invariants, leading to lower performance in downstream tasks. We address this issue through an approach, called RLCF, that further trains a pre-trained LLM using feedback from a code compiler. RLCF views the LLM as an RL agent that generates code step by step and receives: (i) compiler-derived feedback on whether the code it generates passes a set of correctness checks; and (ii) feedback from a different LLM on whether the generated code is similar to a set of reference programs in the training corpus. Together, these feedback mechanisms help the generated code remain within the target distribution while passing all static correctness checks. RLCF is model- and language-agnostic. We empirically evaluate it on the MBJP and MathQA tasks for Java. Our experiments show that RLCF significantly raises the odds that an LLM-generated program compiles, is executable, and produces the right output on tests, often allowing LLMs to match the performance of 2x-8x larger LLMs.
SRTGAN: Triplet Loss based Generative Adversarial Network for Real-World Super-Resolution
Nov 22, 2022



Many applications such as forensics, surveillance, satellite imaging, medical imaging, etc., demand High-Resolution (HR) images. However, obtaining an HR image is not always possible due to the limitations of optical sensors and their costs. An alternative solution called Single Image Super-Resolution (SISR) is a software-driven approach that aims to take a Low-Resolution (LR) image and obtain the HR image. Most supervised SISR solutions use ground truth HR image as a target and do not include the information provided in the LR image, which could be valuable. In this work, we introduce Triplet Loss-based Generative Adversarial Network hereafter referred as SRTGAN for Image Super-Resolution problem on real-world degradation. We introduce a new triplet-based adversarial loss function that exploits the information provided in the LR image by using it as a negative sample. Allowing the patch-based discriminator with access to both HR and LR images optimizes to better differentiate between HR and LR images; hence, improving the adversary. Further, we propose to fuse the adversarial loss, content loss, perceptual loss, and quality loss to obtain Super-Resolution (SR) image with high perceptual fidelity. We validate the superior performance of the proposed method over the other existing methods on the RealSR dataset in terms of quantitative and qualitative metrics.