 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Tuning Strikes Back: Customizing Foundation Models with Low-Rank Prompt Adaptation
May 24, 2024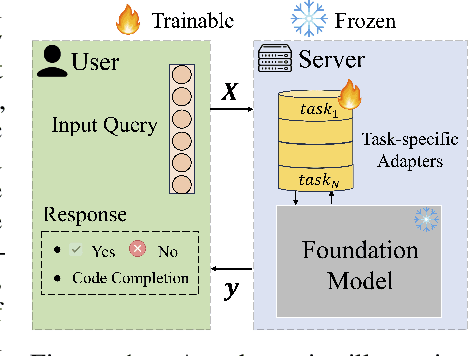
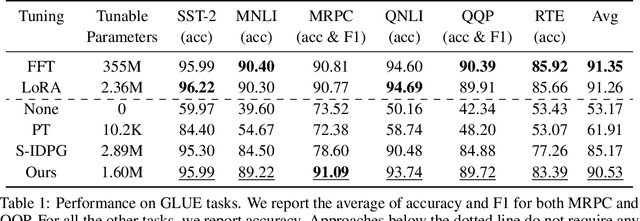
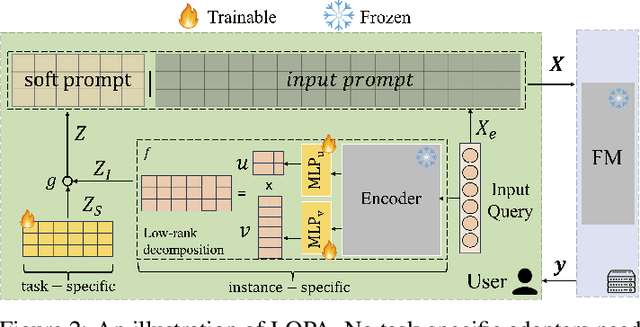
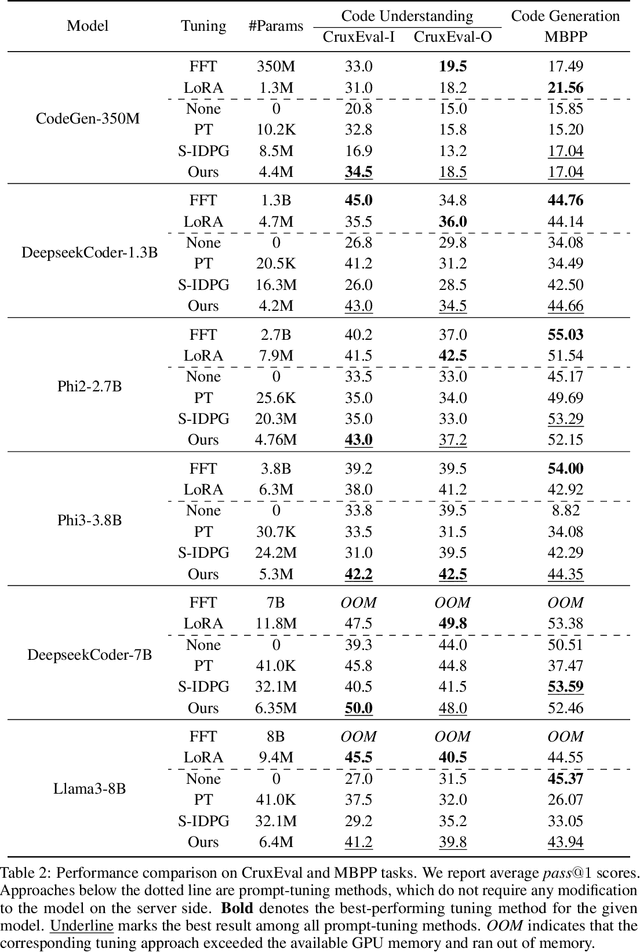
Parameter-Efficient Fine-Tuning (PEFT) has become the standard for customising Foundation Models (FMs) to user-specific downstream tasks. However, typical PEFT methods require storing multiple task-specific adapters, creating scalability issues as these adapters must be housed and run at the FM server. Traditional prompt tuning offers a potential solution by customising them through task-specific input prefixes, but it under-performs compared to other PEFT methods like LoRA. To address this gap, we propose Low-Rank Prompt Adaptation (LOPA), a prompt-tuning-based approach that performs on par with state-of-the-art PEFT methods and full fine-tuning while being more parameter-efficient and not requiring a server-based adapter. LOPA generates soft prompts by balancing between sharing task-specific information across instances and customization for each instance. It uses a low-rank decomposition of the soft-prompt component encoded for each instance to achieve parameter efficiency. We provide a comprehensive evaluation on multiple natural language understanding and code generation and understanding tasks across a wide range of foundation models with varying sizes.
Tuning Models of Code with Compiler-Generated Reinforcement Learning Feedback
May 25, 2023Large Language Models (LLMs) pre-trained on code have recently emerged as the dominant approach to program synthesis. However, the code that these models produce can violate basic language-level invariants, leading to lower performance in downstream tasks. We address this issue through an approach, called RLCF, that further trains a pre-trained LLM using feedback from a code compiler. RLCF views the LLM as an RL agent that generates code step by step and receives: (i) compiler-derived feedback on whether the code it generates passes a set of correctness checks; and (ii) feedback from a different LLM on whether the generated code is similar to a set of reference programs in the training corpus. Together, these feedback mechanisms help the generated code remain within the target distribution while passing all static correctness checks. RLCF is model- and language-agnostic. We empirically evaluate it on the MBJP and MathQA tasks for Java. Our experiments show that RLCF significantly raises the odds that an LLM-generated program compiles, is executable, and produces the right output on tests, often allowing LLMs to match the performance of 2x-8x larger LLMs.
Semantic Robustness of Models of Source Code
Feb 07, 2020
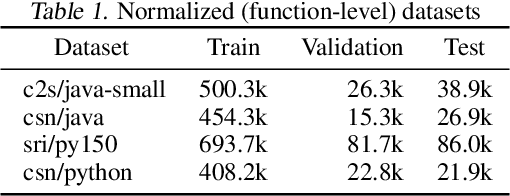


Deep neural networks are vulnerable to adversarial examples - small input perturbations that result in incorrect predictions. We study this problem in the context of models of source code, where we want the network to be robust to source-code modifications that preserve code functionality. We define a natural notion of robustness, $k$-transformation robustness, in which an adversary performs up to $k$ semantics-preserving transformations to an input program. We show how to train robust models using an adversarial training objective inspired by that of Madry et al. (2018) for continuous domains. We implement an extensible framework for adversarial training over source code, and conduct a thorough evaluation on a number of datasets and two different architectures. Our results show (1) the increase in robustness following adversarial training, (2) the ability of training on weak adversaries to provide robustness to attacks by stronger adversaries, and (3) the shift in attribution focus of adversarially trained models towards semantic vs. syntactic features.
Enabling Open-World Specification Mining via Unsupervised Learning
Apr 27, 2019


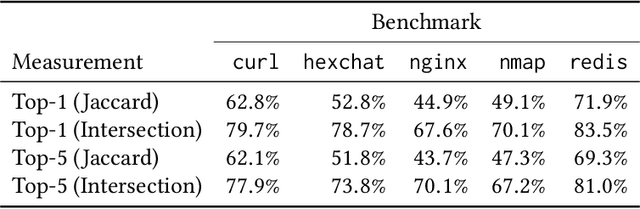
Many programming tasks require using both domain-specific code and well-established patterns (such as routines concerned with file IO). Together, several small patterns combine to create complex interactions. This compounding effect, mixed with domain-specific idiosyncrasies, creates a challenging environment for fully automatic specification inference. Mining specifications in this environment, without the aid of rule templates, user-directed feedback, or predefined API surfaces, is a major challenge. We call this challenge Open-World Specification Mining. In this paper, we present a framework for mining specifications and usage patterns in an Open-World setting. We design this framework to be miner-agnostic and instead focus on disentangling complex and noisy API interactions. To evaluate our framework, we introduce a benchmark of 71 clusters extracted from five open-source projects. Using this dataset, we show that interesting clusters can be recovered, in a fully automatic way, by leveraging unsupervised learning in the form of word embeddings. Once clusters have been recovered, the challenge of Open-World Specification Mining is simplified and any trace-based mining technique can be applied. In addition, we provide a comprehensive evaluation of three word-vector learners to showcase the value of sub-word information for embeddings learned in the software-engineering domain.
Neural Attribute Machines for Program Generation
May 31, 2017
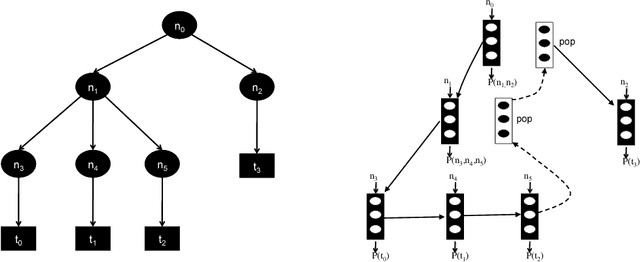
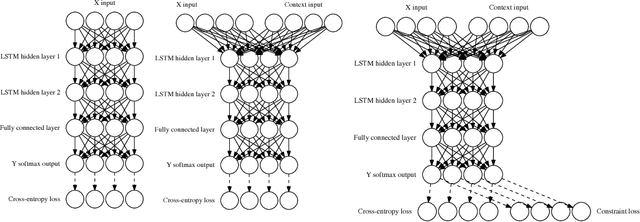
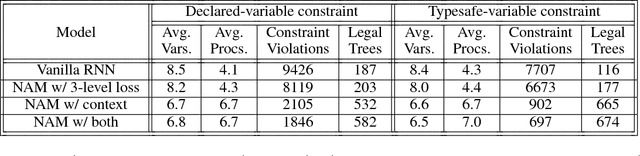
Recurrent neural networks have achieved remarkable success at generating sequences with complex structures, thanks to advances that include richer embeddings of input and cures for vanishing gradients. Trained only on sequences from a known grammar, though, they can still struggle to learn rules and constraints of the grammar. Neural Attribute Machines (NAMs) are equipped with a logical machine that represents the underlying grammar, which is used to teach the constraints to the neural machine by (i) augmenting the input sequence, and (ii) optimizing a custom loss function. Unlike traditional RNNs, NAMs are exposed to the grammar, as well as samples from the language of the grammar. During generation, NAMs make significantly fewer violations of the constraints of the underlying grammar than RNNs trained only on samples from the language of the grammar.