 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Interestingness in Automated Mathematical Theory Formation
Nov 05, 2025We take two key steps in automating the open-ended discovery of new mathematical theories, a grand challenge in artificial intelligence. First, we introduce $\emph{FERMAT}$, a reinforcement learning (RL) environment that models concept discovery and theorem-proving using a set of symbolic actions, opening up a range of RL problems relevant to theory discovery. Second, we explore a specific problem through $\emph{FERMAT}$: automatically scoring the $\emph{interestingness}$ of mathematical objects. We investigate evolutionary algorithms for synthesizing nontrivial interestingness measures. In particular, we introduce an LLM-based evolutionary algorithm that features function abstraction, leading to notable improvements in discovering elementary number theory and finite fields over hard-coded baselines. We open-source the $\emph{FERMAT}$ environment at this URL(https://github.com/trishullab/Fermat).
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Jun 16, 2025In this white paper, we present AlphaEvolve, an evolutionary coding agent that substantially enhances capabilities of state-of-the-art LLMs on highly challenging tasks such as tackling open scientific problems or optimizing critical pieces of computational infrastructure. AlphaEvolve orchestrates an autonomous pipeline of LLMs, whose task is to improve an algorithm by making direct changes to the code. Using an evolutionary approach, continuously receiving feedback from one or more evaluators, AlphaEvolve iteratively improves the algorithm, potentially leading to new scientific and practical discoveries. We demonstrate the broad applicability of this approach by applying it to a number of important computational problems. When applied to optimizing critical components of large-scale computational stacks at Google, AlphaEvolve developed a more efficient scheduling algorithm for data centers, found a functionally equivalent simplification in the circuit design of hardware accelerators, and accelerated the training of the LLM underpinning AlphaEvolve itself. Furthermore, AlphaEvolve discovered novel, provably correct algorithms that surpass state-of-the-art solutions on a spectrum of problems in mathematics and computer science, significantly expanding the scope of prior automated discovery methods (Romera-Paredes et al., 2023). Notably, AlphaEvolve developed a search algorithm that found a procedure to multiply two $4 \times 4$ complex-valued matrices using $48$ scalar multiplications; offering the first improvement, after 56 years, over Strassen's algorithm in this setting. We believe AlphaEvolve and coding agents like it can have a significant impact in improving solutions of problems across many areas of science and computation.
CLEVER: A Curated Benchmark for Formally Verified Code Generation
May 21, 2025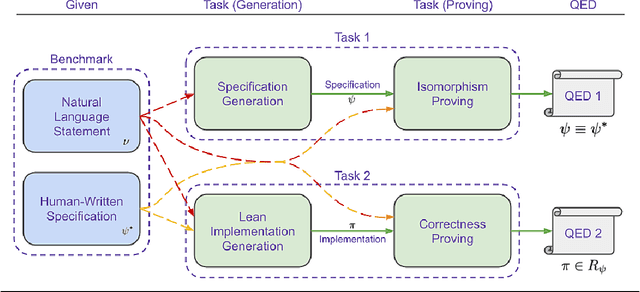
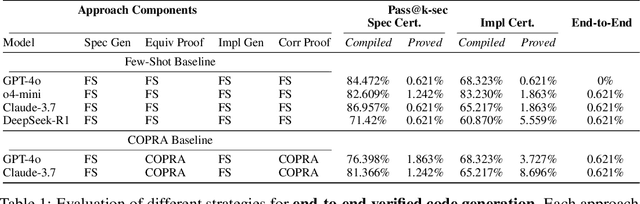

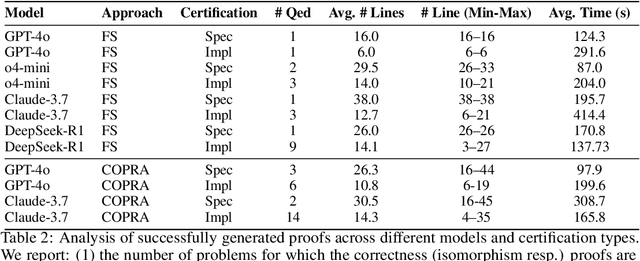
We introduce ${\rm C{\small LEVER}}$, a high-quality, curated benchmark of 161 problems for end-to-end verified code generation in Lean. Each problem consists of (1) the task of generating a specification that matches a held-out ground-truth specification, and (2) the task of generating a Lean implementation that provably satisfies this specification. Unlike prior benchmarks, ${\rm C{\small LEVER}}$ avoids test-case supervision, LLM-generated annotations, and specifications that leak implementation logic or allow vacuous solutions. All outputs are verified post-hoc using Lean's type checker to ensure machine-checkable correctness. We use ${\rm C{\small LEVER}}$ to evaluate several few-shot and agentic approaches based on state-of-the-art language models. These methods all struggle to achieve full verification, establishing it as a challenging frontier benchmark for program synthesis and formal reasoning. Our benchmark can be found on GitHub(https://github.com/trishullab/clever) as well as HuggingFace(https://huggingface.co/datasets/amitayusht/clever). All our evaluation code is also available online(https://github.com/trishullab/clever-prover).
Resource-efficient Inference with Foundation Model Programs
Apr 09, 2025
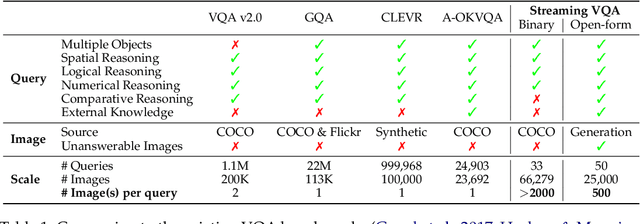
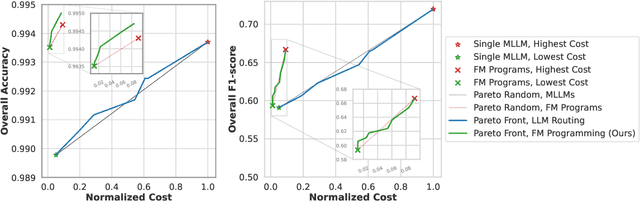
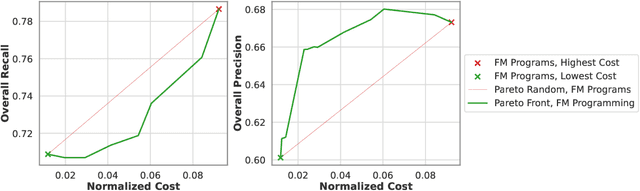
The inference-time resource costs of large language and vision models present a growing challenge in production deployments. We propose the use of foundation model programs, i.e., programs that can invoke foundation models with varying resource costs and performance, as an approach to this problem. Specifically, we present a method that translates a task into a program, then learns a policy for resource allocation that, on each input, selects foundation model "backends" for each program module. The policy uses smaller, cheaper backends to handle simpler subtasks, while allowing more complex subtasks to leverage larger, more capable models. We evaluate the method on two new "streaming" visual question-answering tasks in which a system answers a question on a sequence of inputs, receiving ground-truth feedback after each answer. Compared to monolithic multi-modal models, our implementation achieves up to 98% resource savings with minimal accuracy loss, demonstrating its potential for scalable and resource-efficient multi-modal inference.
Self-Evolving Visual Concept Library using Vision-Language Critics
Mar 31, 2025We study the problem of building a visual concept library for visual recognition. Building effective visual concept libraries is challenging, as manual definition is labor-intensive, while relying solely on LLMs for concept generation can result in concepts that lack discriminative power or fail to account for the complex interactions between them. Our approach, ESCHER, takes a library learning perspective to iteratively discover and improve visual concepts. ESCHER uses a vision-language model (VLM) as a critic to iteratively refine the concept library, including accounting for interactions between concepts and how they affect downstream classifiers. By leveraging the in-context learning abilities of LLMs and the history of performance using various concepts, ESCHER dynamically improves its concept generation strategy based on the VLM critic's feedback. Finally, ESCHER does not require any human annotations, and is thus an automated plug-and-play framework. We empirically demonstrate the ability of ESCHER to learn a concept library for zero-shot, few-shot, and fine-tuning visual classification tasks. This work represents, to our knowledge, the first application of concept library learning to real-world visual tasks.
${\rm P{\small ROOF}W{\small ALA}}$: Multilingual Proof Data Synthesis and Theorem-Proving
Feb 07, 2025
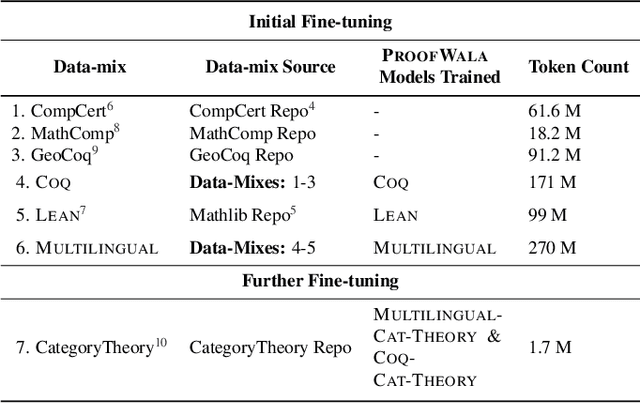
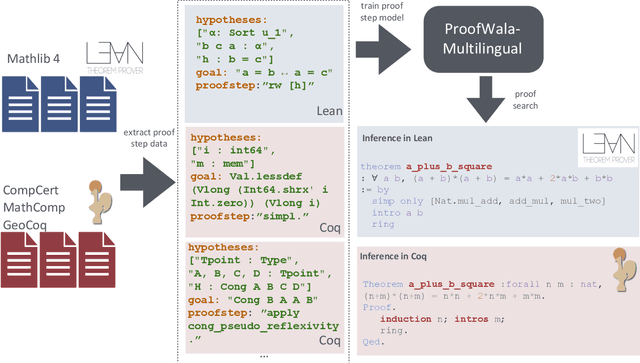
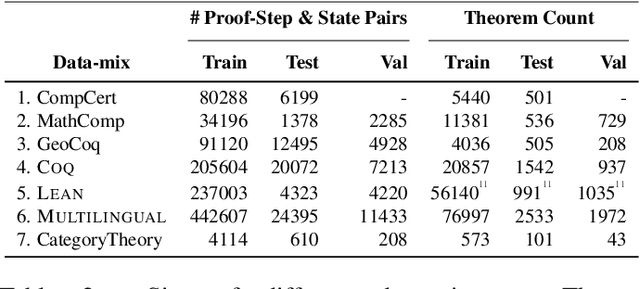
Neural networks have shown substantial promise at automatic theorem-proving in interactive proof assistants (ITPs) like Lean and Coq. However, most neural theorem-proving models are restricted to specific ITPs, leaving out opportunities for cross-lingual $\textit{transfer}$ between ITPs. We address this weakness with a multilingual proof framework, ${\rm P{\small ROOF}W{\small ALA}}$, that allows a standardized form of interaction between neural theorem-provers and two established ITPs (Coq and Lean). It enables the collection of multilingual proof step data -- data recording the result of proof actions on ITP states -- for training neural provers. ${\rm P{\small ROOF}W{\small ALA}}$ allows the systematic evaluation of a model's performance across different ITPs and problem domains via efficient parallel proof search algorithms. We show that multilingual training enabled by ${\rm P{\small ROOF}W{\small ALA}}$ can lead to successful transfer across ITPs. Specifically, a model trained on a mix of ${\rm P{\small ROOF}W{\small ALA}}$-generated Coq and Lean data outperforms Lean-only and Coq-only models on the standard prove-at-$k$ metric. We open source all code including code for the $\href{https://github.com/trishullab/proof-wala}{ProofWala\; Framework}$, and the $\href{https://github.com/trishullab/itp-interface}{Multilingual\; ITP\; interaction\; framework}$.
Formal Mathematical Reasoning: A New Frontier in AI
Dec 20, 2024

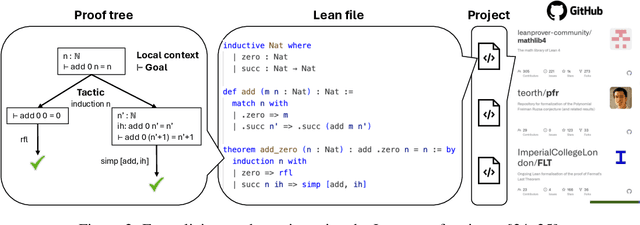

AI for Mathematics (AI4Math) is not only intriguing intellectually but also crucial for AI-driven discovery in science, engineering, and beyond. Extensive efforts on AI4Math have mirrored techniques in NLP, in particular, training large language models on carefully curated math datasets in text form. As a complementary yet less explored avenue, formal mathematical reasoning is grounded in formal systems such as proof assistants, which can verify the correctness of reasoning and provide automatic feedback. In this position paper, we advocate for formal mathematical reasoning and argue that it is indispensable for advancing AI4Math to the next level. In recent years, we have seen steady progress in using AI to perform formal reasoning, including core tasks such as theorem proving and autoformalization, as well as emerging applications such as verifiable generation of code and hardware designs. However, significant challenges remain to be solved for AI to truly master mathematics and achieve broader impact. We summarize existing progress, discuss open challenges, and envision critical milestones to measure future success. At this inflection point for formal mathematical reasoning, we call on the research community to come together to drive transformative advancements in this field.
C3: Learning Congestion Controllers with Formal Certificates
Dec 14, 2024



Learning-based congestion controllers offer better adaptability compared to traditional heuristic algorithms. However, the inherent unreliability of learning techniques can cause learning-based controllers to behave poorly, creating a need for formal guarantees. While methods for formally verifying learned congestion controllers exist, these methods offer binary feedback that cannot optimize the controller toward better behavior. We improve this state-of-the-art via C3, a new learning framework for congestion control that integrates the concept of formal certification in the learning loop. C3 uses an abstract interpreter that can produce robustness and performance certificates to guide the training process, rewarding models that are robust and performant even on worst-case inputs. Our evaluation demonstrates that unlike state-of-the-art learned controllers, C3-trained controllers provide both adaptability and worst-case reliability across a range of network conditions.
Learning Quantitative Automata Modulo Theories
Nov 15, 2024



Quantitative automata are useful representations for numerous applications, including modeling probability distributions over sequences to Markov chains and reward machines. Actively learning such automata typically occurs using explicitly gathered input-output examples under adaptations of the L-star algorithm. However, obtaining explicit input-output pairs can be expensive, and there exist scenarios, including preference-based learning or learning from rankings, where providing constraints is a less exerting and a more natural way to concisely describe desired properties. Consequently, we propose the problem of learning deterministic quantitative automata from sets of constraints over the valuations of input sequences. We present QUINTIC, an active learning algorithm, wherein the learner infers a valid automaton through deductive reasoning, by applying a theory to a set of currently available constraints and an assumed preference model and quantitative automaton class. QUINTIC performs a complete search over the space of automata, and is guaranteed to be minimal and correctly terminate. Our evaluations utilize theory of rationals in order to learn summation, discounted summation, product, and classification quantitative automata, and indicate QUINTIC is effective at learning these types of automata.
Synthesize, Partition, then Adapt: Eliciting Diverse Samples from Foundation Models
Nov 11, 2024Presenting users with diverse responses from foundation models is crucial for enhancing user experience and accommodating varying preferences. However, generating multiple high-quality and diverse responses without sacrificing accuracy remains a challenge, especially when using greedy sampling. In this work, we propose a novel framework, Synthesize-Partition-Adapt (SPA), that leverages the abundant synthetic data available in many domains to elicit diverse responses from foundation models. By leveraging signal provided by data attribution methods such as influence functions, SPA partitions data into subsets, each targeting unique aspects of the data, and trains multiple model adaptations optimized for these subsets. Experimental results demonstrate the effectiveness of our approach in diversifying foundation model responses while maintaining high quality, showcased through the HumanEval and MBPP tasks in the code generation domain and several tasks in the natural language understanding domain, highlighting its potential to enrich user experience across various applications.