 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Quantitative Automata Modulo Theories
Nov 15, 2024



Quantitative automata are useful representations for numerous applications, including modeling probability distributions over sequences to Markov chains and reward machines. Actively learning such automata typically occurs using explicitly gathered input-output examples under adaptations of the L-star algorithm. However, obtaining explicit input-output pairs can be expensive, and there exist scenarios, including preference-based learning or learning from rankings, where providing constraints is a less exerting and a more natural way to concisely describe desired properties. Consequently, we propose the problem of learning deterministic quantitative automata from sets of constraints over the valuations of input sequences. We present QUINTIC, an active learning algorithm, wherein the learner infers a valid automaton through deductive reasoning, by applying a theory to a set of currently available constraints and an assumed preference model and quantitative automaton class. QUINTIC performs a complete search over the space of automata, and is guaranteed to be minimal and correctly terminate. Our evaluations utilize theory of rationals in order to learn summation, discounted summation, product, and classification quantitative automata, and indicate QUINTIC is effective at learning these types of automata.
Learning Reward Machines through Preference Queries over Sequences
Aug 18, 2023Reward machines have shown great promise at capturing non-Markovian reward functions for learning tasks that involve complex action sequencing. However, no algorithm currently exists for learning reward machines with realistic weak feedback in the form of preferences. We contribute REMAP, a novel algorithm for learning reward machines from preferences, with correctness and termination guarantees. REMAP introduces preference queries in place of membership queries in the L* algorithm, and leverages a symbolic observation table along with unification and constraint solving to narrow the hypothesis reward machine search space. In addition to the proofs of correctness and termination for REMAP, we present empirical evidence measuring correctness: how frequently the resulting reward machine is isomorphic under a consistent yet inexact teacher, and the regret between the ground truth and learned reward machines.
Generalizing to New Domains by Mapping Natural Language to Lifted LTL
Oct 11, 2021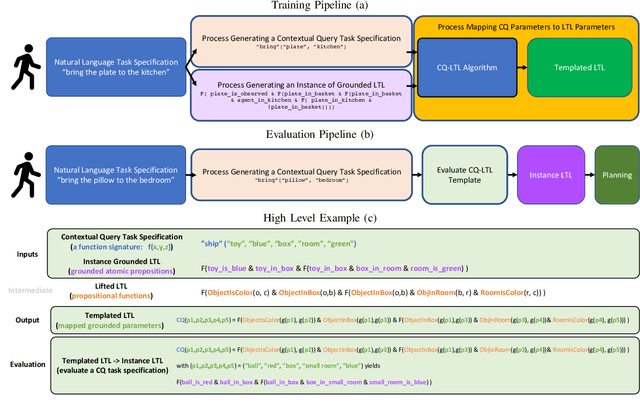

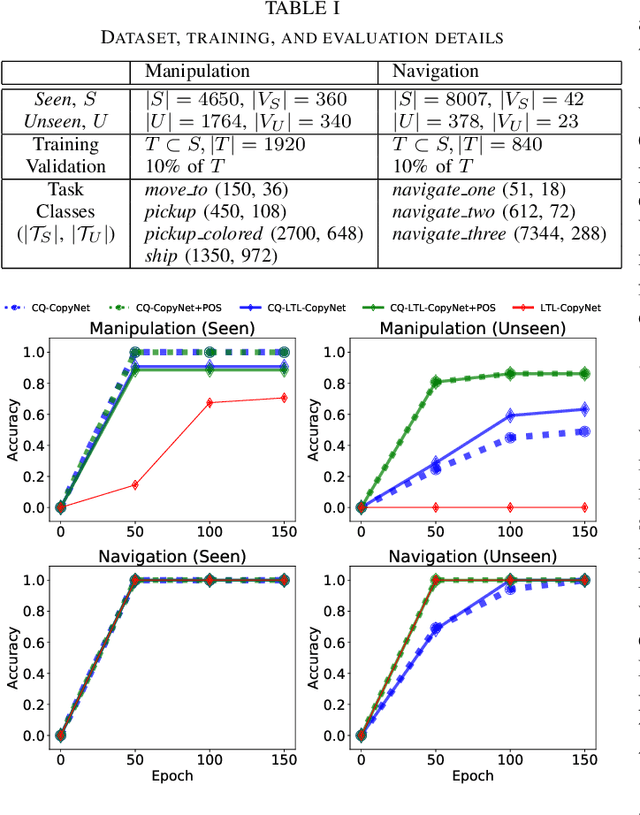
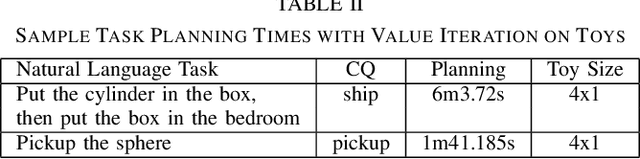
Recent work on using natural language to specify commands to robots has grounded that language to LTL. However, mapping natural language task specifications to LTL task specifications using language models require probability distributions over finite vocabulary. Existing state-of-the-art methods have extended this finite vocabulary to include unseen terms from the input sequence to improve output generalization. However, novel out-of-vocabulary atomic propositions cannot be generated using these methods. To overcome this, we introduce an intermediate contextual query representation which can be learned from single positive task specification examples, associating a contextual query with an LTL template. We demonstrate that this intermediate representation allows for generalization over unseen object references, assuming accurate groundings are available. We compare our method of mapping natural language task specifications to intermediate contextual queries against state-of-the-art CopyNet models capable of translating natural language to LTL, by evaluating whether correct LTL for manipulation and navigation task specifications can be output, and show that our method outperforms the CopyNet model on unseen object references. We demonstrate that the grounded LTL our method outputs can be used for planning in a simulated OO-MDP environment. Finally, we discuss some common failure modes encountered when translating natural language task specifications to grounded LTL.
Value-Based Reinforcement Learning for Continuous Control Robotic Manipulation in Multi-Task Sparse Reward Settings
Jul 28, 2021
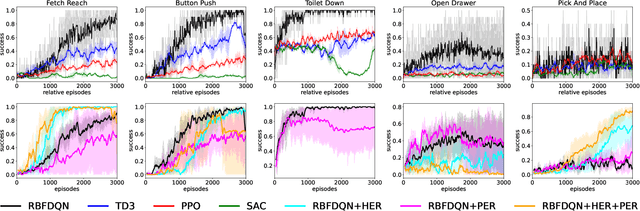
Learning continuous control in high-dimensional sparse reward settings, such as robotic manipulation, is a challenging problem due to the number of samples often required to obtain accurate optimal value and policy estimates. While many deep reinforcement learning methods have aimed at improving sample efficiency through replay or improved exploration techniques, state of the art actor-critic and policy gradient methods still suffer from the hard exploration problem in sparse reward settings. Motivated by recent successes of value-based methods for approximating state-action values, like RBF-DQN, we explore the potential of value-based reinforcement learning for learning continuous robotic manipulation tasks in multi-task sparse reward settings. On robotic manipulation tasks, we empirically show RBF-DQN converges faster than current state of the art algorithms such as TD3, SAC, and PPO. We also perform ablation studies with RBF-DQN and have shown that some enhancement techniques for vanilla Deep Q learning such as Hindsight Experience Replay (HER) and Prioritized Experience Replay (PER) can also be applied to RBF-DQN. Our experimental analysis suggests that value-based approaches may be more sensitive to data augmentation and replay buffer sample techniques than policy-gradient methods, and that the benefits of these methods for robot manipulation are heavily dependent on the transition dynamics of generated subgoal states.