 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDancing with a Robot: An Experimental Study of Child-Robot Interaction in a Performative Art Setting
Aug 07, 2025This paper presents an evaluation of 18 children's in-the-wild experiences with the autonomous robot arm performer NED (Never-Ending Dancer) within the Thingamabobas installation, showcased across the UK. We detail NED's design, including costume, behaviour, and human interactions, all integral to the installation. Our observational analysis revealed three key challenges in child-robot interactions: 1) Initiating and maintaining engagement, 2) Lack of robot expressivity and reciprocity, and 3) Unmet expectations. Our findings show that children are naturally curious, and adept at interacting with a robotic art performer. However, our observations emphasise the critical need to optimise human-robot interaction (HRI) systems through careful consideration of audience's capabilities, perceptions, and expectations, within the performative arts context, to enable engaging and meaningful experiences, especially for young audiences.
* published by Springer
Value Profiles for Encoding Human Variation
Mar 19, 2025Modelling human variation in rating tasks is crucial for enabling AI systems for personalization, pluralistic model alignment, and computational social science. We propose representing individuals using value profiles -- natural language descriptions of underlying values compressed from in-context demonstrations -- along with a steerable decoder model to estimate ratings conditioned on a value profile or other rater information. To measure the predictive information in rater representations, we introduce an information-theoretic methodology. We find that demonstrations contain the most information, followed by value profiles and then demographics. However, value profiles offer advantages in terms of scrutability, interpretability, and steerability due to their compressed natural language format. Value profiles effectively compress the useful information from demonstrations (>70% information preservation). Furthermore, clustering value profiles to identify similarly behaving individuals better explains rater variation than the most predictive demographic groupings. Going beyond test set performance, we show that the decoder models interpretably change ratings according to semantic profile differences, are well-calibrated, and can help explain instance-level disagreement by simulating an annotator population. These results demonstrate that value profiles offer novel, predictive ways to describe individual variation beyond demographics or group information.
Utility-inspired Reward Transformations Improve Reinforcement Learning Training of Language Models
Jan 08, 2025Current methods that train large language models (LLMs) with reinforcement learning feedback, often resort to averaging outputs of multiple rewards functions during training. This overlooks crucial aspects of individual reward dimensions and inter-reward dependencies that can lead to sub-optimal outcomes in generations. In this work, we show how linear aggregation of rewards exhibits some vulnerabilities that can lead to undesired properties of generated text. We then propose a transformation of reward functions inspired by economic theory of utility functions (specifically Inada conditions), that enhances sensitivity to low reward values while diminishing sensitivity to already high values. We compare our approach to the existing baseline methods that linearly aggregate rewards and show how the Inada-inspired reward feedback is superior to traditional weighted averaging. We quantitatively and qualitatively analyse the difference in the methods, and see that models trained with Inada-transformations score as more helpful while being less harmful.
Insights on Disagreement Patterns in Multimodal Safety Perception across Diverse Rater Groups
Oct 22, 2024



AI systems crucially rely on human ratings, but these ratings are often aggregated, obscuring the inherent diversity of perspectives in real-world phenomenon. This is particularly concerning when evaluating the safety of generative AI, where perceptions and associated harms can vary significantly across socio-cultural contexts. While recent research has studied the impact of demographic differences on annotating text, there is limited understanding of how these subjective variations affect multimodal safety in generative AI. To address this, we conduct a large-scale study employing highly-parallel safety ratings of about 1000 text-to-image (T2I) generations from a demographically diverse rater pool of 630 raters balanced across 30 intersectional groups across age, gender, and ethnicity. Our study shows that (1) there are significant differences across demographic groups (including intersectional groups) on how severe they assess the harm to be, and that these differences vary across different types of safety violations, (2) the diverse rater pool captures annotation patterns that are substantially different from expert raters trained on specific set of safety policies, and (3) the differences we observe in T2I safety are distinct from previously documented group level differences in text-based safety tasks. To further understand these varying perspectives, we conduct a qualitative analysis of the open-ended explanations provided by raters. This analysis reveals core differences into the reasons why different groups perceive harms in T2I generations. Our findings underscore the critical need for incorporating diverse perspectives into safety evaluation of generative AI ensuring these systems are truly inclusive and reflect the values of all users.
Skill Generalization with Verbs
Oct 18, 2024



It is imperative that robots can understand natural language commands issued by humans. Such commands typically contain verbs that signify what action should be performed on a given object and that are applicable to many objects. We propose a method for generalizing manipulation skills to novel objects using verbs. Our method learns a probabilistic classifier that determines whether a given object trajectory can be described by a specific verb. We show that this classifier accurately generalizes to novel object categories with an average accuracy of 76.69% across 13 object categories and 14 verbs. We then perform policy search over the object kinematics to find an object trajectory that maximizes classifier prediction for a given verb. Our method allows a robot to generate a trajectory for a novel object based on a verb, which can then be used as input to a motion planner. We show that our model can generate trajectories that are usable for executing five verb commands applied to novel instances of two different object categories on a real robot.
States as Strings as Strategies: Steering Language Models with Game-Theoretic Solvers
Feb 06, 2024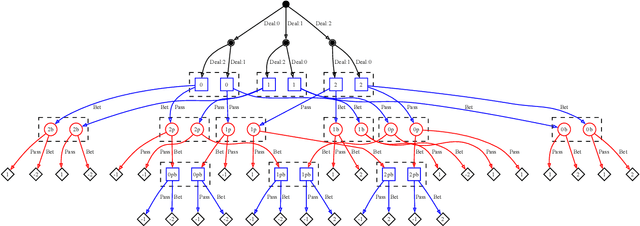

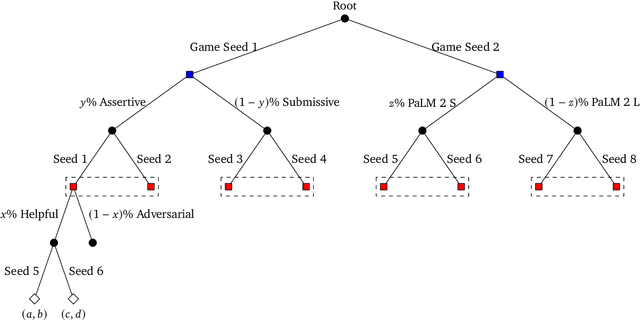
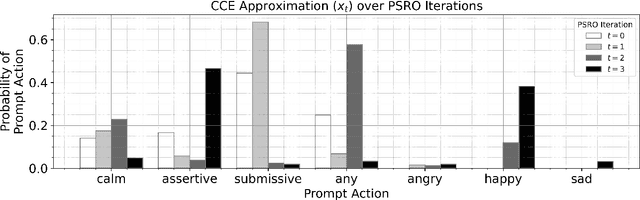
Game theory is the study of mathematical models of strategic interactions among rational agents. Language is a key medium of interaction for humans, though it has historically proven difficult to model dialogue and its strategic motivations mathematically. A suitable model of the players, strategies, and payoffs associated with linguistic interactions (i.e., a binding to the conventional symbolic logic of game theory) would enable existing game-theoretic algorithms to provide strategic solutions in the space of language. In other words, a binding could provide a route to computing stable, rational conversational strategies in dialogue. Large language models (LLMs) have arguably reached a point where their generative capabilities can enable realistic, human-like simulations of natural dialogue. By prompting them in various ways, we can steer their responses towards different output utterances. Leveraging the expressivity of natural language, LLMs can also help us quickly generate new dialogue scenarios, which are grounded in real world applications. In this work, we present one possible binding from dialogue to game theory as well as generalizations of existing equilibrium finding algorithms to this setting. In addition, by exploiting LLMs generation capabilities along with our proposed binding, we can synthesize a large repository of formally-defined games in which one can study and test game-theoretic solution concepts. We also demonstrate how one can combine LLM-driven game generation, game-theoretic solvers, and imitation learning to construct a process for improving the strategic capabilities of LLMs.
Pragmatics in Grounded Language Learning: Phenomena, Tasks, and Modeling Approaches
Nov 15, 2022People rely heavily on context to enrich meaning beyond what is literally said, enabling concise but effective communication. To interact successfully and naturally with people, user-facing artificial intelligence systems will require similar skills in pragmatics: relying on various types of context -- from shared linguistic goals and conventions, to the visual and embodied world -- to use language effectively. We survey existing grounded settings and pragmatic modeling approaches and analyze how the task goals, environmental contexts, and communicative affordances in each work enrich linguistic meaning. We present recommendations for future grounded task design to naturally elicit pragmatic phenomena, and suggest directions that focus on a broader range of communicative contexts and affordances.
RLang: A Declarative Language for Expression Prior Knowledge for Reinforcement Learning
Aug 16, 2022

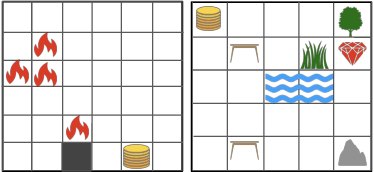
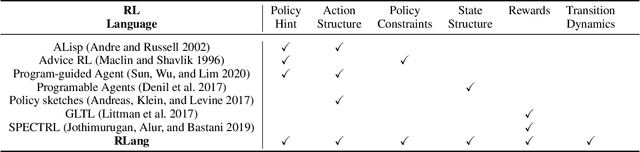
Communicating useful background knowledge to reinforcement learning (RL) agents is an important and effective method for accelerating learning. We introduce RLang, a domain-specific language (DSL) for communicating domain knowledge to an RL agent. Unlike other existing DSLs proposed by the RL community that ground to single elements of a decision-making formalism (e.g., the reward function or policy function), RLang can specify information about every element of a Markov decision process. We define precise syntax and grounding semantics for RLang, and provide a parser implementation that grounds RLang programs to an algorithm-agnostic partial world model and policy that can be exploited by an RL agent. We provide a series of example RLang programs, and demonstrate how different RL methods can exploit the resulting knowledge, including model-free and model-based tabular algorithms, hierarchical approaches, and deep RL algorithms (including both policy gradient and value-based methods).
Generalizing to New Domains by Mapping Natural Language to Lifted LTL
Oct 11, 2021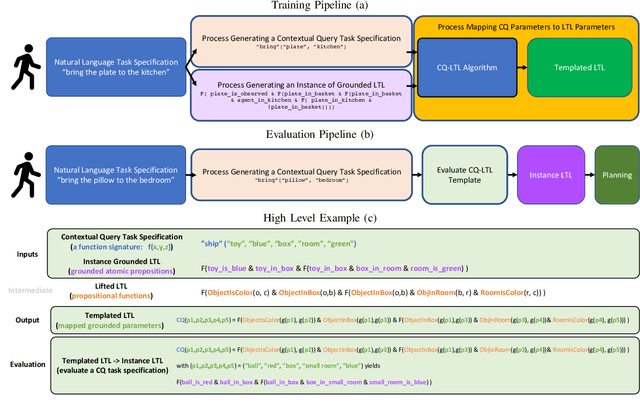

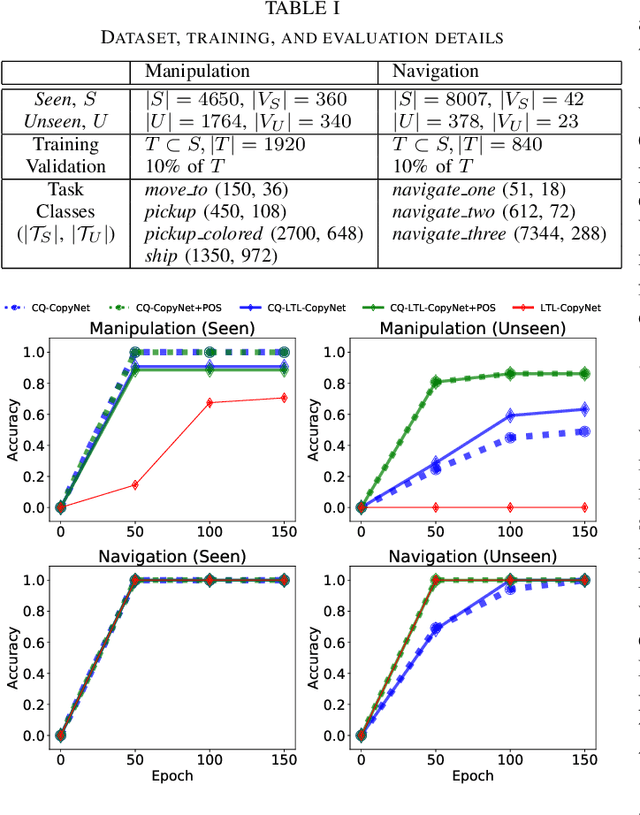
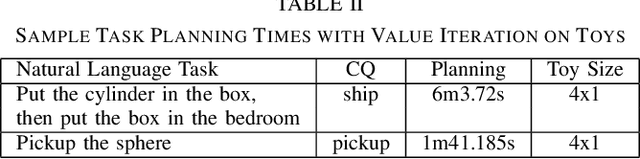
Recent work on using natural language to specify commands to robots has grounded that language to LTL. However, mapping natural language task specifications to LTL task specifications using language models require probability distributions over finite vocabulary. Existing state-of-the-art methods have extended this finite vocabulary to include unseen terms from the input sequence to improve output generalization. However, novel out-of-vocabulary atomic propositions cannot be generated using these methods. To overcome this, we introduce an intermediate contextual query representation which can be learned from single positive task specification examples, associating a contextual query with an LTL template. We demonstrate that this intermediate representation allows for generalization over unseen object references, assuming accurate groundings are available. We compare our method of mapping natural language task specifications to intermediate contextual queries against state-of-the-art CopyNet models capable of translating natural language to LTL, by evaluating whether correct LTL for manipulation and navigation task specifications can be output, and show that our method outperforms the CopyNet model on unseen object references. We demonstrate that the grounded LTL our method outputs can be used for planning in a simulated OO-MDP environment. Finally, we discuss some common failure modes encountered when translating natural language task specifications to grounded LTL.
Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding
Oct 15, 2020
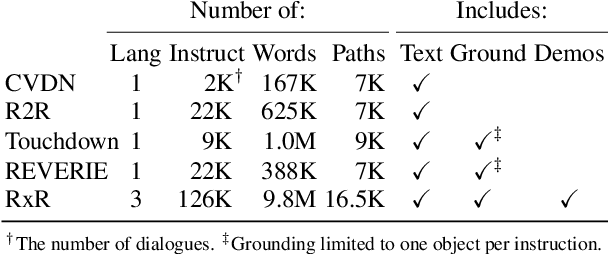
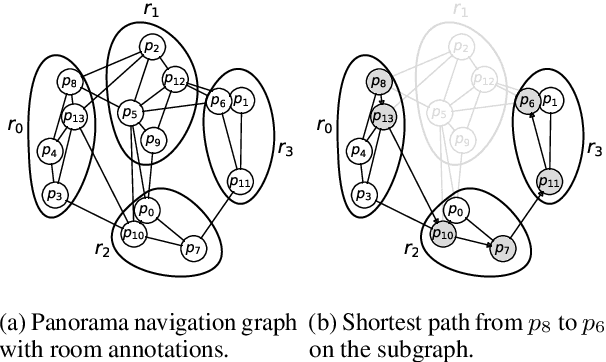
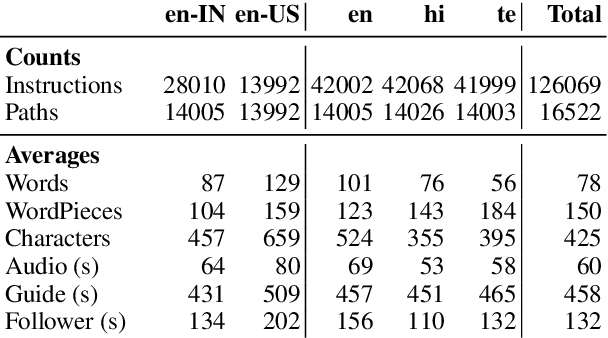
We introduce Room-Across-Room (RxR), a new Vision-and-Language Navigation (VLN) dataset. RxR is multilingual (English, Hindi, and Telugu) and larger (more paths and instructions) than other VLN datasets. It emphasizes the role of language in VLN by addressing known biases in paths and eliciting more references to visible entities. Furthermore, each word in an instruction is time-aligned to the virtual poses of instruction creators and validators. We establish baseline scores for monolingual and multilingual settings and multitask learning when including Room-to-Room annotations. We also provide results for a model that learns from synchronized pose traces by focusing only on portions of the panorama attended to in human demonstrations. The size, scope and detail of RxR dramatically expands the frontier for research on embodied language agents in simulated, photo-realistic environments.