 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Primitive Fitting of 3D Shapes with SuperFrusta
Dec 09, 2025We introduce a framework for converting 3D shapes into compact and editable assemblies of analytic primitives, directly addressing the persistent trade-off between reconstruction fidelity and parsimony. Our approach combines two key contributions: a novel primitive, termed SuperFrustum, and an iterative fiting algorithm, Residual Primitive Fitting (ResFit). SuperFrustum is an analytical primitive that is simultaneously (1) expressive, being able to model various common solids such as cylinders, spheres, cones & their tapered and bent forms, (2) editable, being compactly parameterized with 8 parameters, and (3) optimizable, with a sign distance field differentiable w.r.t. its parameters almost everywhere. ResFit is an unsupervised procedure that interleaves global shape analysis with local optimization, iteratively fitting primitives to the unexplained residual of a shape to discover a parsimonious yet accurate decompositions for each input shape. On diverse 3D benchmarks, our method achieves state-of-the-art results, improving IoU by over 9 points while using nearly half as many primitives as prior work. The resulting assemblies bridge the gap between dense 3D data and human-controllable design, producing high-fidelity and editable shape programs.
Pattern Analogies: Learning to Perform Programmatic Image Edits by Analogy
Dec 17, 2024Pattern images are everywhere in the digital and physical worlds, and tools to edit them are valuable. But editing pattern images is tricky: desired edits are often programmatic: structure-aware edits that alter the underlying program which generates the pattern. One could attempt to infer this underlying program, but current methods for doing so struggle with complex images and produce unorganized programs that make editing tedious. In this work, we introduce a novel approach to perform programmatic edits on pattern images. By using a pattern analogy -- a pair of simple patterns to demonstrate the intended edit -- and a learning-based generative model to execute these edits, our method allows users to intuitively edit patterns. To enable this paradigm, we introduce SplitWeave, a domain-specific language that, combined with a framework for sampling synthetic pattern analogies, enables the creation of a large, high-quality synthetic training dataset. We also present TriFuser, a Latent Diffusion Model (LDM) designed to overcome critical issues that arise when naively deploying LDMs to this task. Extensive experiments on real-world, artist-sourced patterns reveals that our method faithfully performs the demonstrated edit while also generalizing to related pattern styles beyond its training distribution.
Skill Generalization with Verbs
Oct 18, 2024



It is imperative that robots can understand natural language commands issued by humans. Such commands typically contain verbs that signify what action should be performed on a given object and that are applicable to many objects. We propose a method for generalizing manipulation skills to novel objects using verbs. Our method learns a probabilistic classifier that determines whether a given object trajectory can be described by a specific verb. We show that this classifier accurately generalizes to novel object categories with an average accuracy of 76.69% across 13 object categories and 14 verbs. We then perform policy search over the object kinematics to find an object trajectory that maximizes classifier prediction for a given verb. Our method allows a robot to generate a trajectory for a novel object based on a verb, which can then be used as input to a motion planner. We show that our model can generate trajectories that are usable for executing five verb commands applied to novel instances of two different object categories on a real robot.
Learning to Edit Visual Programs with Self-Supervision
Jun 04, 2024We design a system that learns how to edit visual programs. Our edit network consumes a complete input program and a visual target. From this input, we task our network with predicting a local edit operation that could be applied to the input program to improve its similarity to the target. In order to apply this scheme for domains that lack program annotations, we develop a self-supervised learning approach that integrates this edit network into a bootstrapped finetuning loop along with a network that predicts entire programs in one-shot. Our joint finetuning scheme, when coupled with an inference procedure that initializes a population from the one-shot model and evolves members of this population with the edit network, helps to infer more accurate visual programs. Over multiple domains, we experimentally compare our method against the alternative of using only the one-shot model, and find that even under equal search-time budgets, our editing-based paradigm provides significant advantages.
ParSEL: Parameterized Shape Editing with Language
May 31, 2024The ability to edit 3D assets from natural language presents a compelling paradigm to aid in the democratization of 3D content creation. However, while natural language is often effective at communicating general intent, it is poorly suited for specifying precise manipulation. To address this gap, we introduce ParSEL, a system that enables controllable editing of high-quality 3D assets from natural language. Given a segmented 3D mesh and an editing request, ParSEL produces a parameterized editing program. Adjusting the program parameters allows users to explore shape variations with a precise control over the magnitudes of edits. To infer editing programs which align with an input edit request, we leverage the abilities of large-language models (LLMs). However, while we find that LLMs excel at identifying initial edit operations, they often fail to infer complete editing programs, and produce outputs that violate shape semantics. To overcome this issue, we introduce Analytical Edit Propagation (AEP), an algorithm which extends a seed edit with additional operations until a complete editing program has been formed. Unlike prior methods, AEP searches for analytical editing operations compatible with a range of possible user edits through the integration of computer algebra systems for geometric analysis. Experimentally we demonstrate ParSEL's effectiveness in enabling controllable editing of 3D objects through natural language requests over alternative system designs.
Improving Unsupervised Visual Program Inference with Code Rewriting Families
Sep 26, 2023Programs offer compactness and structure that makes them an attractive representation for visual data. We explore how code rewriting can be used to improve systems for inferring programs from visual data. We first propose Sparse Intermittent Rewrite Injection (SIRI), a framework for unsupervised bootstrapped learning. SIRI sparsely applies code rewrite operations over a dataset of training programs, injecting the improved programs back into the training set. We design a family of rewriters for visual programming domains: parameter optimization, code pruning, and code grafting. For three shape programming languages in 2D and 3D, we show that using SIRI with our family of rewriters improves performance: better reconstructions and faster convergence rates, compared with bootstrapped learning methods that do not use rewriters or use them naively. Finally, we demonstrate that our family of rewriters can be effectively used at test time to improve the output of SIRI predictions. For 2D and 3D CSG, we outperform or match the reconstruction performance of recent domain-specific neural architectures, while producing more parsimonious programs that use significantly fewer primitives.
Warp-Refine Propagation: Semi-Supervised Auto-labeling via Cycle-consistency
Sep 28, 2021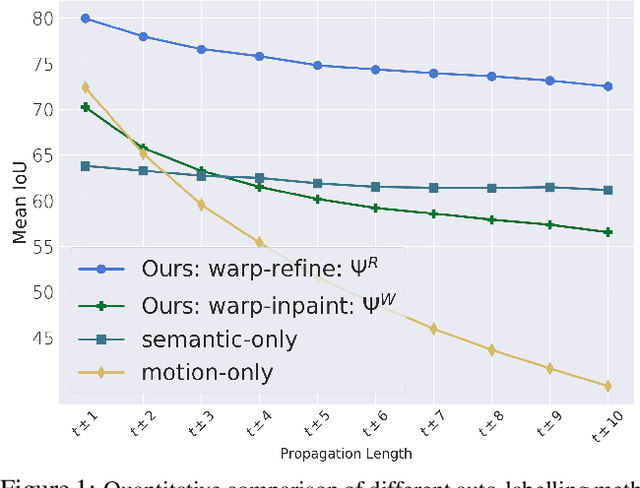
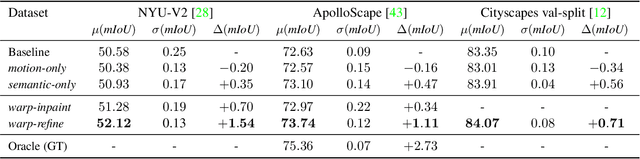
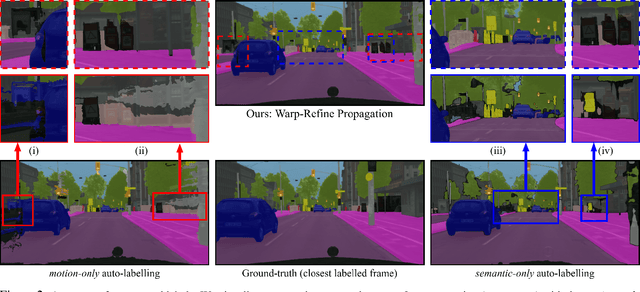

Deep learning models for semantic segmentation rely on expensive, large-scale, manually annotated datasets. Labelling is a tedious process that can take hours per image. Automatically annotating video sequences by propagating sparsely labeled frames through time is a more scalable alternative. In this work, we propose a novel label propagation method, termed Warp-Refine Propagation, that combines semantic cues with geometric cues to efficiently auto-label videos. Our method learns to refine geometrically-warped labels and infuse them with learned semantic priors in a semi-supervised setting by leveraging cycle consistency across time. We quantitatively show that our method improves label-propagation by a noteworthy margin of 13.1 mIoU on the ApolloScape dataset. Furthermore, by training with the auto-labelled frames, we achieve competitive results on three semantic-segmentation benchmarks, improving the state-of-the-art by a large margin of 1.8 and 3.61 mIoU on NYU-V2 and KITTI, while matching the current best results on Cityscapes.
Meta-learning Extractors for Music Source Separation
Feb 17, 2020

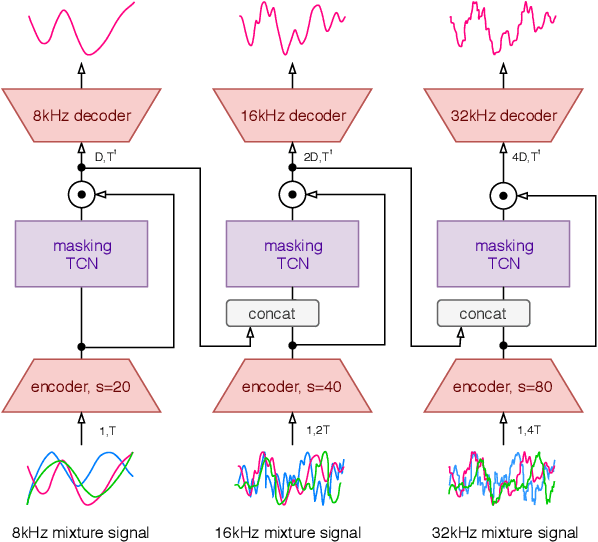

We propose a hierarchical meta-learning-inspired model for music source separation (Meta-TasNet) in which a generator model is used to predict the weights of individual extractor models. This enables efficient parameter-sharing, while still allowing for instrument-specific parameterization. Meta-TasNet is shown to be more effective than the models trained independently or in a multi-task setting, and achieve performance comparable with state-of-the-art methods. In comparison to the latter, our extractors contain fewer parameters and have faster run-time performance. We discuss important architectural considerations, and explore the costs and benefits of this approach.
FDA: Feature Disruptive Attack
Sep 10, 2019
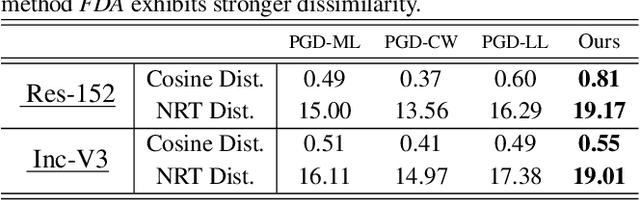
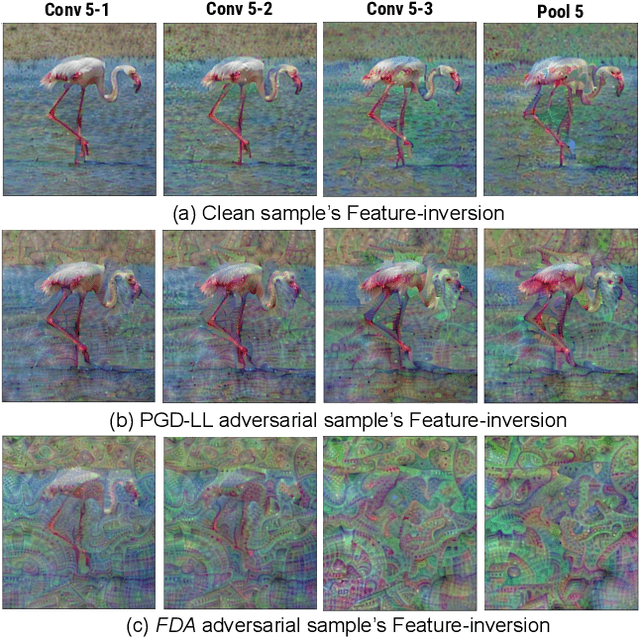
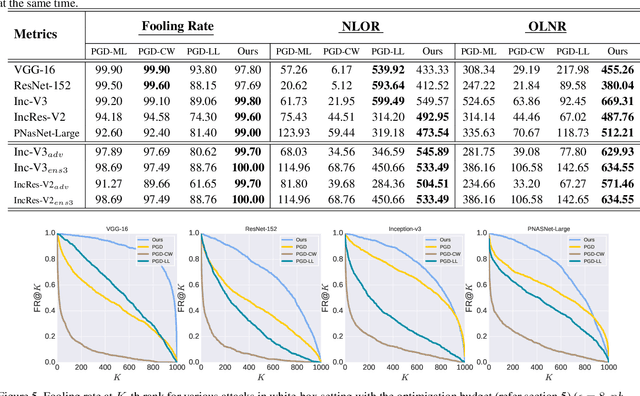
Though Deep Neural Networks (DNN) show excellent performance across various computer vision tasks, several works show their vulnerability to adversarial samples, i.e., image samples with imperceptible noise engineered to manipulate the network's prediction. Adversarial sample generation methods range from simple to complex optimization techniques. Majority of these methods generate adversaries through optimization objectives that are tied to the pre-softmax or softmax output of the network. In this work we, (i) show the drawbacks of such attacks, (ii) propose two new evaluation metrics: Old Label New Rank (OLNR) and New Label Old Rank (NLOR) in order to quantify the extent of damage made by an attack, and (iii) propose a new adversarial attack FDA: Feature Disruptive Attack, to address the drawbacks of existing attacks. FDA works by generating image perturbation that disrupt features at each layer of the network and causes deep-features to be highly corrupt. This allows FDA adversaries to severely reduce the performance of deep networks. We experimentally validate that FDA generates stronger adversaries than other state-of-the-art methods for image classification, even in the presence of various defense measures. More importantly, we show that FDA disrupts feature-representation based tasks even without access to the task-specific network or methodology. Code available at: https://github.com/BardOfCodes/fda
Object Pose Estimation from Monocular Image using Multi-View Keypoint Correspondence
Sep 03, 2018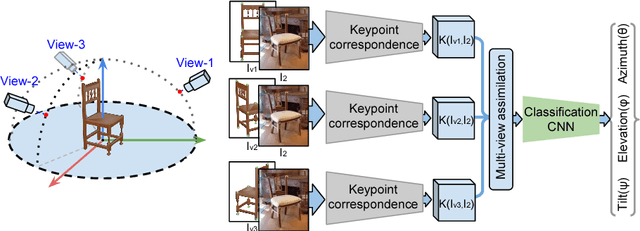

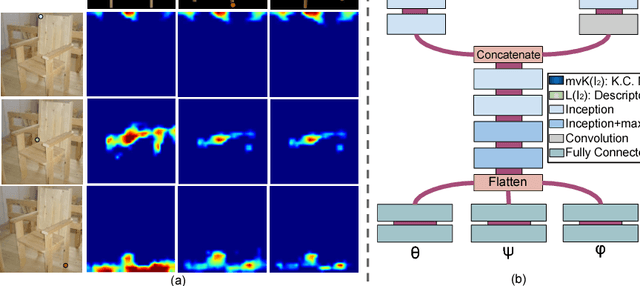
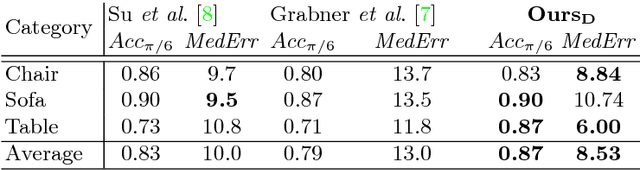
Understanding the geometry and pose of objects in 2D images is a fundamental necessity for a wide range of real world applications. Driven by deep neural networks, recent methods have brought significant improvements to object pose estimation. However, they suffer due to scarcity of keypoint/pose-annotated real images and hence can not exploit the object's 3D structural information effectively. In this work, we propose a data-efficient method which utilizes the geometric regularity of intraclass objects for pose estimation. First, we learn pose-invariant local descriptors of object parts from simple 2D RGB images. These descriptors, along with keypoints obtained from renders of a fixed 3D template model are then used to generate keypoint correspondence maps for a given monocular real image. Finally, a pose estimation network predicts 3D pose of the object using these correspondence maps. This pipeline is further extended to a multi-view approach, which assimilates keypoint information from correspondence sets generated from multiple views of the 3D template model. Fusion of multi-view information significantly improves geometric comprehension of the system which in turn enhances the pose estimation performance. Furthermore, use of correspondence framework responsible for the learning of pose invariant keypoint descriptor also allows us to effectively alleviate the data-scarcity problem. This enables our method to achieve state-of-the-art performance on multiple real-image viewpoint estimation datasets, such as Pascal3D+ and ObjectNet3D. To encourage reproducible research, we have released the codes for our proposed approach.