 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcTex: Consistent and Interactive Text-to-texture Synthesis for Procedural Models
Jan 28, 2025



Recent advancement in 2D image diffusion models has driven significant progress in text-guided texture synthesis, enabling realistic, high-quality texture generation from arbitrary text prompts. However, current methods usually focus on synthesizing texture for single static 3D objects, and struggle to handle entire families of shapes, such as those produced by procedural programs. Applying existing methods naively to each procedural shape is too slow to support exploring different parameter settings at interactive rates, and also results in inconsistent textures across the procedural shapes. To this end, we introduce ProcTex, the first text-to-texture system designed for procedural 3D models. ProcTex enables consistent and real-time text-guided texture synthesis for families of shapes, which integrates seamlessly with the interactive design flow of procedural models. To ensure consistency, our core approach is to generate texture for the shape produced by one setting of the procedural parameters, followed by a texture transfer stage to apply the texture to other parameter settings. We also develop several techniques, including a novel UV displacement network for real-time texture transfer, the retexturing pipeline to support structural changes from discrete procedural parameters, and part-level UV texture map generation for local appearance editing. Extensive experiments on a diverse set of professional procedural models validate ProcTex's ability to produce high-quality, visually consistent textures while supporting real-time, interactive applications.
CLIPtortionist: Zero-shot Text-driven Deformation for Manufactured 3D Shapes
Oct 19, 2024



We propose a zero-shot text-driven 3D shape deformation system that deforms an input 3D mesh of a manufactured object to fit an input text description. To do this, our system optimizes the parameters of a deformation model to maximize an objective function based on the widely used pre-trained vision language model CLIP. We find that CLIP-based objective functions exhibit many spurious local optima; to circumvent them, we parameterize deformations using a novel deformation model called BoxDefGraph which our system automatically computes from an input mesh, the BoxDefGraph is designed to capture the object aligned rectangular/circular geometry features of most manufactured objects. We then use the CMA-ES global optimization algorithm to maximize our objective, which we find to work better than popular gradient-based optimizers. We demonstrate that our approach produces appealing results and outperforms several baselines.
ParSEL: Parameterized Shape Editing with Language
May 31, 2024The ability to edit 3D assets from natural language presents a compelling paradigm to aid in the democratization of 3D content creation. However, while natural language is often effective at communicating general intent, it is poorly suited for specifying precise manipulation. To address this gap, we introduce ParSEL, a system that enables controllable editing of high-quality 3D assets from natural language. Given a segmented 3D mesh and an editing request, ParSEL produces a parameterized editing program. Adjusting the program parameters allows users to explore shape variations with a precise control over the magnitudes of edits. To infer editing programs which align with an input edit request, we leverage the abilities of large-language models (LLMs). However, while we find that LLMs excel at identifying initial edit operations, they often fail to infer complete editing programs, and produce outputs that violate shape semantics. To overcome this issue, we introduce Analytical Edit Propagation (AEP), an algorithm which extends a seed edit with additional operations until a complete editing program has been formed. Unlike prior methods, AEP searches for analytical editing operations compatible with a range of possible user edits through the integration of computer algebra systems for geometric analysis. Experimentally we demonstrate ParSEL's effectiveness in enabling controllable editing of 3D objects through natural language requests over alternative system designs.
Unsupervised 3D Shape Reconstruction by Part Retrieval and Assembly
Mar 03, 2023



Representing a 3D shape with a set of primitives can aid perception of structure, improve robotic object manipulation, and enable editing, stylization, and compression of 3D shapes. Existing methods either use simple parametric primitives or learn a generative shape space of parts. Both have limitations: parametric primitives lead to coarse approximations, while learned parts offer too little control over the decomposition. We instead propose to decompose shapes using a library of 3D parts provided by the user, giving full control over the choice of parts. The library can contain parts with high-quality geometry that are suitable for a given category, resulting in meaningful decompositions with clean geometry. The type of decomposition can also be controlled through the choice of parts in the library. Our method works via a self-supervised approach that iteratively retrieves parts from the library and refines their placements. We show that this approach gives higher reconstruction accuracy and more desirable decompositions than existing approaches. Additionally, we show how the decomposition can be controlled through the part library by using different part libraries to reconstruct the same shapes.
Unsupervised Kinematic Motion Detection for Part-segmented 3D Shape Collections
Jun 17, 2022
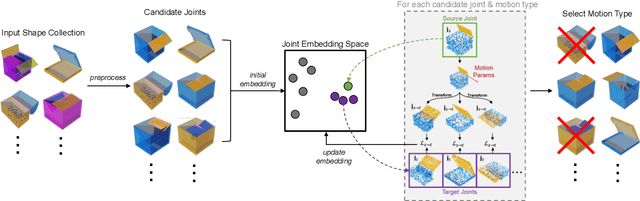

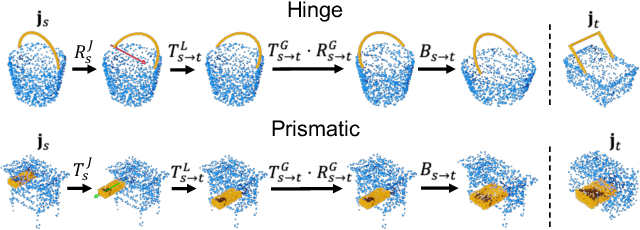
3D models of manufactured objects are important for populating virtual worlds and for synthetic data generation for vision and robotics. To be most useful, such objects should be articulated: their parts should move when interacted with. While articulated object datasets exist, creating them is labor-intensive. Learning-based prediction of part motions can help, but all existing methods require annotated training data. In this paper, we present an unsupervised approach for discovering articulated motions in a part-segmented 3D shape collection. Our approach is based on a concept we call category closure: any valid articulation of an object's parts should keep the object in the same semantic category (e.g. a chair stays a chair). We operationalize this concept with an algorithm that optimizes a shape's part motion parameters such that it can transform into other shapes in the collection. We evaluate our approach by using it to re-discover part motions from the PartNet-Mobility dataset. For almost all shape categories, our method's predicted motion parameters have low error with respect to ground truth annotations, outperforming two supervised motion prediction methods.
Roominoes: Generating Novel 3D Floor Plans From Existing 3D Rooms
Dec 10, 2021Realistic 3D indoor scene datasets have enabled significant recent progress in computer vision, scene understanding, autonomous navigation, and 3D reconstruction. But the scale, diversity, and customizability of existing datasets is limited, and it is time-consuming and expensive to scan and annotate more. Fortunately, combinatorics is on our side: there are enough individual rooms in existing 3D scene datasets, if there was but a way to recombine them into new layouts. In this paper, we propose the task of generating novel 3D floor plans from existing 3D rooms. We identify three sub-tasks of this problem: generation of 2D layout, retrieval of compatible 3D rooms, and deformation of 3D rooms to fit the layout. We then discuss different strategies for solving the problem, and design two representative pipelines: one uses available 2D floor plans to guide selection and deformation of 3D rooms; the other learns to retrieve a set of compatible 3D rooms and combine them into novel layouts. We design a set of metrics that evaluate the generated results with respect to each of the three subtasks and show that different methods trade off performance on these subtasks. Finally, we survey downstream tasks that benefit from generated 3D scenes and discuss strategies in selecting the methods most appropriate for the demands of these tasks.
* Symposium on Geometry Processing (SGP) 2021
ShapeAssembly: Learning to Generate Programs for 3D Shape Structure Synthesis
Sep 17, 2020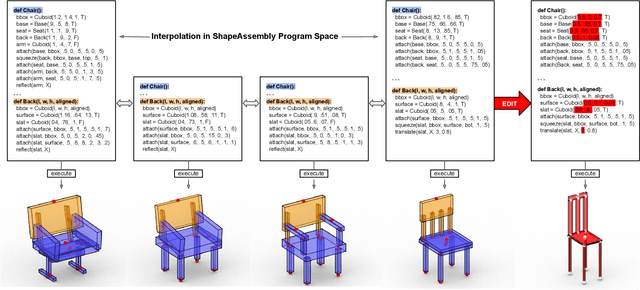
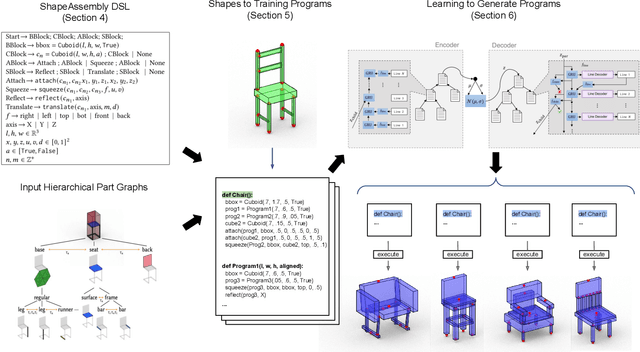
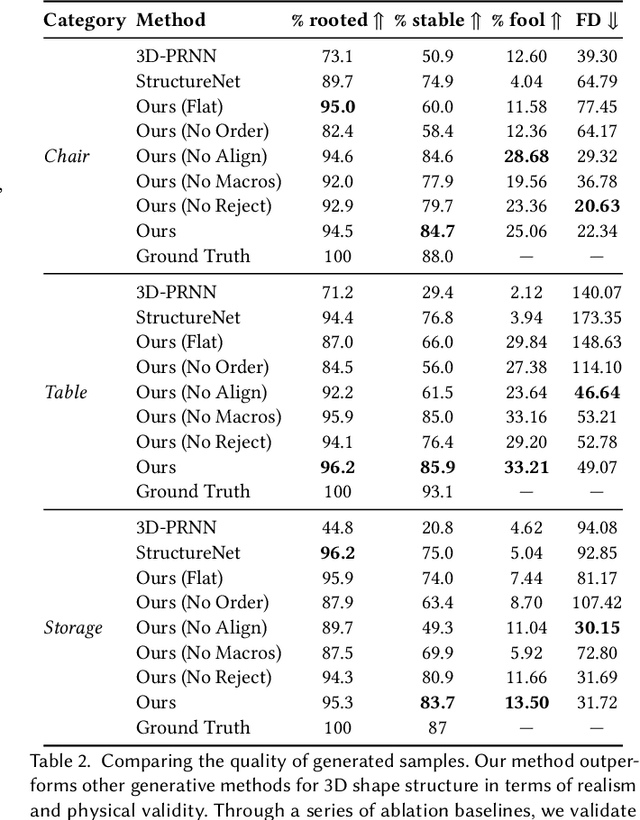
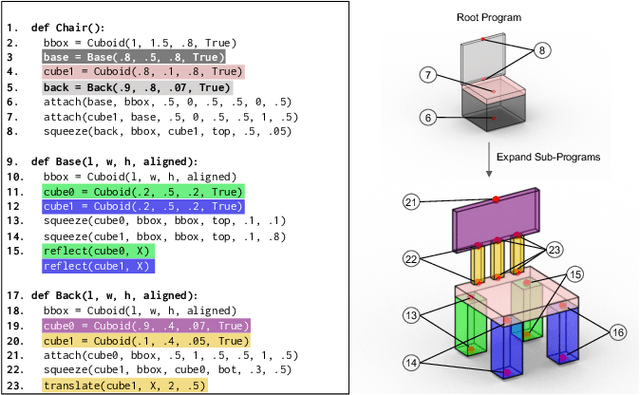
Manually authoring 3D shapes is difficult and time consuming; generative models of 3D shapes offer compelling alternatives. Procedural representations are one such possibility: they offer high-quality and editable results but are difficult to author and often produce outputs with limited diversity. On the other extreme are deep generative models: given enough data, they can learn to generate any class of shape but their outputs have artifacts and the representation is not editable. In this paper, we take a step towards achieving the best of both worlds for novel 3D shape synthesis. We propose ShapeAssembly, a domain-specific "assembly-language" for 3D shape structures. ShapeAssembly programs construct shapes by declaring cuboid part proxies and attaching them to one another, in a hierarchical and symmetrical fashion. Its functions are parameterized with free variables, so that one program structure is able to capture a family of related shapes. We show how to extract ShapeAssembly programs from existing shape structures in the PartNet dataset. Then we train a deep generative model, a hierarchical sequence VAE, that learns to write novel ShapeAssembly programs. The program captures the subset of variability that is interpretable and editable. The deep model captures correlations across shape collections that are hard to express procedurally. We evaluate our approach by comparing shapes output by our generated programs to those from other recent shape structure synthesis models. We find that our generated shapes are more plausible and physically-valid than those of other methods. Additionally, we assess the latent spaces of these models, and find that ours is better structured and produces smoother interpolations. As an application, we use our generative model and differentiable program interpreter to infer and fit shape programs to unstructured geometry, such as point clouds.