 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot All Flips Are Conformity: Decomposing Stance Convergence in Multi-Agent LLM Debate
May 30, 2026Multi-agent debate (MAD) is a promising strategy for improving LLM reasoning, but when agents converge on a shared answer, it is unclear whether that convergence reflects genuine deliberation or social compliance. We show that the conventional answer flip rate conflates three distinct mechanisms: spontaneous instability, stance-induced conformity, and reasoning-induced persuasion. Our three-source decomposition framework isolates each through controlled counterfactual conditions. In the primary MMLU-Pro setting, 37% of agent-question observations change under self-reflection alone, while robustness tests show substantial model-dependent instability across GPQA-Diamond and three model families; strict conformity is 29% in the primary setting and remains predominantly harmful across model replications (57-77% correct-to-wrong). A controlled information-gradient experiment reveals that even vacuous reasoning is associated with 20-39% error adoption among resistant agents, with reasoning-like presentation carrying substantial persuasive weight. Harmful conformity can be predicted from Round 0 features (AUC = 0.79), and risk-targeted intervention reduces it by 13.6 percentage points (p < 0.001). However, without correctness labels or self-reflection controls, reducing peer adoption does not improve accuracy, because harmful and beneficial influence cannot be distinguished.
ProcTex: Consistent and Interactive Text-to-texture Synthesis for Procedural Models
Jan 28, 2025



Recent advancement in 2D image diffusion models has driven significant progress in text-guided texture synthesis, enabling realistic, high-quality texture generation from arbitrary text prompts. However, current methods usually focus on synthesizing texture for single static 3D objects, and struggle to handle entire families of shapes, such as those produced by procedural programs. Applying existing methods naively to each procedural shape is too slow to support exploring different parameter settings at interactive rates, and also results in inconsistent textures across the procedural shapes. To this end, we introduce ProcTex, the first text-to-texture system designed for procedural 3D models. ProcTex enables consistent and real-time text-guided texture synthesis for families of shapes, which integrates seamlessly with the interactive design flow of procedural models. To ensure consistency, our core approach is to generate texture for the shape produced by one setting of the procedural parameters, followed by a texture transfer stage to apply the texture to other parameter settings. We also develop several techniques, including a novel UV displacement network for real-time texture transfer, the retexturing pipeline to support structural changes from discrete procedural parameters, and part-level UV texture map generation for local appearance editing. Extensive experiments on a diverse set of professional procedural models validate ProcTex's ability to produce high-quality, visually consistent textures while supporting real-time, interactive applications.
Combining Cloud and Mobile Computing for Machine Learning
Jan 20, 2024



Although the computing power of mobile devices is increasing, machine learning models are also growing in size. This trend creates problems for mobile devices due to limitations like their memory capacity and battery life. While many services, like ChatGPT and Midjourney, run all the inferences in the cloud, we believe a flexible and fine-grained task distribution is more desirable. In this work, we consider model segmentation as a solution to improving the user experience, dividing the computation between mobile devices and the cloud in a way that offloads the compute-heavy portion of the model while minimizing the data transfer required. We show that the division not only reduces the wait time for users but can also be fine-tuned to optimize the workloads of the cloud. To achieve that, we design a scheduler that collects information about network quality, client device capability, and job requirements, making decisions to achieve consistent performance across a range of devices while reducing the work the cloud needs to perform.
Specializing Small Language Models towards Complex Style Transfer via Latent Attribute Pre-Training
Sep 19, 2023



In this work, we introduce the concept of complex text style transfer tasks, and constructed complex text datasets based on two widely applicable scenarios. Our dataset is the first large-scale data set of its kind, with 700 rephrased sentences and 1,000 sentences from the game Genshin Impact. While large language models (LLM) have shown promise in complex text style transfer, they have drawbacks such as data privacy concerns, network instability, and high deployment costs. To address these issues, we explore the effectiveness of small models (less than T5-3B) with implicit style pre-training through contrastive learning. We also propose a method for automated evaluation of text generation quality based on alignment with human evaluations using ChatGPT. Finally, we compare our approach with existing methods and show that our model achieves state-of-art performances of few-shot text style transfer models.
Non-Transferable Learning: A New Approach for Model Verification and Authorization
Jun 13, 2021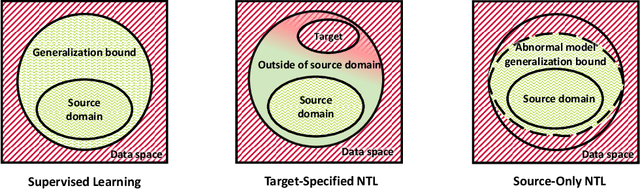

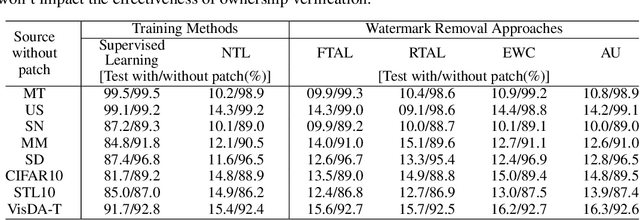

As Artificial Intelligence as a Service gains popularity, protecting well-trained models as intellectual property is becoming increasingly important. Generally speaking, there are two common protection methods: ownership verification and usage authorization. In this paper, we propose Non-Transferable Learning (NTL), a novel approach that captures the exclusive data representation in the learned model and restricts the model generalization ability to certain domains. This approach provides effective solutions to both model verification and authorization. For ownership verification, watermarking techniques are commonly used but are often vulnerable to sophisticated watermark removal methods. Our NTL-based model verification approach instead provides robust resistance to state-of-the-art watermark removal methods, as shown in extensive experiments for four of such methods over the digits, CIFAR10 & STL10, and VisDA datasets. For usage authorization, prior solutions focus on authorizing specific users to use the model, but authorized users can still apply the model to any data without restriction. Our NTL-based authorization approach instead provides data-centric usage protection by significantly degrading the performance of usage on unauthorized data. Its effectiveness is also shown through experiments on a variety of datasets.