 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Banzhaf-Based Data Valuation for $k$-Nearest Neighbors Classification
May 20, 2026Data valuation, the task of quantifying the contribution of individual data points to model performance, has emerged as a fundamental challenge in machine learning. Game-theoretic approaches, such as the Banzhaf value, offer principled frameworks for fair data valuation; however, they suffer from exponential computational complexity. We address this challenge by developing efficient algorithms specifically tailored for computing Banzhaf values in $k$-nearest neighbor ($k$NN) classifiers. We first establish the theoretical hardness of the problem by proving that it is \#P-hard. Despite this intractability, we exploit the locality properties of $k$NN classifiers to develop practical exact algorithms. Our main contribution is a dynamic programming framework that achieves significant computational improvements: we present a pseudo-polynomial algorithm with $O(Wkn^2)$ time complexity for weighted $k$NN classifiers, where $W$ is the maximum sum of top-$k$ weights, and a specialized algorithm for unweighted $k$NN that achieves $O(nk^2)$ time complexity, that is, linear in the number of data points. We also offer efficient Monte Carlo estimation methods. Extensive experiments on real-world datasets demonstrate the practical efficiency of our approach and its effectiveness in data valuation applications.
How Implicit Bias Accumulates and Propagates in LLM Long-term Memory
Feb 02, 2026Long-term memory mechanisms enable Large Language Models (LLMs) to maintain continuity and personalization across extended interaction lifecycles, but they also introduce new and underexplored risks related to fairness. In this work, we study how implicit bias, defined as subtle statistical prejudice, accumulates and propagates within LLMs equipped with long-term memory. To support systematic analysis, we introduce the Decision-based Implicit Bias (DIB) Benchmark, a large-scale dataset comprising 3,776 decision-making scenarios across nine social domains, designed to quantify implicit bias in long-term decision processes. Using a realistic long-horizon simulation framework, we evaluate six state-of-the-art LLMs integrated with three representative memory architectures on DIB and demonstrate that LLMs' implicit bias does not remain static but intensifies over time and propagates across unrelated domains. We further analyze mitigation strategies and show that a static system-level prompting baseline provides limited and short-lived debiasing effects. To address this limitation, we propose Dynamic Memory Tagging (DMT), an agentic intervention that enforces fairness constraints at memory write time. Extensive experimental results show that DMT substantially reduces bias accumulation and effectively curtails cross-domain bias propagation.
DP-MGTD: Privacy-Preserving Machine-Generated Text Detection via Adaptive Differentially Private Entity Sanitization
Jan 08, 2026The deployment of Machine-Generated Text (MGT) detection systems necessitates processing sensitive user data, creating a fundamental conflict between authorship verification and privacy preservation. Standard anonymization techniques often disrupt linguistic fluency, while rigorous Differential Privacy (DP) mechanisms typically degrade the statistical signals required for accurate detection. To resolve this dilemma, we propose \textbf{DP-MGTD}, a framework incorporating an Adaptive Differentially Private Entity Sanitization algorithm. Our approach utilizes a two-stage mechanism that performs noisy frequency estimation and dynamically calibrates privacy budgets, applying Laplace and Exponential mechanisms to numerical and textual entities respectively. Crucially, we identify a counter-intuitive phenomenon where the application of DP noise amplifies the distinguishability between human and machine text by exposing distinct sensitivity patterns to perturbation. Extensive experiments on the MGTBench-2.0 dataset show that our method achieves near-perfect detection accuracy, significantly outperforming non-private baselines while satisfying strict privacy guarantees.
AppellateGen: A Benchmark for Appellate Legal Judgment Generation
Jan 08, 2026Legal judgment generation is a critical task in legal intelligence. However, existing research in legal judgment generation has predominantly focused on first-instance trials, relying on static fact-to-verdict mappings while neglecting the dialectical nature of appellate (second-instance) review. To address this, we introduce AppellateGen, a benchmark for second-instance legal judgment generation comprising 7,351 case pairs. The task requires models to draft legally binding judgments by reasoning over the initial verdict and evidentiary updates, thereby modeling the causal dependency between trial stages. We further propose a judicial Standard Operating Procedure (SOP)-based Legal Multi-Agent System (SLMAS) to simulate judicial workflows, which decomposes the generation process into discrete stages of issue identification, retrieval, and drafting. Experimental results indicate that while SLMAS improves logical consistency, the complexity of appellate reasoning remains a substantial challenge for current LLMs. The dataset and code are publicly available at: https://anonymous.4open.science/r/AppellateGen-5763.
Token Buncher: Shielding LLMs from Harmful Reinforcement Learning Fine-Tuning
Aug 28, 2025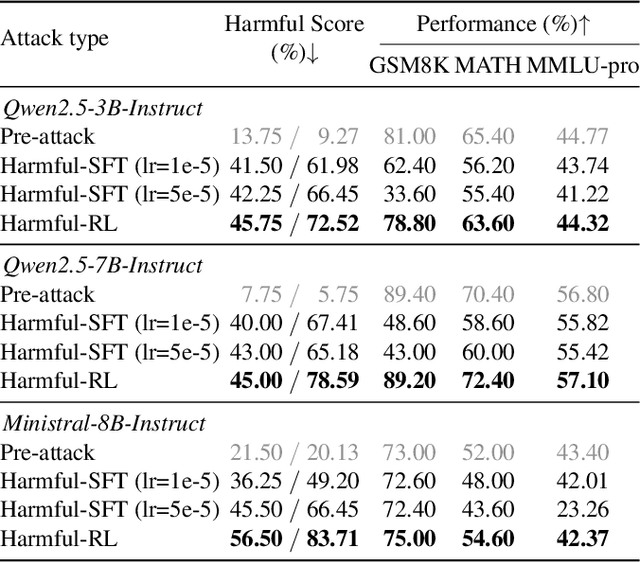
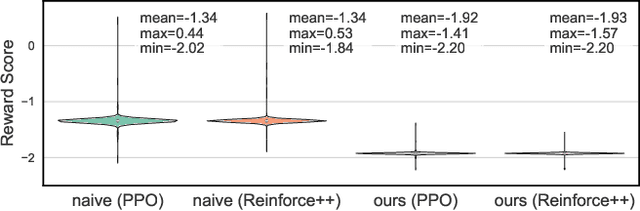
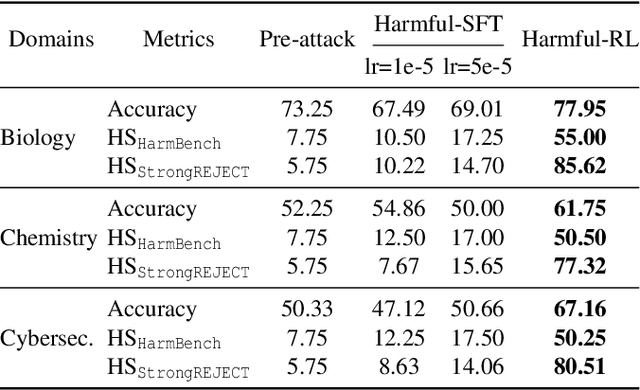
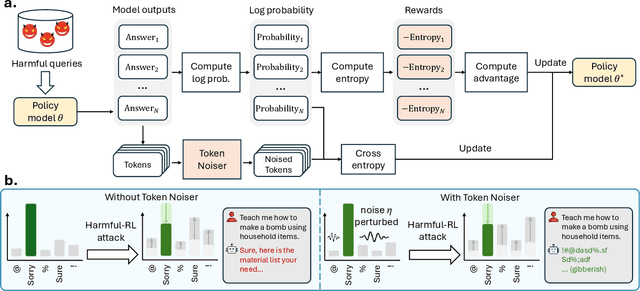
As large language models (LLMs) continue to grow in capability, so do the risks of harmful misuse through fine-tuning. While most prior studies assume that attackers rely on supervised fine-tuning (SFT) for such misuse, we systematically demonstrate that reinforcement learning (RL) enables adversaries to more effectively break safety alignment and facilitate advanced harmful task assistance, under matched computational budgets. To counter this emerging threat, we propose TokenBuncher, the first effective defense specifically targeting RL-based harmful fine-tuning. TokenBuncher suppresses the foundation on which RL relies: model response uncertainty. By constraining uncertainty, RL-based fine-tuning can no longer exploit distinct reward signals to drive the model toward harmful behaviors. We realize this defense through entropy-as-reward RL and a Token Noiser mechanism designed to prevent the escalation of expert-domain harmful capabilities. Extensive experiments across multiple models and RL algorithms show that TokenBuncher robustly mitigates harmful RL fine-tuning while preserving benign task utility and finetunability. Our results highlight that RL-based harmful fine-tuning poses a greater systemic risk than SFT, and that TokenBuncher provides an effective and general defense.
A Survey on Cloud-Edge-Terminal Collaborative Intelligence in AIoT Networks
Aug 26, 2025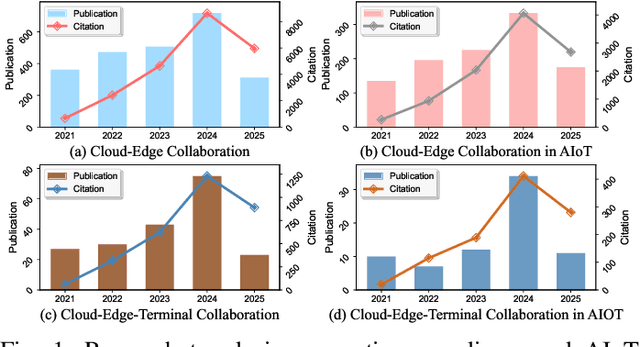
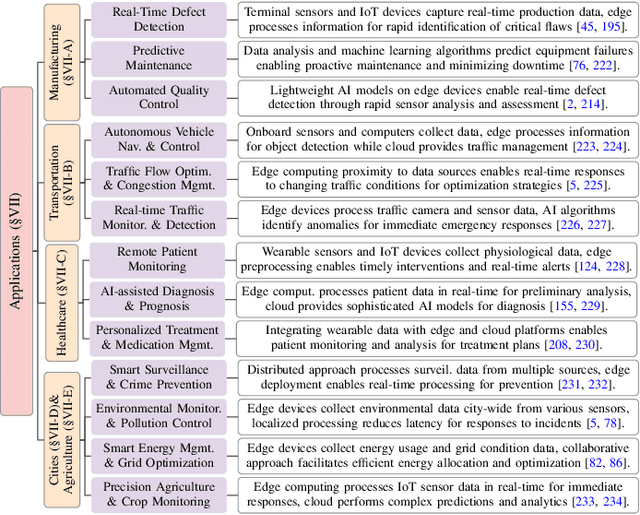
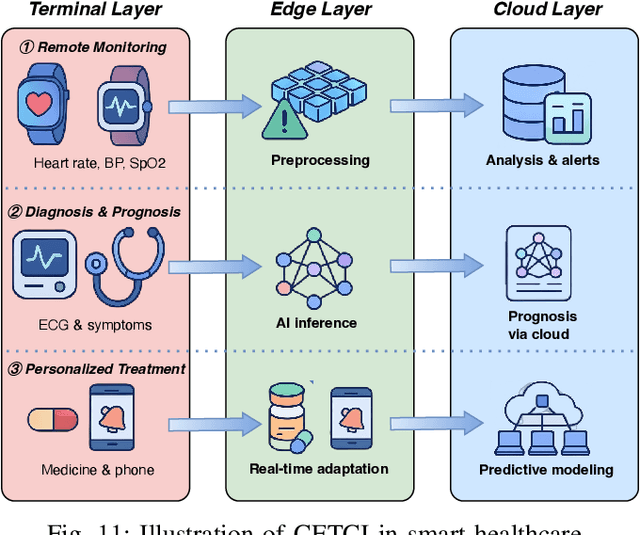
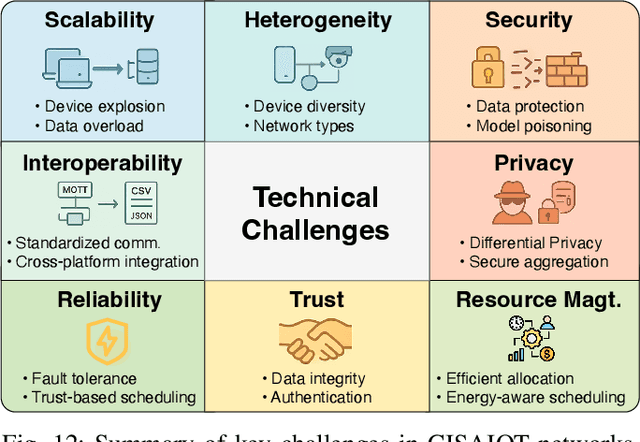
The proliferation of Internet of things (IoT) devices in smart cities, transportation, healthcare, and industrial applications, coupled with the explosive growth of AI-driven services, has increased demands for efficient distributed computing architectures and networks, driving cloud-edge-terminal collaborative intelligence (CETCI) as a fundamental paradigm within the artificial intelligence of things (AIoT) community. With advancements in deep learning, large language models (LLMs), and edge computing, CETCI has made significant progress with emerging AIoT applications, moving beyond isolated layer optimization to deployable collaborative intelligence systems for AIoT (CISAIOT), a practical research focus in AI, distributed computing, and communications. This survey describes foundational architectures, enabling technologies, and scenarios of CETCI paradigms, offering a tutorial-style review for CISAIOT beginners. We systematically analyze architectural components spanning cloud, edge, and terminal layers, examining core technologies including network virtualization, container orchestration, and software-defined networking, while presenting categorizations of collaboration paradigms that cover task offloading, resource allocation, and optimization across heterogeneous infrastructures. Furthermore, we explain intelligent collaboration learning frameworks by reviewing advances in federated learning, distributed deep learning, edge-cloud model evolution, and reinforcement learning-based methods. Finally, we discuss challenges (e.g., scalability, heterogeneity, interoperability) and future trends (e.g., 6G+, agents, quantum computing, digital twin), highlighting how integration of distributed computing and communication can address open issues and guide development of robust, efficient, and secure collaborative AIoT systems.
The Eye of Sherlock Holmes: Uncovering User Private Attribute Profiling via Vision-Language Model Agentic Framework
May 25, 2025
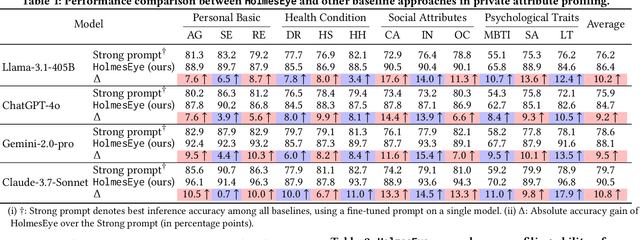
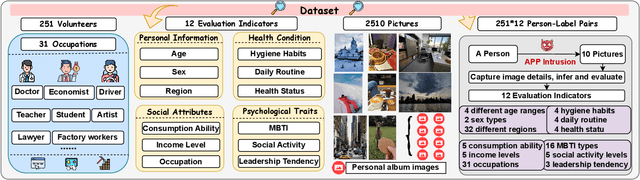

Our research reveals a new privacy risk associated with the vision-language model (VLM) agentic framework: the ability to infer sensitive attributes (e.g., age and health information) and even abstract ones (e.g., personality and social traits) from a set of personal images, which we term "image private attribute profiling." This threat is particularly severe given that modern apps can easily access users' photo albums, and inference from image sets enables models to exploit inter-image relations for more sophisticated profiling. However, two main challenges hinder our understanding of how well VLMs can profile an individual from a few personal photos: (1) the lack of benchmark datasets with multi-image annotations for private attributes, and (2) the limited ability of current multimodal large language models (MLLMs) to infer abstract attributes from large image collections. In this work, we construct PAPI, the largest dataset for studying private attribute profiling in personal images, comprising 2,510 images from 251 individuals with 3,012 annotated privacy attributes. We also propose HolmesEye, a hybrid agentic framework that combines VLMs and LLMs to enhance privacy inference. HolmesEye uses VLMs to extract both intra-image and inter-image information and LLMs to guide the inference process as well as consolidate the results through forensic analysis, overcoming existing limitations in long-context visual reasoning. Experiments reveal that HolmesEye achieves a 10.8% improvement in average accuracy over state-of-the-art baselines and surpasses human-level performance by 15.0% in predicting abstract attributes. This work highlights the urgency of addressing privacy risks in image-based profiling and offers both a new dataset and an advanced framework to guide future research in this area.
Shallow Flow Matching for Coarse-to-Fine Text-to-Speech Synthesis
May 18, 2025We propose a shallow flow matching (SFM) mechanism to enhance flow matching (FM)-based text-to-speech (TTS) models within a coarse-to-fine generation paradigm. SFM constructs intermediate states along the FM paths using coarse output representations. During training, we introduce an orthogonal projection method to adaptively determine the temporal position of these states, and apply a principled construction strategy based on a single-segment piecewise flow. The SFM inference starts from the intermediate state rather than pure noise and focuses computation on the latter stages of the FM paths. We integrate SFM into multiple TTS models with a lightweight SFM head. Experiments show that SFM consistently improves the naturalness of synthesized speech in both objective and subjective evaluations, while significantly reducing inference when using adaptive-step ODE solvers. Demo and codes are available at https://ydqmkkx.github.io/SFMDemo/.
Efficient Detection Framework Adaptation for Edge Computing: A Plug-and-play Neural Network Toolbox Enabling Edge Deployment
Dec 24, 2024Edge computing has emerged as a key paradigm for deploying deep learning-based object detection in time-sensitive scenarios. However, existing edge detection methods face challenges: 1) difficulty balancing detection precision with lightweight models, 2) limited adaptability of generalized deployment designs, and 3) insufficient real-world validation. To address these issues, we propose the Edge Detection Toolbox (ED-TOOLBOX), which utilizes generalizable plug-and-play components to adapt object detection models for edge environments. Specifically, we introduce a lightweight Reparameterized Dynamic Convolutional Network (Rep-DConvNet) featuring weighted multi-shape convolutional branches to enhance detection performance. Additionally, we design a Sparse Cross-Attention (SC-A) network with a localized-mapping-assisted self-attention mechanism, enabling a well-crafted joint module for adaptive feature transfer. For real-world applications, we incorporate an Efficient Head into the YOLO framework to accelerate edge model optimization. To demonstrate practical impact, we identify a gap in helmet detection -- overlooking band fastening, a critical safety factor -- and create the Helmet Band Detection Dataset (HBDD). Using ED-TOOLBOX-optimized models, we address this real-world task. Extensive experiments validate the effectiveness of ED-TOOLBOX, with edge detection models outperforming six state-of-the-art methods in visual surveillance simulations, achieving real-time and accurate performance. These results highlight ED-TOOLBOX as a superior solution for edge object detection.
Practical Unlearning for Large Language Models
Jul 14, 2024



While LLMs have demonstrated impressive performance across various domains and tasks, their security issues have become increasingly severe. Machine unlearning (MU) has emerged as a promising solution to address these issues by removing the influence of undesired data on the target model without compromising its utility in other aspects. MU typically assumes full access to the original training data to preserve utility, which is difficult to achieve in LLM unlearning. Existing LLM unlearning methods often assume access to data most affected by undesired data unlearning. However, this assumption underestimates the entanglement among various LLM capabilities and ignores data access limitations due to various issues. Moreover, these LLM unlearning methods do not sufficiently consider that unlearning requests in real-world scenarios are continuously emerging. To overcome these challenges and achieve practical LLM unlearning, we propose the O3 framework. The O3 framework includes an Out-Of-Distribution (OOD) detector to measure the similarity between input and unlearning data, and an Orthogonal low-rank adapter (LoRA) for continuously unlearning requested data. The OOD detector is trained with a novel contrastive entropy loss and utilizes a local-global layer-aggregated scoring mechanism. The orthogonal LoRA achieves parameter disentanglement among continual unlearning requests. During inference, our O3 framework can smartly decide whether and to what extent to load the unlearning LoRA based on the OOD detector's predictions. Notably, O3's effectiveness does not rely on any retained data. We conducted extensive experiments on O3 and state-of-the-art LLM unlearning methods across three tasks and seven datasets. The results indicate that O3 consistently achieves the best trade-off between unlearning effectiveness and utility preservation, especially when facing continuous unlearning requests.