 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
PnP-U3D: Plug-and-Play 3D Framework Bridging Autoregression and Diffusion for Unified Understanding and Generation
Feb 03, 2026The rapid progress of large multimodal models has inspired efforts toward unified frameworks that couple understanding and generation. While such paradigms have shown remarkable success in 2D, extending them to 3D remains largely underexplored. Existing attempts to unify 3D tasks under a single autoregressive (AR) paradigm lead to significant performance degradation due to forced signal quantization and prohibitive training cost. Our key insight is that the essential challenge lies not in enforcing a unified autoregressive paradigm, but in enabling effective information interaction between generation and understanding while minimally compromising their inherent capabilities and leveraging pretrained models to reduce training cost. Guided by this perspective, we present the first unified framework for 3D understanding and generation that combines autoregression with diffusion. Specifically, we adopt an autoregressive next-token prediction paradigm for 3D understanding, and a continuous diffusion paradigm for 3D generation. A lightweight transformer bridges the feature space of large language models and the conditional space of 3D diffusion models, enabling effective cross-modal information exchange while preserving the priors learned by standalone models. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across diverse 3D understanding and generation benchmarks, while also excelling in 3D editing tasks. These results highlight the potential of unified AR+diffusion models as a promising direction for building more general-purpose 3D intelligence.
PI-Light: Physics-Inspired Diffusion for Full-Image Relighting
Jan 29, 2026Full-image relighting remains a challenging problem due to the difficulty of collecting large-scale structured paired data, the difficulty of maintaining physical plausibility, and the limited generalizability imposed by data-driven priors. Existing attempts to bridge the synthetic-to-real gap for full-scene relighting remain suboptimal. To tackle these challenges, we introduce Physics-Inspired diffusion for full-image reLight ($π$-Light, or PI-Light), a two-stage framework that leverages physics-inspired diffusion models. Our design incorporates (i) batch-aware attention, which improves the consistency of intrinsic predictions across a collection of images, (ii) a physics-guided neural rendering module that enforces physically plausible light transport, (iii) physics-inspired losses that regularize training dynamics toward a physically meaningful landscape, thereby enhancing generalizability to real-world image editing, and (iv) a carefully curated dataset of diverse objects and scenes captured under controlled lighting conditions. Together, these components enable efficient finetuning of pretrained diffusion models while also providing a solid benchmark for downstream evaluation. Experiments demonstrate that $π$-Light synthesizes specular highlights and diffuse reflections across a wide variety of materials, achieving superior generalization to real-world scenes compared with prior approaches.
Trainable Log-linear Sparse Attention for Efficient Diffusion Transformers
Dec 18, 2025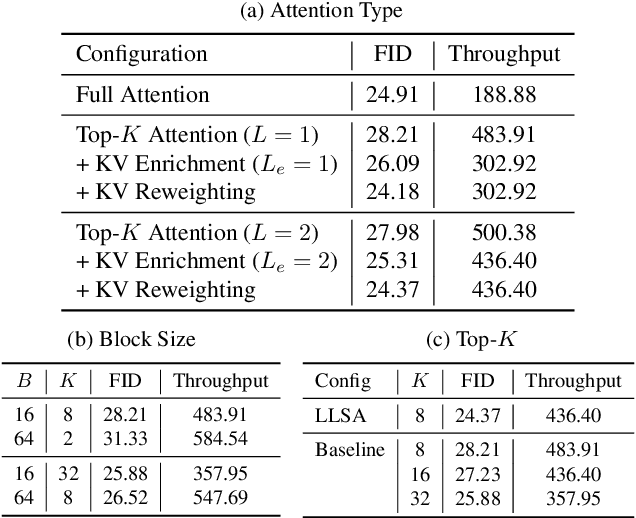
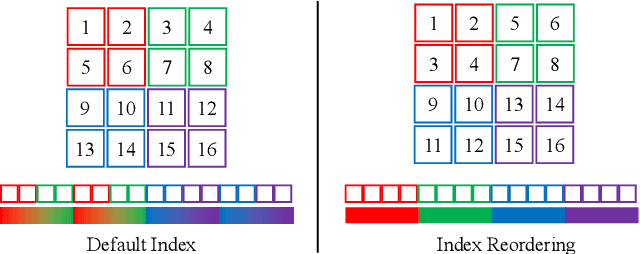
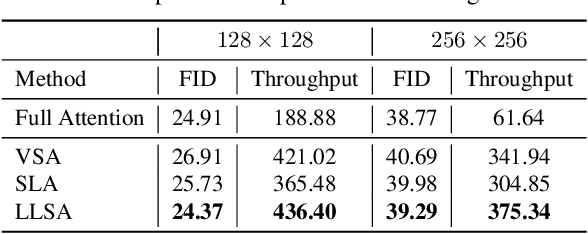
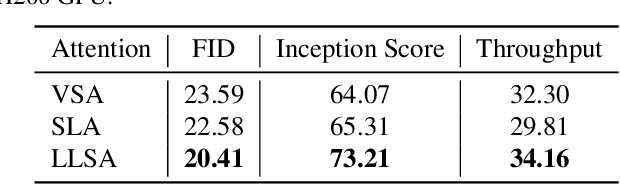
Diffusion Transformers (DiTs) set the state of the art in visual generation, yet their quadratic self-attention cost fundamentally limits scaling to long token sequences. Recent Top-K sparse attention approaches reduce the computation of DiTs by compressing tokens into block-wise representation and selecting a small set of relevant key blocks, but still suffer from (i) quadratic selection cost on compressed tokens and (ii) increasing K required to maintain model quality as sequences grow. We identify that their inefficiency is due to the single-level design, as a single coarse level is insufficient to represent the global structure. In this paper, we introduce Log-linear Sparse Attention (LLSA), a trainable sparse attention mechanism for extremely long token sequences that reduces both selection and attention costs from quadratic to log-linear complexity by utilizing a hierarchical structure. LLSA performs hierarchical Top-K selection, progressively adopting sparse Top-K selection with the indices found at the previous level, and introduces a Hierarchical KV Enrichment mechanism that preserves global context while using fewer tokens of different granularity during attention computation. To support efficient training, we develop a high-performance GPU implementation that uses only sparse indices for both the forward and backward passes, eliminating the need for dense attention masks. We evaluate LLSA on high-resolution pixel-space image generation without using patchification and VAE encoding. LLSA accelerates attention inference by 28.27x and DiT training by 6.09x on 256x256 pixel token sequences, while maintaining generation quality. The results demonstrate that LLSA offers a promising direction for training long-sequence DiTs efficiently. Code is available at: https://github.com/SingleZombie/LLSA
BokehDepth: Enhancing Monocular Depth Estimation through Bokeh Generation
Dec 13, 2025Bokeh and monocular depth estimation are tightly coupled through the same lens imaging geometry, yet current methods exploit this connection in incomplete ways. High-quality bokeh rendering pipelines typically depend on noisy depth maps, which amplify estimation errors into visible artifacts, while modern monocular metric depth models still struggle on weakly textured, distant and geometrically ambiguous regions where defocus cues are most informative. We introduce BokehDepth, a two-stage framework that decouples bokeh synthesis from depth prediction and treats defocus as an auxiliary supervision-free geometric cue. In Stage-1, a physically guided controllable bokeh generator, built on a powerful pretrained image editing backbone, produces depth-free bokeh stacks with calibrated bokeh strength from a single sharp input. In Stage-2, a lightweight defocus-aware aggregation module plugs into existing monocular depth encoders, fuses features along the defocus dimension, and exposes stable depth-sensitive variations while leaving downstream decoder unchanged. Across challenging benchmarks, BokehDepth improves visual fidelity over depth-map-based bokeh baselines and consistently boosts the metric accuracy and robustness of strong monocular depth foundation models.
Token Buncher: Shielding LLMs from Harmful Reinforcement Learning Fine-Tuning
Aug 28, 2025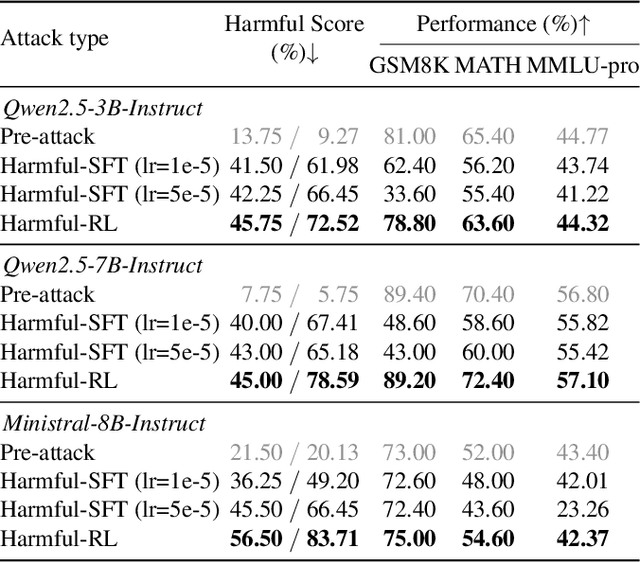
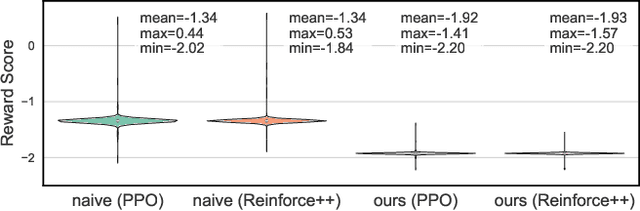
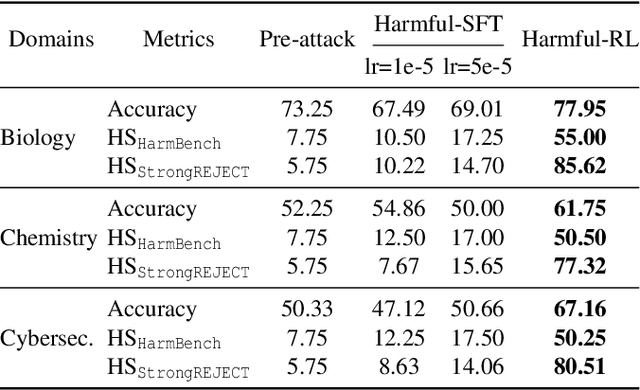
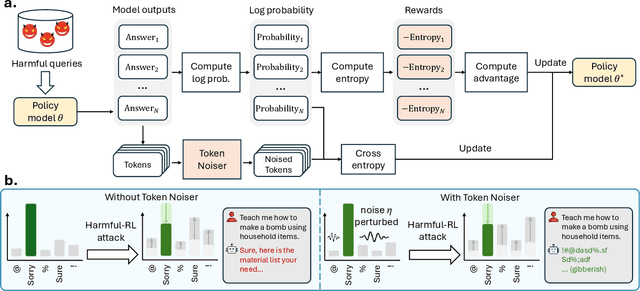
As large language models (LLMs) continue to grow in capability, so do the risks of harmful misuse through fine-tuning. While most prior studies assume that attackers rely on supervised fine-tuning (SFT) for such misuse, we systematically demonstrate that reinforcement learning (RL) enables adversaries to more effectively break safety alignment and facilitate advanced harmful task assistance, under matched computational budgets. To counter this emerging threat, we propose TokenBuncher, the first effective defense specifically targeting RL-based harmful fine-tuning. TokenBuncher suppresses the foundation on which RL relies: model response uncertainty. By constraining uncertainty, RL-based fine-tuning can no longer exploit distinct reward signals to drive the model toward harmful behaviors. We realize this defense through entropy-as-reward RL and a Token Noiser mechanism designed to prevent the escalation of expert-domain harmful capabilities. Extensive experiments across multiple models and RL algorithms show that TokenBuncher robustly mitigates harmful RL fine-tuning while preserving benign task utility and finetunability. Our results highlight that RL-based harmful fine-tuning poses a greater systemic risk than SFT, and that TokenBuncher provides an effective and general defense.
FreeFlux: Understanding and Exploiting Layer-Specific Roles in RoPE-Based MMDiT for Versatile Image Editing
Mar 20, 2025
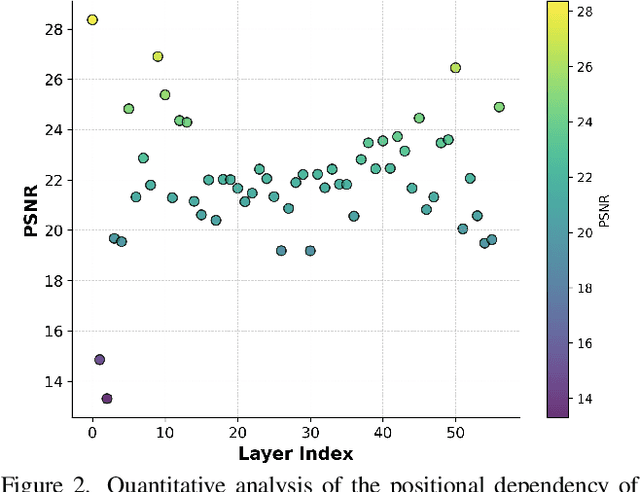
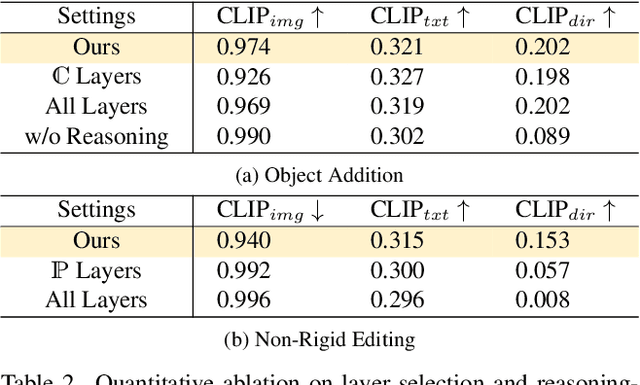

The integration of Rotary Position Embedding (RoPE) in Multimodal Diffusion Transformer (MMDiT) has significantly enhanced text-to-image generation quality. However, the fundamental reliance of self-attention layers on positional embedding versus query-key similarity during generation remains an intriguing question. We present the first mechanistic analysis of RoPE-based MMDiT models (e.g., FLUX), introducing an automated probing strategy that disentangles positional information versus content dependencies by strategically manipulating RoPE during generation. Our analysis reveals distinct dependency patterns that do not straightforwardly correlate with depth, offering new insights into the layer-specific roles in RoPE-based MMDiT. Based on these findings, we propose a training-free, task-specific image editing framework that categorizes editing tasks into three types: position-dependent editing (e.g., object addition), content similarity-dependent editing (e.g., non-rigid editing), and region-preserved editing (e.g., background replacement). For each type, we design tailored key-value injection strategies based on the characteristics of the editing task. Extensive qualitative and quantitative evaluations demonstrate that our method outperforms state-of-the-art approaches, particularly in preserving original semantic content and achieving seamless modifications.
Bokeh Diffusion: Defocus Blur Control in Text-to-Image Diffusion Models
Mar 13, 2025Recent advances in large-scale text-to-image models have revolutionized creative fields by generating visually captivating outputs from textual prompts; however, while traditional photography offers precise control over camera settings to shape visual aesthetics -- such as depth-of-field -- current diffusion models typically rely on prompt engineering to mimic such effects. This approach often results in crude approximations and inadvertently altering the scene content. In this work, we propose Bokeh Diffusion, a scene-consistent bokeh control framework that explicitly conditions a diffusion model on a physical defocus blur parameter. By grounding depth-of-field adjustments, our method preserves the underlying scene structure as the level of blur is varied. To overcome the scarcity of paired real-world images captured under different camera settings, we introduce a hybrid training pipeline that aligns in-the-wild images with synthetic blur augmentations. Extensive experiments demonstrate that our approach not only achieves flexible, lens-like blur control but also supports applications such as real image editing via inversion.
Enhancing MMDiT-Based Text-to-Image Models for Similar Subject Generation
Nov 27, 2024



Representing the cutting-edge technique of text-to-image models, the latest Multimodal Diffusion Transformer (MMDiT) largely mitigates many generation issues existing in previous models. However, we discover that it still suffers from subject neglect or mixing when the input text prompt contains multiple subjects of similar semantics or appearance. We identify three possible ambiguities within the MMDiT architecture that cause this problem: Inter-block Ambiguity, Text Encoder Ambiguity, and Semantic Ambiguity. To address these issues, we propose to repair the ambiguous latent on-the-fly by test-time optimization at early denoising steps. In detail, we design three loss functions: Block Alignment Loss, Text Encoder Alignment Loss, and Overlap Loss, each tailored to mitigate these ambiguities. Despite significant improvements, we observe that semantic ambiguity persists when generating multiple similar subjects, as the guidance provided by overlap loss is not explicit enough. Therefore, we further propose Overlap Online Detection and Back-to-Start Sampling Strategy to alleviate the problem. Experimental results on a newly constructed challenging dataset of similar subjects validate the effectiveness of our approach, showing superior generation quality and much higher success rates over existing methods. Our code will be available at https://github.com/wtybest/EnMMDiT.
Clustering Alzheimer's Disease Subtypes via Similarity Learning and Graph Diffusion
Oct 04, 2024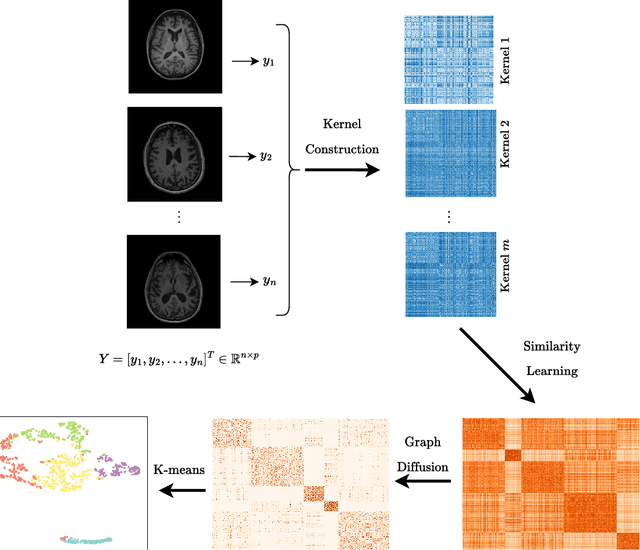
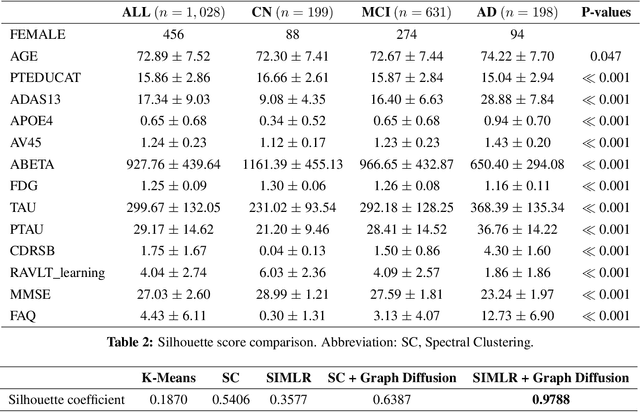
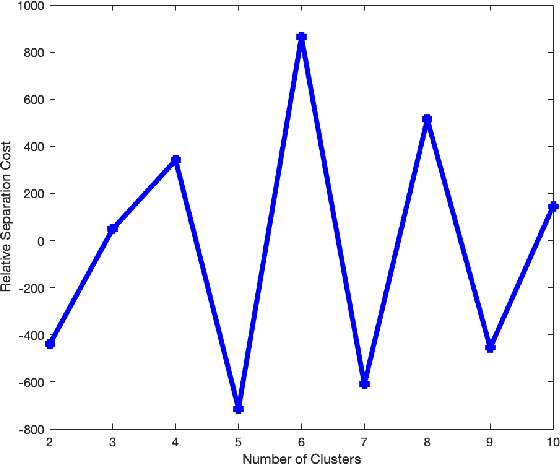
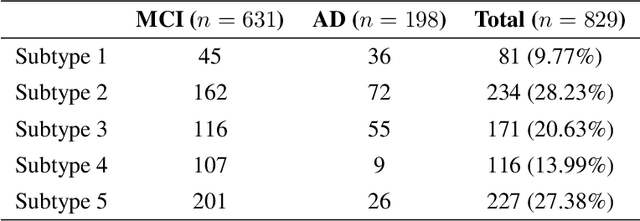
Alzheimer's disease (AD) is a complex neurodegenerative disorder that affects millions of people worldwide. Due to the heterogeneous nature of AD, its diagnosis and treatment pose critical challenges. Consequently, there is a growing research interest in identifying homogeneous AD subtypes that can assist in addressing these challenges in recent years. In this study, we aim to identify subtypes of AD that represent distinctive clinical features and underlying pathology by utilizing unsupervised clustering with graph diffusion and similarity learning. We adopted SIMLR, a multi-kernel similarity learning framework, and graph diffusion to perform clustering on a group of 829 patients with AD and mild cognitive impairment (MCI, a prodromal stage of AD) based on their cortical thickness measurements extracted from magnetic resonance imaging (MRI) scans. Although the clustering approach we utilized has not been explored for the task of AD subtyping before, it demonstrated significantly better performance than several commonly used clustering methods. Specifically, we showed the power of graph diffusion in reducing the effects of noise in the subtype detection. Our results revealed five subtypes that differed remarkably in their biomarkers, cognitive status, and some other clinical features. To evaluate the resultant subtypes further, a genetic association study was carried out and successfully identified potential genetic underpinnings of different AD subtypes. Our source code is available at: https://github.com/PennShenLab/AD-SIMLR.