 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgeryVCR: Visual-Centric Reasoning via Efficient Forensic Tools in MLLMs for Image Forgery Detection and Localization
Feb 15, 2026Existing Multimodal Large Language Models (MLLMs) for image forgery detection and localization predominantly operate under a text-centric Chain-of-Thought (CoT) paradigm. However, forcing these models to textually characterize imperceptible low-level tampering traces inevitably leads to hallucinations, as linguistic modalities are insufficient to capture such fine-grained pixel-level inconsistencies. To overcome this, we propose ForgeryVCR, a framework that incorporates a forensic toolbox to materialize imperceptible traces into explicit visual intermediates via Visual-Centric Reasoning. To enable efficient tool utilization, we introduce a Strategic Tool Learning post-training paradigm, encompassing gain-driven trajectory construction for Supervised Fine-Tuning (SFT) and subsequent Reinforcement Learning (RL) optimization guided by a tool utility reward. This paradigm empowers the MLLM to act as a proactive decision-maker, learning to spontaneously invoke multi-view reasoning paths including local zoom-in for fine-grained inspection and the analysis of invisible inconsistencies in compression history, noise residuals, and frequency domains. Extensive experiments reveal that ForgeryVCR achieves state-of-the-art (SOTA) performance in both detection and localization tasks, demonstrating superior generalization and robustness with minimal tool redundancy. The project page is available at https://youqiwong.github.io/projects/ForgeryVCR/.
PSGS: Text-driven Panorama Sliding Scene Generation via Gaussian Splatting
Jan 31, 2026Generating realistic 3D scenes from text is crucial for immersive applications like VR, AR, and gaming. While text-driven approaches promise efficiency, existing methods suffer from limited 3D-text data and inconsistent multi-view stitching, resulting in overly simplistic scenes. To address this, we propose PSGS, a two-stage framework for high-fidelity panoramic scene generation. First, a novel two-layer optimization architecture generates semantically coherent panoramas: a layout reasoning layer parses text into structured spatial relationships, while a self-optimization layer refines visual details via iterative MLLM feedback. Second, our panorama sliding mechanism initializes globally consistent 3D Gaussian Splatting point clouds by strategically sampling overlapping perspectives. By incorporating depth and semantic coherence losses during training, we greatly improve the quality and detail fidelity of rendered scenes. Our experiments demonstrate that PSGS outperforms existing methods in panorama generation and produces more appealing 3D scenes, offering a robust solution for scalable immersive content creation.
TripleFDS: Triple Feature Disentanglement and Synthesis for Scene Text Editing
Nov 17, 2025Scene Text Editing (STE) aims to naturally modify text in images while preserving visual consistency, the decisive factors of which can be divided into three parts, i.e., text style, text content, and background. Previous methods have struggled with incomplete disentanglement of editable attributes, typically addressing only one aspect - such as editing text content - thus limiting controllability and visual consistency. To overcome these limitations, we propose TripleFDS, a novel framework for STE with disentangled modular attributes, and an accompanying dataset called SCB Synthesis. SCB Synthesis provides robust training data for triple feature disentanglement by utilizing the "SCB Group", a novel construct that combines three attributes per image to generate diverse, disentangled training groups. Leveraging this construct as a basic training unit, TripleFDS first disentangles triple features, ensuring semantic accuracy through inter-group contrastive regularization and reducing redundancy through intra-sample multi-feature orthogonality. In the synthesis phase, TripleFDS performs feature remapping to prevent "shortcut" phenomena during reconstruction and mitigate potential feature leakage. Trained on 125,000 SCB Groups, TripleFDS achieves state-of-the-art image fidelity (SSIM of 44.54) and text accuracy (ACC of 93.58%) on the mainstream STE benchmarks. Besides superior performance, the more flexible editing of TripleFDS supports new operations such as style replacement and background transfer. Code: https://github.com/yusenbao01/TripleFDS
Causal Reasoning Elicits Controllable 3D Scene Generation
Sep 18, 2025



Existing 3D scene generation methods often struggle to model the complex logical dependencies and physical constraints between objects, limiting their ability to adapt to dynamic and realistic environments. We propose CausalStruct, a novel framework that embeds causal reasoning into 3D scene generation. Utilizing large language models (LLMs), We construct causal graphs where nodes represent objects and attributes, while edges encode causal dependencies and physical constraints. CausalStruct iteratively refines the scene layout by enforcing causal order to determine the placement order of objects and applies causal intervention to adjust the spatial configuration according to physics-driven constraints, ensuring consistency with textual descriptions and real-world dynamics. The refined scene causal graph informs subsequent optimization steps, employing a Proportional-Integral-Derivative(PID) controller to iteratively tune object scales and positions. Our method uses text or images to guide object placement and layout in 3D scenes, with 3D Gaussian Splatting and Score Distillation Sampling improving shape accuracy and rendering stability. Extensive experiments show that CausalStruct generates 3D scenes with enhanced logical coherence, realistic spatial interactions, and robust adaptability.
Mind2Matter: Creating 3D Models from EEG Signals
Apr 16, 2025The reconstruction of 3D objects from brain signals has gained significant attention in brain-computer interface (BCI) research. Current research predominantly utilizes functional magnetic resonance imaging (fMRI) for 3D reconstruction tasks due to its excellent spatial resolution. Nevertheless, the clinical utility of fMRI is limited by its prohibitive costs and inability to support real-time operations. In comparison, electroencephalography (EEG) presents distinct advantages as an affordable, non-invasive, and mobile solution for real-time brain-computer interaction systems. While recent advances in deep learning have enabled remarkable progress in image generation from neural data, decoding EEG signals into structured 3D representations remains largely unexplored. In this paper, we propose a novel framework that translates EEG recordings into 3D object reconstructions by leveraging neural decoding techniques and generative models. Our approach involves training an EEG encoder to extract spatiotemporal visual features, fine-tuning a large language model to interpret these features into descriptive multimodal outputs, and leveraging generative 3D Gaussians with layout-guided control to synthesize the final 3D structures. Experiments demonstrate that our model captures salient geometric and semantic features, paving the way for applications in brain-computer interfaces (BCIs), virtual reality, and neuroprosthetics.Our code is available in https://github.com/sddwwww/Mind2Matter.
Exploring Unbiased Deepfake Detection via Token-Level Shuffling and Mixing
Jan 08, 2025



The generalization problem is broadly recognized as a critical challenge in detecting deepfakes. Most previous work believes that the generalization gap is caused by the differences among various forgery methods. However, our investigation reveals that the generalization issue can still occur when forgery-irrelevant factors shift. In this work, we identify two biases that detectors may also be prone to overfitting: position bias and content bias, as depicted in Fig. 1. For the position bias, we observe that detectors are prone to lazily depending on the specific positions within an image (e.g., central regions even no forgery). As for content bias, we argue that detectors may potentially and mistakenly utilize forgery-unrelated information for detection (e.g., background, and hair). To intervene these biases, we propose two branches for shuffling and mixing with tokens in the latent space of transformers. For the shuffling branch, we rearrange the tokens and corresponding position embedding for each image while maintaining the local correlation. For the mixing branch, we randomly select and mix the tokens in the latent space between two images with the same label within the mini-batch to recombine the content information. During the learning process, we align the outputs of detectors from different branches in both feature space and logit space. Contrastive losses for features and divergence losses for logits are applied to obtain unbiased feature representation and classifiers. We demonstrate and verify the effectiveness of our method through extensive experiments on widely used evaluation datasets.
Graph Canvas for Controllable 3D Scene Generation
Nov 27, 2024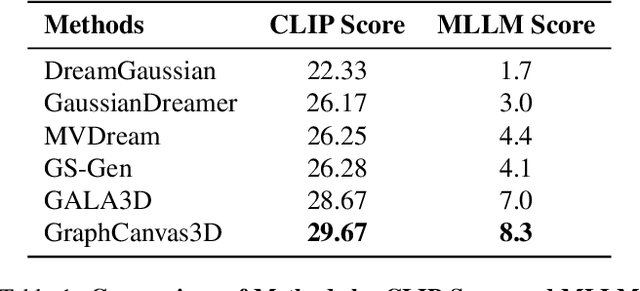
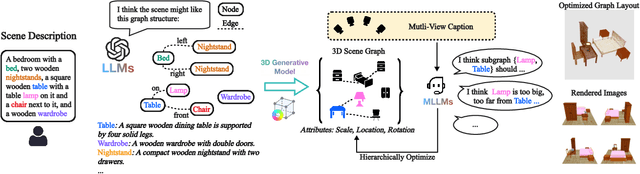
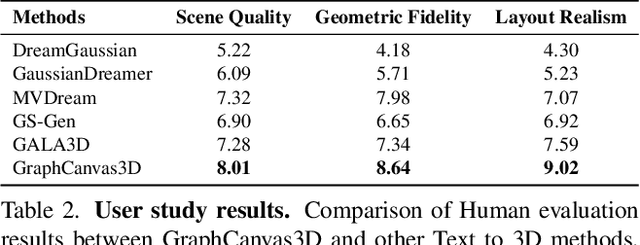
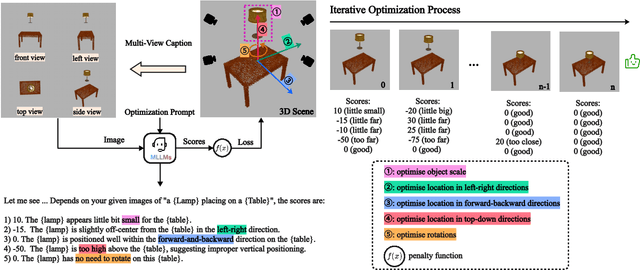
Spatial intelligence is foundational to AI systems that interact with the physical world, particularly in 3D scene generation and spatial comprehension. Current methodologies for 3D scene generation often rely heavily on predefined datasets, and struggle to adapt dynamically to changing spatial relationships. In this paper, we introduce \textbf{GraphCanvas3D}, a programmable, extensible, and adaptable framework for controllable 3D scene generation. Leveraging in-context learning, GraphCanvas3D enables dynamic adaptability without the need for retraining, supporting flexible and customizable scene creation. Our framework employs hierarchical, graph-driven scene descriptions, representing spatial elements as graph nodes and establishing coherent relationships among objects in 3D environments. Unlike conventional approaches, which are constrained in adaptability and often require predefined input masks or retraining for modifications, GraphCanvas3D allows for seamless object manipulation and scene adjustments on the fly. Additionally, GraphCanvas3D supports 4D scene generation, incorporating temporal dynamics to model changes over time. Experimental results and user studies demonstrate that GraphCanvas3D enhances usability, flexibility, and adaptability for scene generation. Our code and models are available on the project website: https://github.com/ILGLJ/Graph-Canvas.
Effort: Efficient Orthogonal Modeling for Generalizable AI-Generated Image Detection
Nov 23, 2024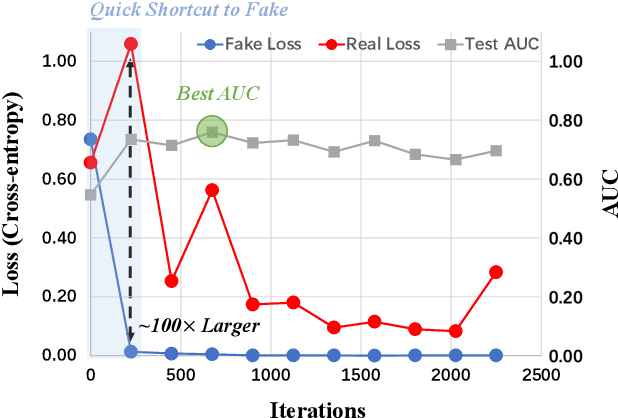
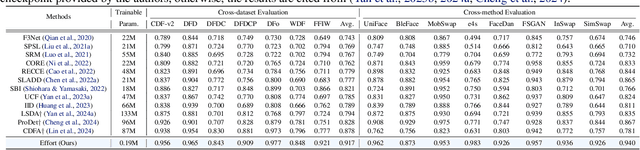
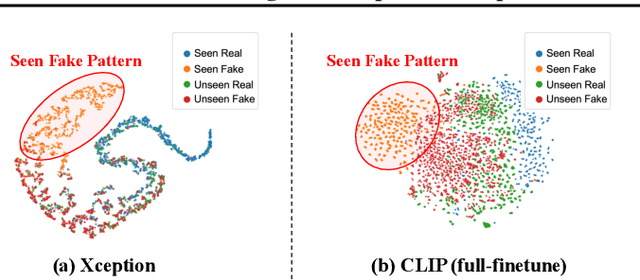
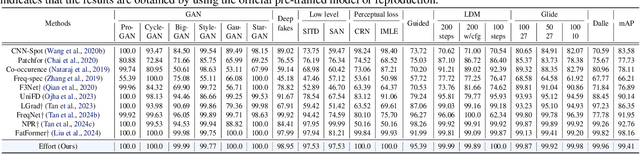
Existing AI-generated image (AIGI) detection methods often suffer from limited generalization performance. In this paper, we identify a crucial yet previously overlooked asymmetry phenomenon in AIGI detection: during training, models tend to quickly overfit to specific fake patterns in the training set, while other information is not adequately captured, leading to poor generalization when faced with new fake methods. A key insight is to incorporate the rich semantic knowledge embedded within large-scale vision foundation models (VFMs) to expand the previous discriminative space (based on forgery patterns only), such that the discrimination is decided by both forgery and semantic cues, thereby reducing the overfitting to specific forgery patterns. A straightforward solution is to fully fine-tune VFMs, but it risks distorting the well-learned semantic knowledge, pushing the model back toward overfitting. To this end, we design a novel approach called Effort: Efficient orthogonal modeling for generalizable AIGI detection. Specifically, we employ Singular Value Decomposition (SVD) to construct the orthogonal semantic and forgery subspaces. By freezing the principal components and adapting the residual components ($\sim$0.19M parameters), we preserve the original semantic subspace and use its orthogonal subspace for learning forgeries. Extensive experiments on AIGI detection benchmarks demonstrate the superior effectiveness of our approach.
A Quality-Centric Framework for Generic Deepfake Detection
Nov 08, 2024



This paper addresses the generalization issue in deepfake detection by harnessing forgery quality in training data. Generally, the forgery quality of different deepfakes varies: some have easily recognizable forgery clues, while others are highly realistic. Existing works often train detectors on a mix of deepfakes with varying forgery qualities, potentially leading detectors to short-cut the easy-to-spot artifacts from low-quality forgery samples, thereby hurting generalization performance. To tackle this issue, we propose a novel quality-centric framework for generic deepfake detection, which is composed of a Quality Evaluator, a low-quality data enhancement module, and a learning pacing strategy that explicitly incorporates forgery quality into the training process. The framework is inspired by curriculum learning, which is designed to gradually enable the detector to learn more challenging deepfake samples, starting with easier samples and progressing to more realistic ones. We employ both static and dynamic assessments to assess the forgery quality, combining their scores to produce a final rating for each training sample. The rating score guides the selection of deepfake samples for training, with higher-rated samples having a higher probability of being chosen. Furthermore, we propose a novel frequency data augmentation method specifically designed for low-quality forgery samples, which helps to reduce obvious forgery traces and improve their overall realism. Extensive experiments show that our method can be applied in a plug-and-play manner and significantly enhance the generalization performance.
DiffusionFake: Enhancing Generalization in Deepfake Detection via Guided Stable Diffusion
Oct 06, 2024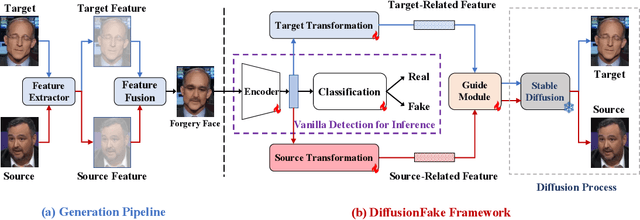
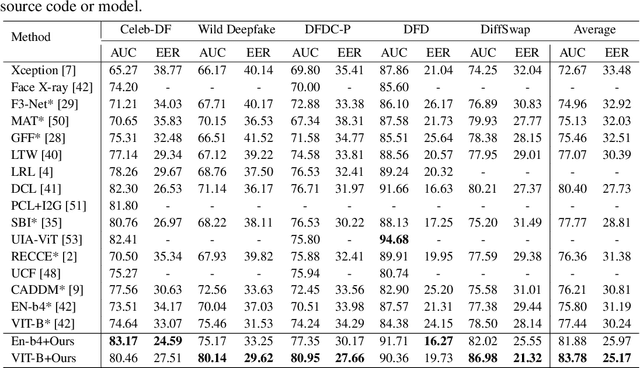
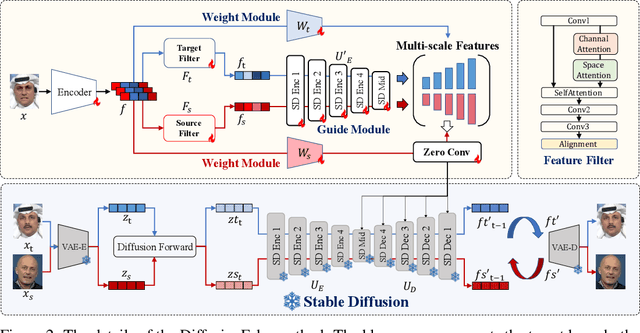
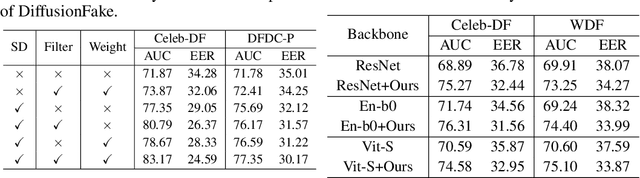
The rapid progress of Deepfake technology has made face swapping highly realistic, raising concerns about the malicious use of fabricated facial content. Existing methods often struggle to generalize to unseen domains due to the diverse nature of facial manipulations. In this paper, we revisit the generation process and identify a universal principle: Deepfake images inherently contain information from both source and target identities, while genuine faces maintain a consistent identity. Building upon this insight, we introduce DiffusionFake, a novel plug-and-play framework that reverses the generative process of face forgeries to enhance the generalization of detection models. DiffusionFake achieves this by injecting the features extracted by the detection model into a frozen pre-trained Stable Diffusion model, compelling it to reconstruct the corresponding target and source images. This guided reconstruction process constrains the detection network to capture the source and target related features to facilitate the reconstruction, thereby learning rich and disentangled representations that are more resilient to unseen forgeries. Extensive experiments demonstrate that DiffusionFake significantly improves cross-domain generalization of various detector architectures without introducing additional parameters during inference. Our Codes are available in https://github.com/skJack/DiffusionFake.git.