 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Quality-Centric Framework for Generic Deepfake Detection
Nov 08, 2024



This paper addresses the generalization issue in deepfake detection by harnessing forgery quality in training data. Generally, the forgery quality of different deepfakes varies: some have easily recognizable forgery clues, while others are highly realistic. Existing works often train detectors on a mix of deepfakes with varying forgery qualities, potentially leading detectors to short-cut the easy-to-spot artifacts from low-quality forgery samples, thereby hurting generalization performance. To tackle this issue, we propose a novel quality-centric framework for generic deepfake detection, which is composed of a Quality Evaluator, a low-quality data enhancement module, and a learning pacing strategy that explicitly incorporates forgery quality into the training process. The framework is inspired by curriculum learning, which is designed to gradually enable the detector to learn more challenging deepfake samples, starting with easier samples and progressing to more realistic ones. We employ both static and dynamic assessments to assess the forgery quality, combining their scores to produce a final rating for each training sample. The rating score guides the selection of deepfake samples for training, with higher-rated samples having a higher probability of being chosen. Furthermore, we propose a novel frequency data augmentation method specifically designed for low-quality forgery samples, which helps to reduce obvious forgery traces and improve their overall realism. Extensive experiments show that our method can be applied in a plug-and-play manner and significantly enhance the generalization performance.
Generalizing Deepfake Video Detection with Plug-and-Play: Video-Level Blending and Spatiotemporal Adapter Tuning
Aug 30, 2024
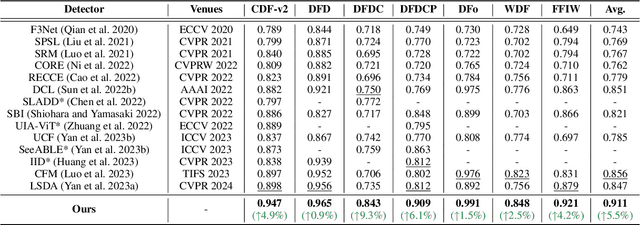
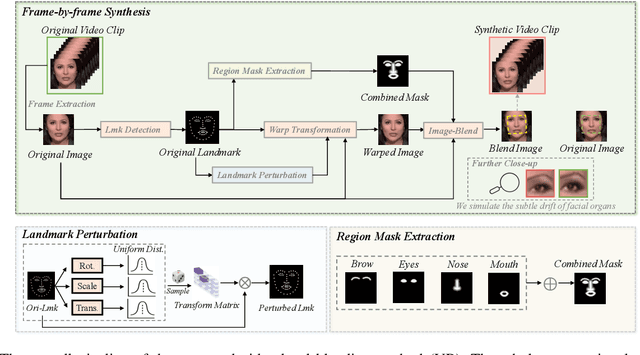

Three key challenges hinder the development of current deepfake video detection: (1) Temporal features can be complex and diverse: how can we identify general temporal artifacts to enhance model generalization? (2) Spatiotemporal models often lean heavily on one type of artifact and ignore the other: how can we ensure balanced learning from both? (3) Videos are naturally resource-intensive: how can we tackle efficiency without compromising accuracy? This paper attempts to tackle the three challenges jointly. First, inspired by the notable generality of using image-level blending data for image forgery detection, we investigate whether and how video-level blending can be effective in video. We then perform a thorough analysis and identify a previously underexplored temporal forgery artifact: Facial Feature Drift (FFD), which commonly exists across different forgeries. To reproduce FFD, we then propose a novel Video-level Blending data (VB), where VB is implemented by blending the original image and its warped version frame-by-frame, serving as a hard negative sample to mine more general artifacts. Second, we carefully design a lightweight Spatiotemporal Adapter (StA) to equip a pretrained image model (both ViTs and CNNs) with the ability to capture both spatial and temporal features jointly and efficiently. StA is designed with two-stream 3D-Conv with varying kernel sizes, allowing it to process spatial and temporal features separately. Extensive experiments validate the effectiveness of the proposed methods; and show our approach can generalize well to previously unseen forgery videos, even the just-released (in 2024) SoTAs. We release our code and pretrained weights at \url{https://github.com/YZY-stack/StA4Deepfake}.
DF40: Toward Next-Generation Deepfake Detection
Jun 19, 2024


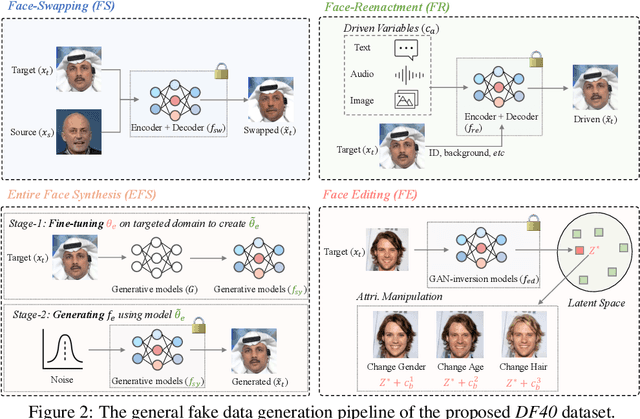
We propose a new comprehensive benchmark to revolutionize the current deepfake detection field to the next generation. Predominantly, existing works identify top-notch detection algorithms and models by adhering to the common practice: training detectors on one specific dataset (e.g., FF++) and testing them on other prevalent deepfake datasets. This protocol is often regarded as a "golden compass" for navigating SoTA detectors. But can these stand-out "winners" be truly applied to tackle the myriad of realistic and diverse deepfakes lurking in the real world? If not, what underlying factors contribute to this gap? In this work, we found the dataset (both train and test) can be the "primary culprit" due to: (1) forgery diversity: Deepfake techniques are commonly referred to as both face forgery (face-swapping and face-reenactment) and entire image synthesis (AIGC). Most existing datasets only contain partial types, with limited forgery methods implemented; (2) forgery realism: The dominant training dataset, FF++, contains old forgery techniques from the past five years. "Honing skills" on these forgeries makes it difficult to guarantee effective detection of nowadays' SoTA deepfakes; (3) evaluation protocol: Most detection works perform evaluations on one type, e.g., train and test on face-swapping only, which hinders the development of universal deepfake detectors. To address this dilemma, we construct a highly diverse and large-scale deepfake dataset called DF40, which comprises 40 distinct deepfake techniques. We then conduct comprehensive evaluations using 4 standard evaluation protocols and 7 representative detectors, resulting in over 2,000 evaluations. Through these evaluations, we analyze from various perspectives, leading to 12 new insightful findings contributing to the field. We also open up 5 valuable yet previously underexplored research questions to inspire future works.