 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEMG: Collaborative-Enhanced Multimodal Generative Recommendation
Dec 25, 2025Generative recommendation models often struggle with two key challenges: (1) the superficial integration of collaborative signals, and (2) the decoupled fusion of multimodal features. These limitations hinder the creation of a truly holistic item representation. To overcome this, we propose CEMG, a novel Collaborative-Enhaned Multimodal Generative Recommendation framework. Our approach features a Multimodal Fusion Layer that dynamically integrates visual and textual features under the guidance of collaborative signals. Subsequently, a Unified Modality Tokenization stage employs a Residual Quantization VAE (RQ-VAE) to convert this fused representation into discrete semantic codes. Finally, in the End-to-End Generative Recommendation stage, a large language model is fine-tuned to autoregressively generate these item codes. Extensive experiments demonstrate that CEMG significantly outperforms state-of-the-art baselines.
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
May 26, 2025Securing personal identity against deepfake attacks is increasingly critical in the digital age, especially for celebrities and political figures whose faces are easily accessible and frequently targeted. Most existing deepfake detection methods focus on general-purpose scenarios and often ignore the valuable prior knowledge of known facial identities, e.g., "VIP individuals" whose authentic facial data are already available. In this paper, we propose \textbf{VIPGuard}, a unified multimodal framework designed to capture fine-grained and comprehensive facial representations of a given identity, compare them against potentially fake or similar-looking faces, and reason over these comparisons to make accurate and explainable predictions. Specifically, our framework consists of three main stages. First, fine-tune a multimodal large language model (MLLM) to learn detailed and structural facial attributes. Second, we perform identity-level discriminative learning to enable the model to distinguish subtle differences between highly similar faces, including real and fake variations. Finally, we introduce user-specific customization, where we model the unique characteristics of the target face identity and perform semantic reasoning via MLLM to enable personalized and explainable deepfake detection. Our framework shows clear advantages over previous detection works, where traditional detectors mainly rely on low-level visual cues and provide no human-understandable explanations, while other MLLM-based models often lack a detailed understanding of specific face identities. To facilitate the evaluation of our method, we built a comprehensive identity-aware benchmark called \textbf{VIPBench} for personalized deepfake detection, involving the latest 7 face-swapping and 7 entire face synthesis techniques for generation.
Reinforced Multi-teacher Knowledge Distillation for Efficient General Image Forgery Detection and Localization
Apr 07, 2025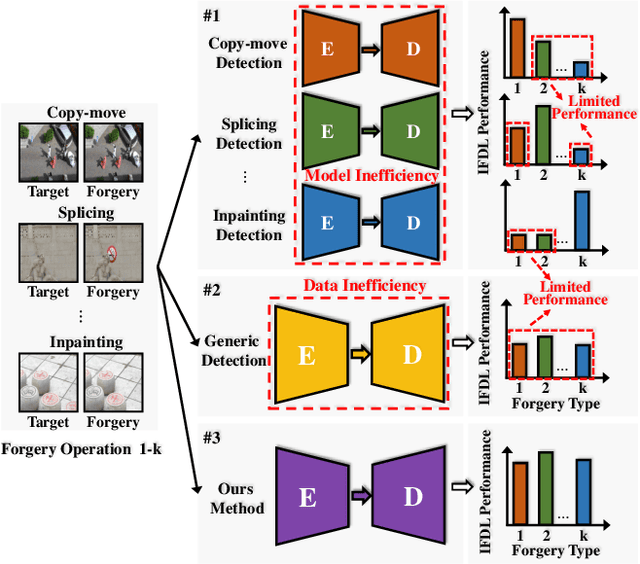
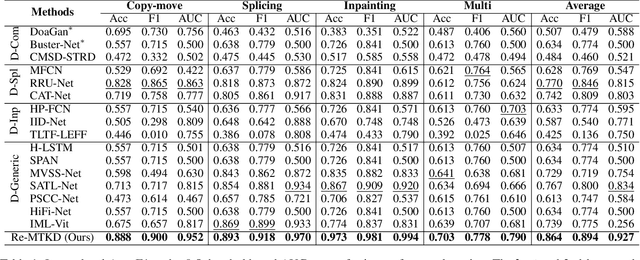
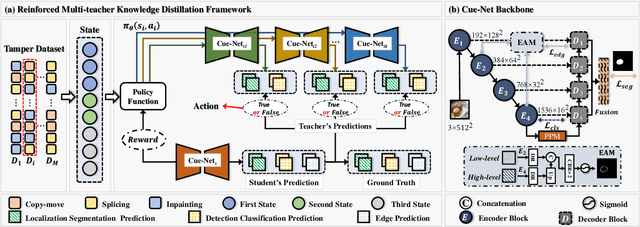
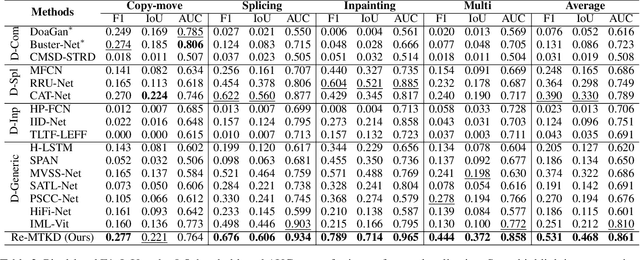
Image forgery detection and localization (IFDL) is of vital importance as forged images can spread misinformation that poses potential threats to our daily lives. However, previous methods still struggled to effectively handle forged images processed with diverse forgery operations in real-world scenarios. In this paper, we propose a novel Reinforced Multi-teacher Knowledge Distillation (Re-MTKD) framework for the IFDL task, structured around an encoder-decoder \textbf{C}onvNeXt-\textbf{U}perNet along with \textbf{E}dge-Aware Module, named Cue-Net. First, three Cue-Net models are separately trained for the three main types of image forgeries, i.e., copy-move, splicing, and inpainting, which then serve as the multi-teacher models to train the target student model with Cue-Net through self-knowledge distillation. A Reinforced Dynamic Teacher Selection (Re-DTS) strategy is developed to dynamically assign weights to the involved teacher models, which facilitates specific knowledge transfer and enables the student model to effectively learn both the common and specific natures of diverse tampering traces. Extensive experiments demonstrate that, compared with other state-of-the-art methods, the proposed method achieves superior performance on several recently emerged datasets comprised of various kinds of image forgeries.
A Quality-Centric Framework for Generic Deepfake Detection
Nov 08, 2024



This paper addresses the generalization issue in deepfake detection by harnessing forgery quality in training data. Generally, the forgery quality of different deepfakes varies: some have easily recognizable forgery clues, while others are highly realistic. Existing works often train detectors on a mix of deepfakes with varying forgery qualities, potentially leading detectors to short-cut the easy-to-spot artifacts from low-quality forgery samples, thereby hurting generalization performance. To tackle this issue, we propose a novel quality-centric framework for generic deepfake detection, which is composed of a Quality Evaluator, a low-quality data enhancement module, and a learning pacing strategy that explicitly incorporates forgery quality into the training process. The framework is inspired by curriculum learning, which is designed to gradually enable the detector to learn more challenging deepfake samples, starting with easier samples and progressing to more realistic ones. We employ both static and dynamic assessments to assess the forgery quality, combining their scores to produce a final rating for each training sample. The rating score guides the selection of deepfake samples for training, with higher-rated samples having a higher probability of being chosen. Furthermore, we propose a novel frequency data augmentation method specifically designed for low-quality forgery samples, which helps to reduce obvious forgery traces and improve their overall realism. Extensive experiments show that our method can be applied in a plug-and-play manner and significantly enhance the generalization performance.
Towards General Deepfake Detection with Dynamic Curriculum
Oct 15, 2024Most previous deepfake detection methods bent their efforts to discriminate artifacts by end-to-end training. However, the learned networks often fail to mine the general face forgery information efficiently due to ignoring the data hardness. In this work, we propose to introduce the sample hardness into the training of deepfake detectors via the curriculum learning paradigm. Specifically, we present a novel simple yet effective strategy, named Dynamic Facial Forensic Curriculum (DFFC), which makes the model gradually focus on hard samples during the training. Firstly, we propose Dynamic Forensic Hardness (DFH) which integrates the facial quality score and instantaneous instance loss to dynamically measure sample hardness during the training. Furthermore, we present a pacing function to control the data subsets from easy to hard throughout the training process based on DFH. Comprehensive experiments show that DFFC can improve both within- and cross-dataset performance of various kinds of end-to-end deepfake detectors through a plug-and-play approach. It indicates that DFFC can help deepfake detectors learn general forgery discriminative features by effectively exploiting the information from hard samples.
Fake It till You Make It: Curricular Dynamic Forgery Augmentations towards General Deepfake Detection
Sep 22, 2024Previous studies in deepfake detection have shown promising results when testing face forgeries from the same dataset as the training. However, the problem remains challenging when one tries to generalize the detector to forgeries from unseen datasets and created by unseen methods. In this work, we present a novel general deepfake detection method, called \textbf{C}urricular \textbf{D}ynamic \textbf{F}orgery \textbf{A}ugmentation (CDFA), which jointly trains a deepfake detector with a forgery augmentation policy network. Unlike the previous works, we propose to progressively apply forgery augmentations following a monotonic curriculum during the training. We further propose a dynamic forgery searching strategy to select one suitable forgery augmentation operation for each image varying between training stages, producing a forgery augmentation policy optimized for better generalization. In addition, we propose a novel forgery augmentation named self-shifted blending image to simply imitate the temporal inconsistency of deepfake generation. Comprehensive experiments show that CDFA can significantly improve both cross-datasets and cross-manipulations performances of various naive deepfake detectors in a plug-and-play way, and make them attain superior performances over the existing methods in several benchmark datasets.
Standing on the Shoulders of Giants: Reprogramming Visual-Language Model for General Deepfake Detection
Sep 04, 2024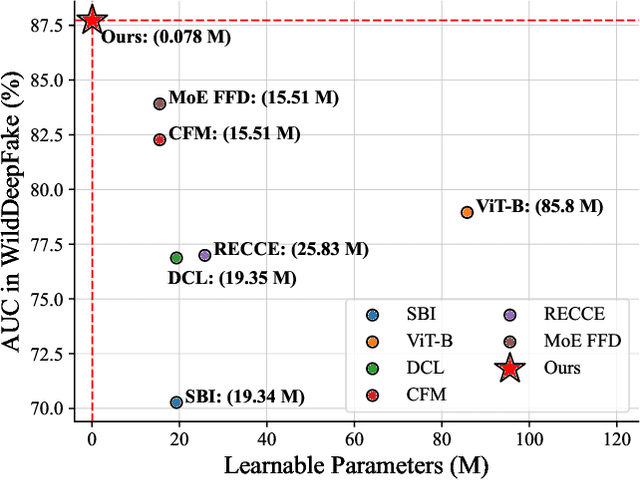

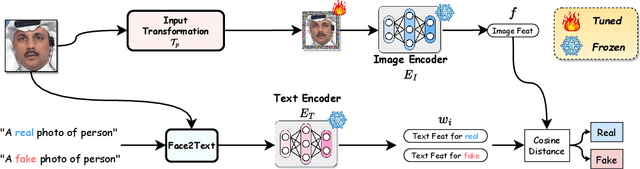

The proliferation of deepfake faces poses huge potential negative impacts on our daily lives. Despite substantial advancements in deepfake detection over these years, the generalizability of existing methods against forgeries from unseen datasets or created by emerging generative models remains constrained. In this paper, inspired by the zero-shot advantages of Vision-Language Models (VLMs), we propose a novel approach that repurposes a well-trained VLM for general deepfake detection. Motivated by the model reprogramming paradigm that manipulates the model prediction via data perturbations, our method can reprogram a pretrained VLM model (e.g., CLIP) solely based on manipulating its input without tuning the inner parameters. Furthermore, we insert a pseudo-word guided by facial identity into the text prompt. Extensive experiments on several popular benchmarks demonstrate that (1) the cross-dataset and cross-manipulation performances of deepfake detection can be significantly and consistently improved (e.g., over 88% AUC in cross-dataset setting from FF++ to WildDeepfake) using a pre-trained CLIP model with our proposed reprogramming method; (2) our superior performances are at less cost of trainable parameters, making it a promising approach for real-world applications.