 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentFoX: LLM Agent-Guided Fusion with eXplainability for AI-Generated Image Detection
Mar 24, 2026The increasing realism of AI-Generated Images (AIGI) has created an urgent need for forensic tools capable of reliably distinguishing synthetic content from authentic imagery. Existing detectors are typically tailored to specific forgery artifacts--such as frequency-domain patterns or semantic inconsistencies--leading to specialized performance and, at times, conflicting judgments. To address these limitations, we present \textbf{AgentFoX}, a Large Language Model-driven framework that redefines AIGI detection as a dynamic, multi-phase analytical process. Our approach employs a quick-integration fusion mechanism guided by a curated knowledge base comprising calibrated Expert Profiles and contextual Clustering Profiles. During inference, the agent begins with high-level semantic assessment, then transitions to fine-grained, context-aware synthesis of signal-level expert evidence, resolving contradictions through structured reasoning. Instead of returning a coarse binary output, AgentFoX produces a detailed, human-readable forensic report that substantiates its verdict, enhancing interpretability and trustworthiness for real-world deployment. Beyond providing a novel detection solution, this work introduces a scalable agentic paradigm that facilitates intelligent integration of future and evolving forensic tools.
Toward Real-world Text Image Forgery Localization: Structured and Interpretable Data Synthesis
Nov 16, 2025Existing Text Image Forgery Localization (T-IFL) methods often suffer from poor generalization due to the limited scale of real-world datasets and the distribution gap caused by synthetic data that fails to capture the complexity of real-world tampering. To tackle this issue, we propose Fourier Series-based Tampering Synthesis (FSTS), a structured and interpretable framework for synthesizing tampered text images. FSTS first collects 16,750 real-world tampering instances from five representative tampering types, using a structured pipeline that records human-performed editing traces via multi-format logs (e.g., video, PSD, and editing logs). By analyzing these collected parameters and identifying recurring behavioral patterns at both individual and population levels, we formulate a hierarchical modeling framework. Specifically, each individual tampering parameter is represented as a compact combination of basis operation-parameter configurations, while the population-level distribution is constructed by aggregating these behaviors. Since this formulation draws inspiration from the Fourier series, it enables an interpretable approximation using basis functions and their learned weights. By sampling from this modeled distribution, FSTS synthesizes diverse and realistic training data that better reflect real-world forgery traces. Extensive experiments across four evaluation protocols demonstrate that models trained with FSTS data achieve significantly improved generalization on real-world datasets. Dataset is available at \href{https://github.com/ZeqinYu/FSTS}{Project Page}.
Reinforced Multi-teacher Knowledge Distillation for Efficient General Image Forgery Detection and Localization
Apr 07, 2025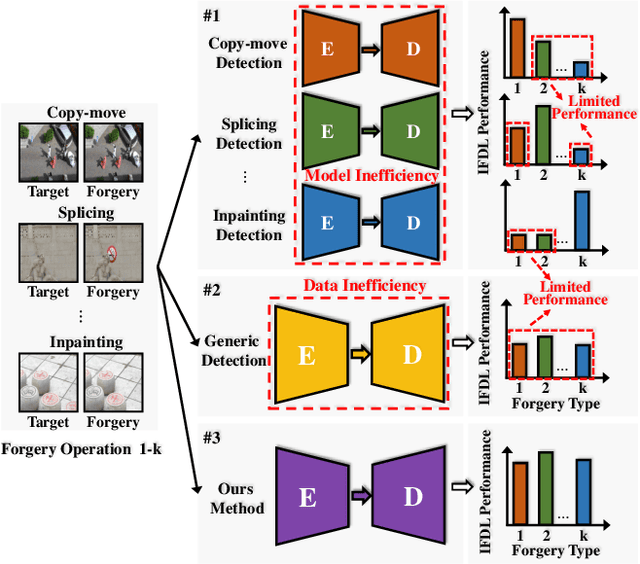
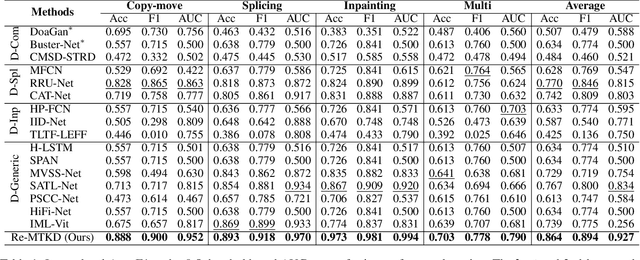
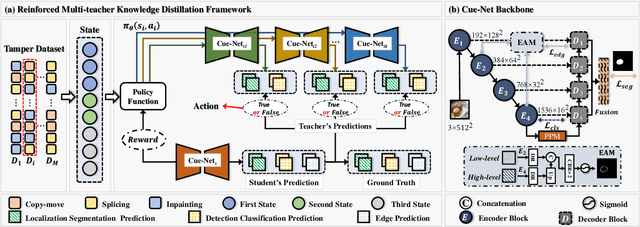
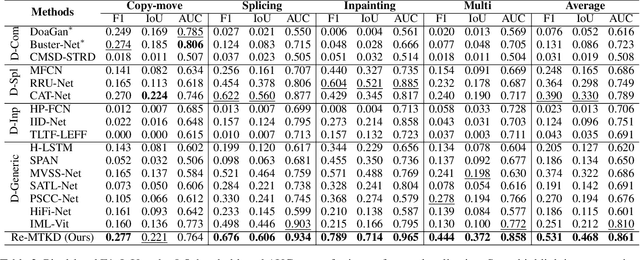
Image forgery detection and localization (IFDL) is of vital importance as forged images can spread misinformation that poses potential threats to our daily lives. However, previous methods still struggled to effectively handle forged images processed with diverse forgery operations in real-world scenarios. In this paper, we propose a novel Reinforced Multi-teacher Knowledge Distillation (Re-MTKD) framework for the IFDL task, structured around an encoder-decoder \textbf{C}onvNeXt-\textbf{U}perNet along with \textbf{E}dge-Aware Module, named Cue-Net. First, three Cue-Net models are separately trained for the three main types of image forgeries, i.e., copy-move, splicing, and inpainting, which then serve as the multi-teacher models to train the target student model with Cue-Net through self-knowledge distillation. A Reinforced Dynamic Teacher Selection (Re-DTS) strategy is developed to dynamically assign weights to the involved teacher models, which facilitates specific knowledge transfer and enables the student model to effectively learn both the common and specific natures of diverse tampering traces. Extensive experiments demonstrate that, compared with other state-of-the-art methods, the proposed method achieves superior performance on several recently emerged datasets comprised of various kinds of image forgeries.
DIP: Diffusion Learning of Inconsistency Pattern for General DeepFake Detection
Oct 31, 2024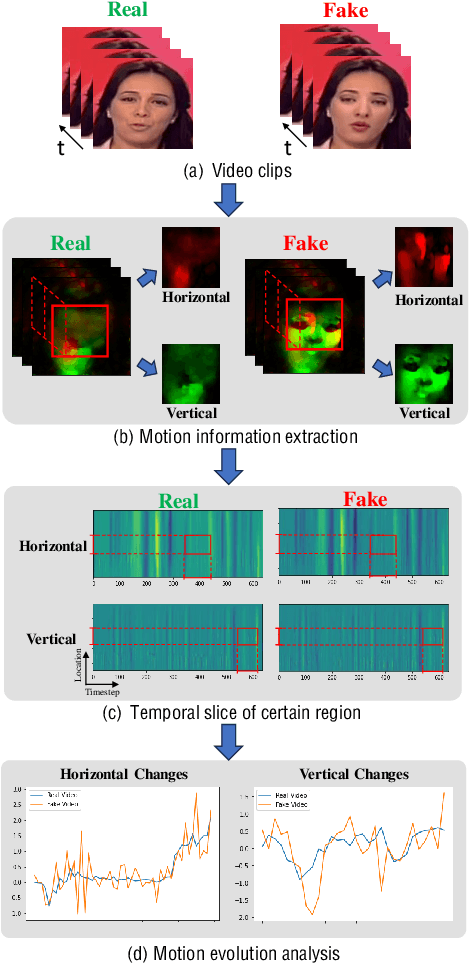

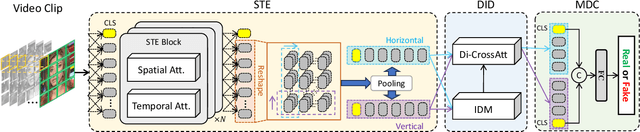
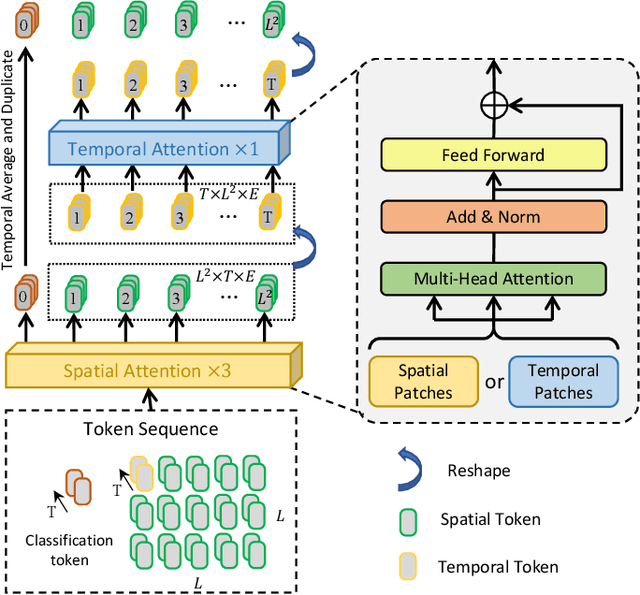
With the advancement of deepfake generation techniques, the importance of deepfake detection in protecting multimedia content integrity has become increasingly obvious. Recently, temporal inconsistency clues have been explored to improve the generalizability of deepfake video detection. According to our observation, the temporal artifacts of forged videos in terms of motion information usually exhibits quite distinct inconsistency patterns along horizontal and vertical directions, which could be leveraged to improve the generalizability of detectors. In this paper, a transformer-based framework for Diffusion Learning of Inconsistency Pattern (DIP) is proposed, which exploits directional inconsistencies for deepfake video detection. Specifically, DIP begins with a spatiotemporal encoder to represent spatiotemporal information. A directional inconsistency decoder is adopted accordingly, where direction-aware attention and inconsistency diffusion are incorporated to explore potential inconsistency patterns and jointly learn the inherent relationships. In addition, the SpatioTemporal Invariant Loss (STI Loss) is introduced to contrast spatiotemporally augmented sample pairs and prevent the model from overfitting nonessential forgery artifacts. Extensive experiments on several public datasets demonstrate that our method could effectively identify directional forgery clues and achieve state-of-the-art performance.
Fake It till You Make It: Curricular Dynamic Forgery Augmentations towards General Deepfake Detection
Sep 22, 2024Previous studies in deepfake detection have shown promising results when testing face forgeries from the same dataset as the training. However, the problem remains challenging when one tries to generalize the detector to forgeries from unseen datasets and created by unseen methods. In this work, we present a novel general deepfake detection method, called \textbf{C}urricular \textbf{D}ynamic \textbf{F}orgery \textbf{A}ugmentation (CDFA), which jointly trains a deepfake detector with a forgery augmentation policy network. Unlike the previous works, we propose to progressively apply forgery augmentations following a monotonic curriculum during the training. We further propose a dynamic forgery searching strategy to select one suitable forgery augmentation operation for each image varying between training stages, producing a forgery augmentation policy optimized for better generalization. In addition, we propose a novel forgery augmentation named self-shifted blending image to simply imitate the temporal inconsistency of deepfake generation. Comprehensive experiments show that CDFA can significantly improve both cross-datasets and cross-manipulations performances of various naive deepfake detectors in a plug-and-play way, and make them attain superior performances over the existing methods in several benchmark datasets.