 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSGym: A Holistic Framework for Evaluating and Training Data Science Agents
Jan 22, 2026Data science agents promise to accelerate discovery and insight-generation by turning data into executable analyses and findings. Yet existing data science benchmarks fall short due to fragmented evaluation interfaces that make cross-benchmark comparison difficult, narrow task coverage and a lack of rigorous data grounding. In particular, we show that a substantial portion of tasks in current benchmarks can be solved without using the actual data. To address these limitations, we introduce DSGym, a standardized framework for evaluating and training data science agents in self-contained execution environments. Unlike static benchmarks, DSGym provides a modular architecture that makes it easy to add tasks, agent scaffolds, and tools, positioning it as a live, extensible testbed. We curate DSGym-Tasks, a holistic task suite that standardizes and refines existing benchmarks via quality and shortcut solvability filtering. We further expand coverage with (1) DSBio: expert-derived bioinformatics tasks grounded in literature and (2) DSPredict: challenging prediction tasks spanning domains such as computer vision, molecular prediction, and single-cell perturbation. Beyond evaluation, DSGym enables agent training via execution-verified data synthesis pipeline. As a case study, we build a 2,000-example training set and trained a 4B model in DSGym that outperforms GPT-4o on standardized analysis benchmarks. Overall, DSGym enables rigorous end-to-end measurement of whether agents can plan, implement, and validate data analyses in realistic scientific context.
UQ: Assessing Language Models on Unsolved Questions
Aug 25, 2025Benchmarks shape progress in AI research. A useful benchmark should be both difficult and realistic: questions should challenge frontier models while also reflecting real-world usage. Yet, current paradigms face a difficulty-realism tension: exam-style benchmarks are often made artificially difficult with limited real-world value, while benchmarks based on real user interaction often skew toward easy, high-frequency problems. In this work, we explore a radically different paradigm: assessing models on unsolved questions. Rather than a static benchmark scored once, we curate unsolved questions and evaluate models asynchronously over time with validator-assisted screening and community verification. We introduce UQ, a testbed of 500 challenging, diverse questions sourced from Stack Exchange, spanning topics from CS theory and math to sci-fi and history, probing capabilities including reasoning, factuality, and browsing. UQ is difficult and realistic by construction: unsolved questions are often hard and naturally arise when humans seek answers, thus solving them yields direct real-world value. Our contributions are threefold: (1) UQ-Dataset and its collection pipeline combining rule-based filters, LLM judges, and human review to ensure question quality (e.g., well-defined and difficult); (2) UQ-Validators, compound validation strategies that leverage the generator-validator gap to provide evaluation signals and pre-screen candidate solutions for human review; and (3) UQ-Platform, an open platform where experts collectively verify questions and solutions. The top model passes UQ-validation on only 15% of questions, and preliminary human verification has already identified correct answers among those that passed. UQ charts a path for evaluating frontier models on real-world, open-ended challenges, where success pushes the frontier of human knowledge. We release UQ at https://uq.stanford.edu.
Weak-for-Strong: Training Weak Meta-Agent to Harness Strong Executors
Apr 07, 2025Efficiently leveraging of the capabilities of contemporary large language models (LLMs) is increasingly challenging, particularly when direct fine-tuning is expensive and often impractical. Existing training-free methods, including manually or automated designed workflows, typically demand substantial human effort or yield suboptimal results. This paper proposes Weak-for-Strong Harnessing (W4S), a novel framework that customizes smaller, cost-efficient language models to design and optimize workflows for harnessing stronger models. W4S formulates workflow design as a multi-turn markov decision process and introduces reinforcement learning for agentic workflow optimization (RLAO) to train a weak meta-agent. Through iterative interaction with the environment, the meta-agent learns to design increasingly effective workflows without manual intervention. Empirical results demonstrate the superiority of W4S that our 7B meta-agent, trained with just one GPU hour, outperforms the strongest baseline by 2.9% ~ 24.6% across eleven benchmarks, successfully elevating the performance of state-of-the-art models such as GPT-3.5-Turbo and GPT-4o. Notably, W4S exhibits strong generalization capabilities across both seen and unseen tasks, offering an efficient, high-performing alternative to directly fine-tuning strong models.
TAROT: Targeted Data Selection via Optimal Transport
Nov 30, 2024



We propose TAROT, a targeted data selection framework grounded in optimal transport theory. Previous targeted data selection methods primarily rely on influence-based greedy heuristics to enhance domain-specific performance. While effective on limited, unimodal data (i.e., data following a single pattern), these methods struggle as target data complexity increases. Specifically, in multimodal distributions, these heuristics fail to account for multiple inherent patterns, leading to suboptimal data selection. This work identifies two primary factors contributing to this limitation: (i) the disproportionate impact of dominant feature components in high-dimensional influence estimation, and (ii) the restrictive linear additive assumptions inherent in greedy selection strategies. To address these challenges, TAROT incorporates whitened feature distance to mitigate dominant feature bias, providing a more reliable measure of data influence. Building on this, TAROT uses whitened feature distance to quantify and minimize the optimal transport distance between the selected data and target domains. Notably, this minimization also facilitates the estimation of optimal selection ratios. We evaluate TAROT across multiple tasks, including semantic segmentation, motion prediction, and instruction tuning. Results consistently show that TAROT outperforms state-of-the-art methods, highlighting its versatility across various deep learning tasks. Code is available at https://github.com/vita-epfl/TAROT.
FactTest: Factuality Testing in Large Language Models with Statistical Guarantees
Nov 04, 2024



The propensity of Large Language Models (LLMs) to generate hallucinations and non-factual content undermines their reliability in high-stakes domains, where rigorous control over Type I errors (the conditional probability of incorrectly classifying hallucinations as truthful content) is essential. Despite its importance, formal verification of LLM factuality with such guarantees remains largely unexplored. In this paper, we introduce FactTest, a novel framework that statistically assesses whether an LLM can confidently provide correct answers to given questions with high-probability correctness guarantees. We formulate factuality testing as hypothesis testing problem to enforce an upper bound of Type I errors at user-specified significance levels. Notably, we prove that our framework also ensures strong Type II error control under mild conditions and can be extended to maintain its effectiveness when covariate shifts exist. %These analyses are amenable to the principled NP framework. Our approach is distribution-free and works for any number of human-annotated samples. It is model-agnostic and applies to any black-box or white-box LM. Extensive experiments on question-answering (QA) and multiple-choice benchmarks demonstrate that \approach effectively detects hallucinations and improves the model's ability to abstain from answering unknown questions, leading to an over 40% accuracy improvement.
DIP: Diffusion Learning of Inconsistency Pattern for General DeepFake Detection
Oct 31, 2024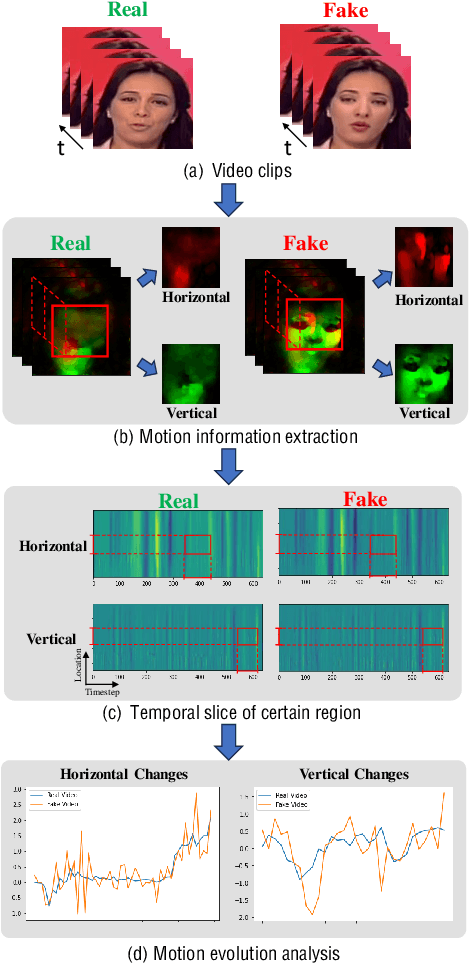

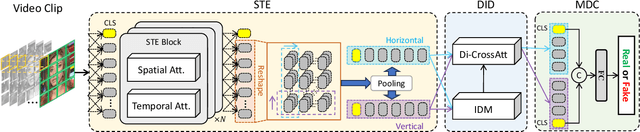
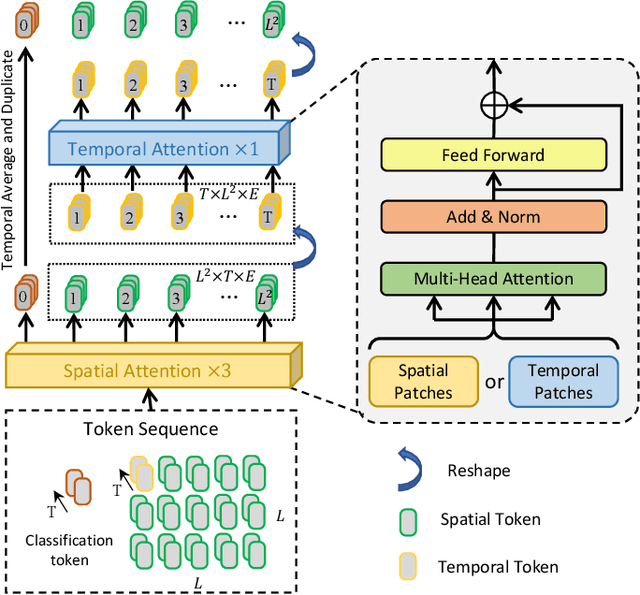
With the advancement of deepfake generation techniques, the importance of deepfake detection in protecting multimedia content integrity has become increasingly obvious. Recently, temporal inconsistency clues have been explored to improve the generalizability of deepfake video detection. According to our observation, the temporal artifacts of forged videos in terms of motion information usually exhibits quite distinct inconsistency patterns along horizontal and vertical directions, which could be leveraged to improve the generalizability of detectors. In this paper, a transformer-based framework for Diffusion Learning of Inconsistency Pattern (DIP) is proposed, which exploits directional inconsistencies for deepfake video detection. Specifically, DIP begins with a spatiotemporal encoder to represent spatiotemporal information. A directional inconsistency decoder is adopted accordingly, where direction-aware attention and inconsistency diffusion are incorporated to explore potential inconsistency patterns and jointly learn the inherent relationships. In addition, the SpatioTemporal Invariant Loss (STI Loss) is introduced to contrast spatiotemporally augmented sample pairs and prevent the model from overfitting nonessential forgery artifacts. Extensive experiments on several public datasets demonstrate that our method could effectively identify directional forgery clues and achieve state-of-the-art performance.
Generalizing Motion Planners with Mixture of Experts for Autonomous Driving
Oct 21, 2024



Large real-world driving datasets have sparked significant research into various aspects of data-driven motion planners for autonomous driving. These include data augmentation, model architecture, reward design, training strategies, and planner pipelines. These planners promise better generalizations on complicated and few-shot cases than previous methods. However, experiment results show that many of these approaches produce limited generalization abilities in planning performance due to overly complex designs or training paradigms. In this paper, we review and benchmark previous methods focusing on generalizations. The experimental results indicate that as models are appropriately scaled, many design elements become redundant. We introduce StateTransformer-2 (STR2), a scalable, decoder-only motion planner that uses a Vision Transformer (ViT) encoder and a mixture-of-experts (MoE) causal Transformer architecture. The MoE backbone addresses modality collapse and reward balancing by expert routing during training. Extensive experiments on the NuPlan dataset show that our method generalizes better than previous approaches across different test sets and closed-loop simulations. Furthermore, we assess its scalability on billions of real-world urban driving scenarios, demonstrating consistent accuracy improvements as both data and model size grow.
Learning Divergence Fields for Shift-Robust Graph Representations
Jun 07, 2024



Real-world data generation often involves certain geometries (e.g., graphs) that induce instance-level interdependence. This characteristic makes the generalization of learning models more difficult due to the intricate interdependent patterns that impact data-generative distributions and can vary from training to testing. In this work, we propose a geometric diffusion model with learnable divergence fields for the challenging generalization problem with interdependent data. We generalize the diffusion equation with stochastic diffusivity at each time step, which aims to capture the multi-faceted information flows among interdependent data. Furthermore, we derive a new learning objective through causal inference, which can guide the model to learn generalizable patterns of interdependence that are insensitive across domains. Regarding practical implementation, we introduce three model instantiations that can be considered as the generalized versions of GCN, GAT, and Transformers, respectively, which possess advanced robustness against distribution shifts. We demonstrate their promising efficacy for out-of-distribution generalization on diverse real-world datasets.
UAlign: Pushing the Limit of Template-free Retrosynthesis Prediction with Unsupervised SMILES Alignment
Mar 25, 2024Retrosynthesis planning poses a formidable challenge in the organic chemical industry, particularly in pharmaceuticals. Single-step retrosynthesis prediction, a crucial step in the planning process, has witnessed a surge in interest in recent years due to advancements in AI for science. Various deep learning-based methods have been proposed for this task in recent years, incorporating diverse levels of additional chemical knowledge dependency. This paper introduces UAlign, a template-free graph-to-sequence pipeline for retrosynthesis prediction. By combining graph neural networks and Transformers, our method can more effectively leverage the inherent graph structure of molecules. Based on the fact that the majority of molecule structures remain unchanged during a chemical reaction, we propose a simple yet effective SMILES alignment technique to facilitate the reuse of unchanged structures for reactant generation. Extensive experiments show that our method substantially outperforms state-of-the-art template-free and semi-template-based approaches. Importantly, Our template-free method achieves effectiveness comparable to, or even surpasses, established powerful template-based methods. Scientific contribution: We present a novel graph-to-sequence template-free retrosynthesis prediction pipeline that overcomes the limitations of Transformer-based methods in molecular representation learning and insufficient utilization of chemical information. We propose an unsupervised learning mechanism for establishing product-atom correspondence with reactant SMILES tokens, achieving even better results than supervised SMILES alignment methods. Extensive experiments demonstrate that UAlign significantly outperforms state-of-the-art template-free methods and rivals or surpasses template-based approaches, with up to 5\% (top-5) and 5.4\% (top-10) increased accuracy over the strongest baseline.
Graph Out-of-Distribution Generalization via Causal Intervention
Feb 18, 2024



Out-of-distribution (OOD) generalization has gained increasing attentions for learning on graphs, as graph neural networks (GNNs) often exhibit performance degradation with distribution shifts. The challenge is that distribution shifts on graphs involve intricate interconnections between nodes, and the environment labels are often absent in data. In this paper, we adopt a bottom-up data-generative perspective and reveal a key observation through causal analysis: the crux of GNNs' failure in OOD generalization lies in the latent confounding bias from the environment. The latter misguides the model to leverage environment-sensitive correlations between ego-graph features and target nodes' labels, resulting in undesirable generalization on new unseen nodes. Built upon this analysis, we introduce a conceptually simple yet principled approach for training robust GNNs under node-level distribution shifts, without prior knowledge of environment labels. Our method resorts to a new learning objective derived from causal inference that coordinates an environment estimator and a mixture-of-expert GNN predictor. The new approach can counteract the confounding bias in training data and facilitate learning generalizable predictive relations. Extensive experiment demonstrates that our model can effectively enhance generalization with various types of distribution shifts and yield up to 27.4\% accuracy improvement over state-of-the-arts on graph OOD generalization benchmarks. Source codes are available at https://github.com/fannie1208/CaNet.