 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-a-Verifier: A General-Purpose Verification Framework
Jul 06, 2026Scaling pre-training, post-training, and test-time compute have become the central paradigms for improving the capabilities of LLMs. In this work, we identify verification, the ability to determine the correctness of a solution, as a new scaling axis. To unlock this and demonstrate its effectiveness, we introduce LLM-as-a-Verifier, a general-purpose verification framework that provides fine-grained feedback for agentic tasks without requiring additional training. Unlike standard LM judges that prompt LLMs to produce discrete scores for candidate solutions, LLM-as-a-Verifier computes the expectation over the distribution of scoring token logits to generate continuous scores. This probabilistic formulation enables verification to scale along multiple dimensions: (1) score granularity, (2) repeated evaluation, and (3) criteria decomposition. In particular, we show that scaling the scoring granularity leads to better separation between positive and negative solutions, resulting in more calibrated comparisons. Moreover, scaling repeated evaluation and criteria decomposition consistently lead to additional gains in verification accuracy through variance and complexity reduction. We further introduce a cost-efficient ranking algorithm for selecting the best solution among candidates using the verifier's continuous scores. LLM-as-a-Verifier achieves state-of-the-art performance on Terminal-Bench V2 (86.5%), SWE-Bench Verified (78.2%), RoboRewardBench (87.4%), and MedAgentBench (73.3%). Beyond verification, the fine-grained signals from LLM-as-a-Verifier can also serve as a proxy for estimating task progress. We build an extension for Claude Code, enabling developers to monitor and improve their own agentic systems. Finally, we show that LLM-as-a-Verifier can provide dense feedback for RL, improving the sample efficiency of SAC and GRPO on robotics and mathematical reasoning benchmarks.
DREAM-Chunk: Reactive Action Chunking with Latent World Model
Jun 17, 2026Action chunking has become a common interface for vision-language-action (VLA) models, enabling low-frequency policy inference to drive high-frequency robot execution. However, once an action chunk is committed, its open-loop execution can be brittle under stochastic dynamics, hardware execution errors, and partial observability. We propose DREAM-Chunk, a test-time scaling method that augments chunking-based policies with a lightweight latent world model, without requiring additional policy fine-tuning. At test time, DREAM-Chunk samples multiple candidate action chunks, rolls out their predicted latent futures, and selects actions from the chunk whose predicted state best matches the observed rollout. In this way, DREAM-Chunk uses additional test-time computation to cover multiple plausible stochastic futures and improve reactivity during long-horizon chunk execution. On the Kinetix benchmark, DREAM-Chunk improves robustness under increasing action noise and benefits from larger candidate sample sizes, especially when demonstrations contain corrective behaviors. We further validate DREAM-Chunk on four manipulation tasks across two robot platforms and two VLA policies under various sources of stochasticity. Across simulation and hardware experiments, DREAM-Chunk improves the robustness of action-chunking policies in stochastic dynamics.
World Action Verifier: Self-Improving World Models via Forward-Inverse Asymmetry
Apr 02, 2026General-purpose world models promise scalable policy evaluation, optimization, and planning, yet achieving the required level of robustness remains challenging. Unlike policy learning, which primarily focuses on optimal actions, a world model must be reliable over a much broader range of suboptimal actions, which are often insufficiently covered by action-labeled interaction data. To address this challenge, we propose World Action Verifier (WAV), a framework that enables world models to identify their own prediction errors and self-improve. The key idea is to decompose action-conditioned state prediction into two factors -- state plausibility and action reachability -- and verify each separately. We show that these verification problems can be substantially easier than predicting future states due to two underlying asymmetries: the broader availability of action-free data and the lower dimensionality of action-relevant features. Leveraging these asymmetries, we augment a world model with (i) a diverse subgoal generator obtained from video corpora and (ii) a sparse inverse model that infers actions from a subset of state features. By enforcing cycle consistency among generated subgoals, inferred actions, and forward rollouts, WAV provides an effective verification mechanism in under-explored regimes, where existing methods typically fail. Across nine tasks spanning MiniGrid, RoboMimic, and ManiSkill, our method achieves 2x higher sample efficiency while improving downstream policy performance by 18%.
RoboMME: Benchmarking and Understanding Memory for Robotic Generalist Policies
Mar 04, 2026Memory is critical for long-horizon and history-dependent robotic manipulation. Such tasks often involve counting repeated actions or manipulating objects that become temporarily occluded. Recent vision-language-action (VLA) models have begun to incorporate memory mechanisms; however, their evaluations remain confined to narrow, non-standardized settings. This limits their systematic understanding, comparison, and progress measurement. To address these challenges, we introduce RoboMME: a large-scale standardized benchmark for evaluating and advancing VLA models in long-horizon, history-dependent scenarios. Our benchmark comprises 16 manipulation tasks constructed under a carefully designed taxonomy that evaluates temporal, spatial, object, and procedural memory. We further develop a suite of 14 memory-augmented VLA variants built on the π0.5 backbone to systematically explore different memory representations across multiple integration strategies. Experimental results show that the effectiveness of memory representations is highly task-dependent, with each design offering distinct advantages and limitations across different tasks. Videos and code can be found at our website https://robomme.github.io.
Scaling Verification Can Be More Effective than Scaling Policy Learning for Vision-Language-Action Alignment
Feb 12, 2026The long-standing vision of general-purpose robots hinges on their ability to understand and act upon natural language instructions. Vision-Language-Action (VLA) models have made remarkable progress toward this goal, yet their generated actions can still misalign with the given instructions. In this paper, we investigate test-time verification as a means to shrink the "intention-action gap.'' We first characterize the test-time scaling law for embodied instruction following and demonstrate that jointly scaling the number of rephrased instructions and generated actions greatly increases test-time sample diversity, often recovering correct actions more efficiently than scaling each dimension independently. To capitalize on these scaling laws, we present CoVer, a contrastive verifier for vision-language-action alignment, and show that our architecture scales gracefully with additional computational resources and data. We then introduce "boot-time compute" and a hierarchical verification inference pipeline for VLAs. At deployment, our framework precomputes a diverse set of rephrased instructions from a Vision-Language-Model (VLM), repeatedly generates action candidates for each instruction, and then uses a verifier to select the optimal high-level prompt and low-level action chunks. Compared to scaling policy pre-training on the same data, our verification approach yields 22% gains in-distribution and 13% out-of-distribution on the SIMPLER benchmark, with a further 45% improvement in real-world experiments. On the PolaRiS benchmark, CoVer achieves 14% gains in task progress and 9% in success rate.
Learning Long-Context Diffusion Policies via Past-Token Prediction
May 14, 2025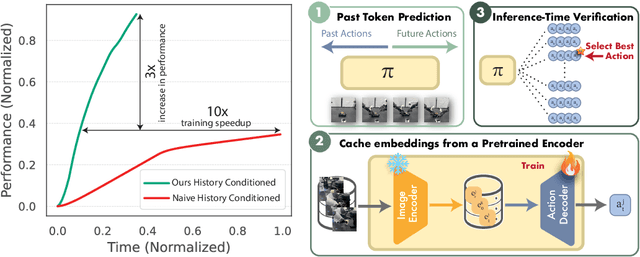


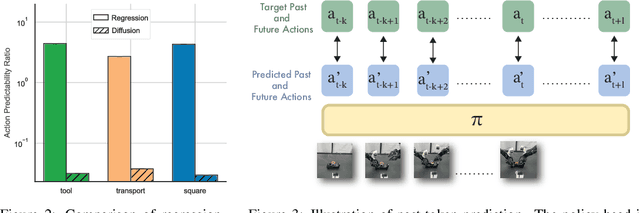
Reasoning over long sequences of observations and actions is essential for many robotic tasks. Yet, learning effective long-context policies from demonstrations remains challenging. As context length increases, training becomes increasingly expensive due to rising memory demands, and policy performance often degrades as a result of spurious correlations. Recent methods typically sidestep these issues by truncating context length, discarding historical information that may be critical for subsequent decisions. In this paper, we propose an alternative approach that explicitly regularizes the retention of past information. We first revisit the copycat problem in imitation learning and identify an opposite challenge in recent diffusion policies: rather than over-relying on prior actions, they often fail to capture essential dependencies between past and future actions. To address this, we introduce Past-Token Prediction (PTP), an auxiliary task in which the policy learns to predict past action tokens alongside future ones. This regularization significantly improves temporal modeling in the policy head, with minimal reliance on visual representations. Building on this observation, we further introduce a multistage training strategy: pre-train the visual encoder with short contexts, and fine-tune the policy head using cached long-context embeddings. This strategy preserves the benefits of PTP while greatly reducing memory and computational overhead. Finally, we extend PTP into a self-verification mechanism at test time, enabling the policy to score and select candidates consistent with past actions during inference. Experiments across four real-world and six simulated tasks demonstrate that our proposed method improves the performance of long-context diffusion policies by 3x and accelerates policy training by more than 10x.
Curating Demonstrations using Online Experience
Mar 05, 2025


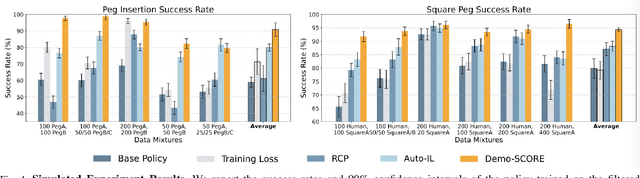
Many robot demonstration datasets contain heterogeneous demonstrations of varying quality. This heterogeneity may benefit policy pre-training, but can hinder robot performance when used with a final imitation learning objective. In particular, some strategies in the data may be less reliable than others or may be underrepresented in the data, leading to poor performance when such strategies are sampled at test time. Moreover, such unreliable or underrepresented strategies can be difficult even for people to discern, and sifting through demonstration datasets is time-consuming and costly. On the other hand, policy performance when trained on such demonstrations can reflect the reliability of different strategies. We thus propose for robots to self-curate based on online robot experience (Demo-SCORE). More specifically, we train and cross-validate a classifier to discern successful policy roll-outs from unsuccessful ones and use the classifier to filter heterogeneous demonstration datasets. Our experiments in simulation and the real world show that Demo-SCORE can effectively identify suboptimal demonstrations without manual curation. Notably, Demo-SCORE achieves over 15-35% higher absolute success rate in the resulting policy compared to the base policy trained with all original demonstrations.
TAROT: Targeted Data Selection via Optimal Transport
Nov 30, 2024



We propose TAROT, a targeted data selection framework grounded in optimal transport theory. Previous targeted data selection methods primarily rely on influence-based greedy heuristics to enhance domain-specific performance. While effective on limited, unimodal data (i.e., data following a single pattern), these methods struggle as target data complexity increases. Specifically, in multimodal distributions, these heuristics fail to account for multiple inherent patterns, leading to suboptimal data selection. This work identifies two primary factors contributing to this limitation: (i) the disproportionate impact of dominant feature components in high-dimensional influence estimation, and (ii) the restrictive linear additive assumptions inherent in greedy selection strategies. To address these challenges, TAROT incorporates whitened feature distance to mitigate dominant feature bias, providing a more reliable measure of data influence. Building on this, TAROT uses whitened feature distance to quantify and minimize the optimal transport distance between the selected data and target domains. Notably, this minimization also facilitates the estimation of optimal selection ratios. We evaluate TAROT across multiple tasks, including semantic segmentation, motion prediction, and instruction tuning. Results consistently show that TAROT outperforms state-of-the-art methods, highlighting its versatility across various deep learning tasks. Code is available at https://github.com/vita-epfl/TAROT.
Bidirectional Decoding: Improving Action Chunking via Closed-Loop Resampling
Aug 30, 2024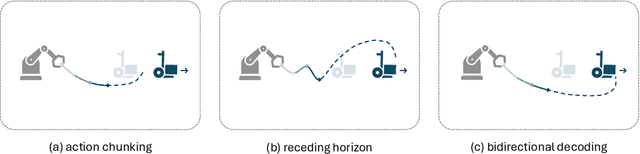
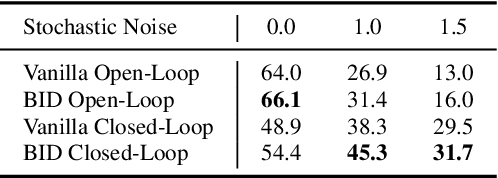
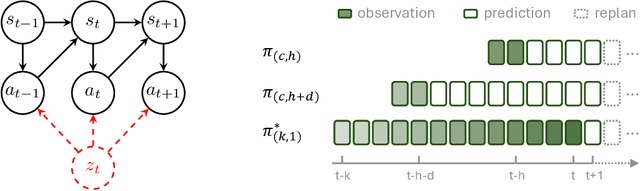
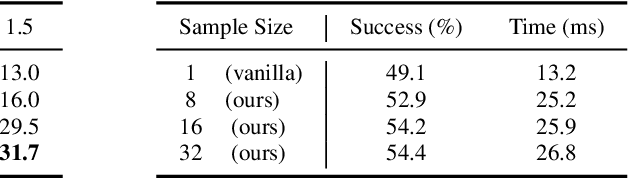
Predicting and executing a sequence of actions without intermediate replanning, known as action chunking, is increasingly used in robot learning from human demonstrations. However, its effects on learned policies remain puzzling: some studies highlight its importance for achieving strong performance, while others observe detrimental effects. In this paper, we first dissect the role of action chunking by analyzing the divergence between the learner and the demonstrator. We find that longer action chunks enable a policy to better capture temporal dependencies by taking into account more past states and actions within the chunk. However, this advantage comes at the cost of exacerbating errors in stochastic environments due to fewer observations of recent states. To address this, we propose Bidirectional Decoding (BID), a test-time inference algorithm that bridges action chunking with closed-loop operations. BID samples multiple predictions at each time step and searches for the optimal one based on two criteria: (i) backward coherence, which favors samples aligned with previous decisions, (ii) forward contrast, which favors samples close to outputs of a stronger policy and distant from those of a weaker policy. By coupling decisions within and across action chunks, BID enhances temporal consistency over extended sequences while enabling adaptive replanning in stochastic environments. Experimental results show that BID substantially outperforms conventional closed-loop operations of two state-of-the-art generative policies across seven simulation benchmarks and two real-world tasks.
Forecast-PEFT: Parameter-Efficient Fine-Tuning for Pre-trained Motion Forecasting Models
Jul 28, 2024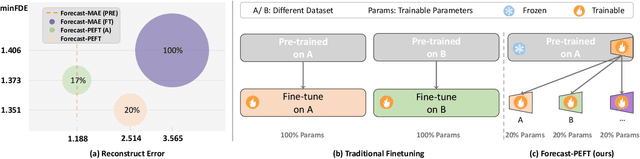
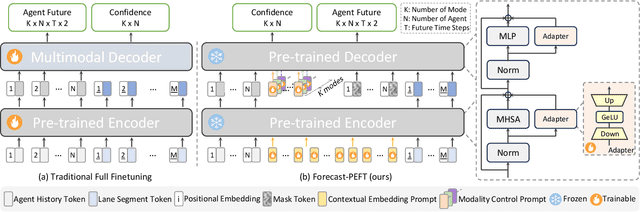
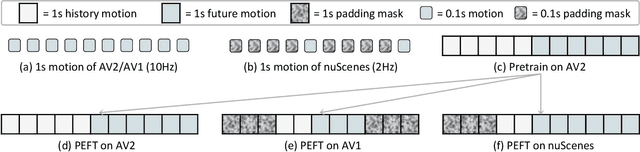
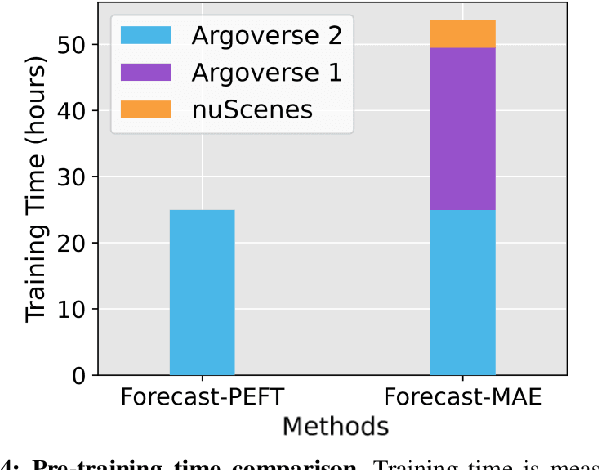
Recent progress in motion forecasting has been substantially driven by self-supervised pre-training. However, adapting pre-trained models for specific downstream tasks, especially motion prediction, through extensive fine-tuning is often inefficient. This inefficiency arises because motion prediction closely aligns with the masked pre-training tasks, and traditional full fine-tuning methods fail to fully leverage this alignment. To address this, we introduce Forecast-PEFT, a fine-tuning strategy that freezes the majority of the model's parameters, focusing adjustments on newly introduced prompts and adapters. This approach not only preserves the pre-learned representations but also significantly reduces the number of parameters that need retraining, thereby enhancing efficiency. This tailored strategy, supplemented by our method's capability to efficiently adapt to different datasets, enhances model efficiency and ensures robust performance across datasets without the need for extensive retraining. Our experiments show that Forecast-PEFT outperforms traditional full fine-tuning methods in motion prediction tasks, achieving higher accuracy with only 17% of the trainable parameters typically required. Moreover, our comprehensive adaptation, Forecast-FT, further improves prediction performance, evidencing up to a 9.6% enhancement over conventional baseline methods. Code will be available at https://github.com/csjfwang/Forecast-PEFT.