 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning via Implicit Imitation Guidance
Jun 09, 2025We study the problem of sample efficient reinforcement learning, where prior data such as demonstrations are provided for initialization in lieu of a dense reward signal. A natural approach is to incorporate an imitation learning objective, either as regularization during training or to acquire a reference policy. However, imitation learning objectives can ultimately degrade long-term performance, as it does not directly align with reward maximization. In this work, we propose to use prior data solely for guiding exploration via noise added to the policy, sidestepping the need for explicit behavior cloning constraints. The key insight in our framework, Data-Guided Noise (DGN), is that demonstrations are most useful for identifying which actions should be explored, rather than forcing the policy to take certain actions. Our approach achieves up to 2-3x improvement over prior reinforcement learning from offline data methods across seven simulated continuous control tasks.
Curating Demonstrations using Online Experience
Mar 05, 2025


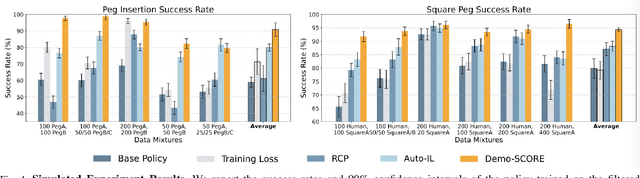
Many robot demonstration datasets contain heterogeneous demonstrations of varying quality. This heterogeneity may benefit policy pre-training, but can hinder robot performance when used with a final imitation learning objective. In particular, some strategies in the data may be less reliable than others or may be underrepresented in the data, leading to poor performance when such strategies are sampled at test time. Moreover, such unreliable or underrepresented strategies can be difficult even for people to discern, and sifting through demonstration datasets is time-consuming and costly. On the other hand, policy performance when trained on such demonstrations can reflect the reliability of different strategies. We thus propose for robots to self-curate based on online robot experience (Demo-SCORE). More specifically, we train and cross-validate a classifier to discern successful policy roll-outs from unsuccessful ones and use the classifier to filter heterogeneous demonstration datasets. Our experiments in simulation and the real world show that Demo-SCORE can effectively identify suboptimal demonstrations without manual curation. Notably, Demo-SCORE achieves over 15-35% higher absolute success rate in the resulting policy compared to the base policy trained with all original demonstrations.
Calibrating Language Models with Adaptive Temperature Scaling
Sep 29, 2024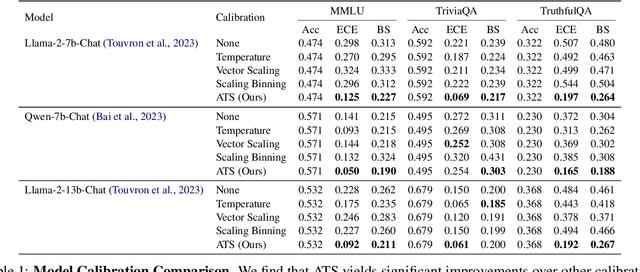

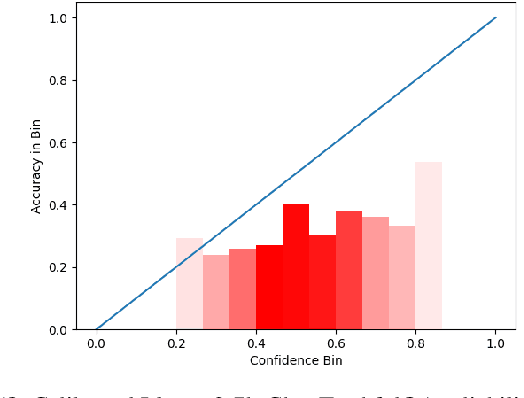
The effectiveness of large language models (LLMs) is not only measured by their ability to generate accurate outputs but also by their calibration-how well their confidence scores reflect the probability of their outputs being correct. While unsupervised pre-training has been shown to yield LLMs with well-calibrated conditional probabilities, recent studies have shown that after fine-tuning with reinforcement learning from human feedback (RLHF), the calibration of these models degrades significantly. In this work, we introduce Adaptive Temperature Scaling (ATS), a post-hoc calibration method that predicts a temperature scaling parameter for each token prediction. The predicted temperature values adapt based on token-level features and are fit over a standard supervised fine-tuning (SFT) dataset. The adaptive nature of ATS addresses the varying degrees of calibration shift that can occur after RLHF fine-tuning. ATS improves calibration by over 10-50% across three downstream natural language evaluation benchmarks compared to prior calibration methods and does not impede performance improvements from RLHF.
Commonsense Reasoning for Legged Robot Adaptation with Vision-Language Models
Jul 02, 2024

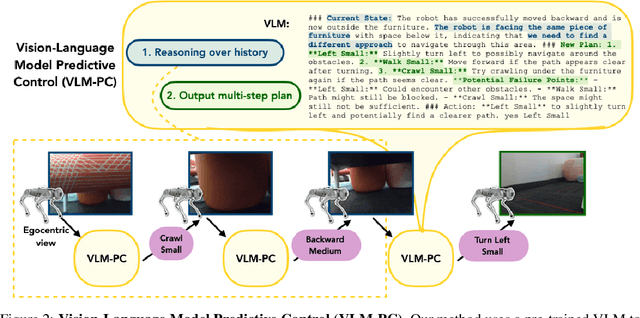

Legged robots are physically capable of navigating a diverse variety of environments and overcoming a wide range of obstructions. For example, in a search and rescue mission, a legged robot could climb over debris, crawl through gaps, and navigate out of dead ends. However, the robot's controller needs to respond intelligently to such varied obstacles, and this requires handling unexpected and unusual scenarios successfully. This presents an open challenge to current learning methods, which often struggle with generalization to the long tail of unexpected situations without heavy human supervision. To address this issue, we investigate how to leverage the broad knowledge about the structure of the world and commonsense reasoning capabilities of vision-language models (VLMs) to aid legged robots in handling difficult, ambiguous situations. We propose a system, VLM-Predictive Control (VLM-PC), combining two key components that we find to be crucial for eliciting on-the-fly, adaptive behavior selection with VLMs: (1) in-context adaptation over previous robot interactions and (2) planning multiple skills into the future and replanning. We evaluate VLM-PC on several challenging real-world obstacle courses, involving dead ends and climbing and crawling, on a Go1 quadruped robot. Our experiments show that by reasoning over the history of interactions and future plans, VLMs enable the robot to autonomously perceive, navigate, and act in a wide range of complex scenarios that would otherwise require environment-specific engineering or human guidance.
Self-Guided Masked Autoencoders for Domain-Agnostic Self-Supervised Learning
Feb 22, 2024



Self-supervised learning excels in learning representations from large amounts of unlabeled data, demonstrating success across multiple data modalities. Yet, extending self-supervised learning to new modalities is non-trivial because the specifics of existing methods are tailored to each domain, such as domain-specific augmentations which reflect the invariances in the target task. While masked modeling is promising as a domain-agnostic framework for self-supervised learning because it does not rely on input augmentations, its mask sampling procedure remains domain-specific. We present Self-guided Masked Autoencoders (SMA), a fully domain-agnostic masked modeling method. SMA trains an attention based model using a masked modeling objective, by learning masks to sample without any domain-specific assumptions. We evaluate SMA on three self-supervised learning benchmarks in protein biology, chemical property prediction, and particle physics. We find SMA is capable of learning representations without domain-specific knowledge and achieves state-of-the-art performance on these three benchmarks.
Adapt On-the-Go: Behavior Modulation for Single-Life Robot Deployment
Nov 02, 2023



To succeed in the real world, robots must cope with situations that differ from those seen during training. We study the problem of adapting on-the-fly to such novel scenarios during deployment, by drawing upon a diverse repertoire of previously learned behaviors. Our approach, RObust Autonomous Modulation (ROAM), introduces a mechanism based on the perceived value of pre-trained behaviors to select and adapt pre-trained behaviors to the situation at hand. Crucially, this adaptation process all happens within a single episode at test time, without any human supervision. We provide theoretical analysis of our selection mechanism and demonstrate that ROAM enables a robot to adapt rapidly to changes in dynamics both in simulation and on a real Go1 quadruped, even successfully moving forward with roller skates on its feet. Our approach adapts over 2x as efficiently compared to existing methods when facing a variety of out-of-distribution situations during deployment by effectively choosing and adapting relevant behaviors on-the-fly.
Confidence-Based Model Selection: When to Take Shortcuts for Subpopulation Shifts
Jun 19, 2023



Effective machine learning models learn both robust features that directly determine the outcome of interest (e.g., an object with wheels is more likely to be a car), and shortcut features (e.g., an object on a road is more likely to be a car). The latter can be a source of error under distributional shift, when the correlations change at test-time. The prevailing sentiment in the robustness literature is to avoid such correlative shortcut features and learn robust predictors. However, while robust predictors perform better on worst-case distributional shifts, they often sacrifice accuracy on majority subpopulations. In this paper, we argue that shortcut features should not be entirely discarded. Instead, if we can identify the subpopulation to which an input belongs, we can adaptively choose among models with different strengths to achieve high performance on both majority and minority subpopulations. We propose COnfidence-baSed MOdel Selection (CosMoS), where we observe that model confidence can effectively guide model selection. Notably, CosMoS does not require any target labels or group annotations, either of which may be difficult to obtain or unavailable. We evaluate CosMoS on four datasets with spurious correlations, each with multiple test sets with varying levels of data distribution shift. We find that CosMoS achieves 2-5% lower average regret across all subpopulations, compared to using only robust predictors or other model aggregation methods.
Language-Driven Representation Learning for Robotics
Feb 24, 2023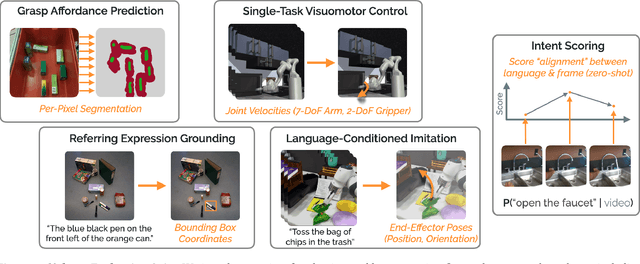

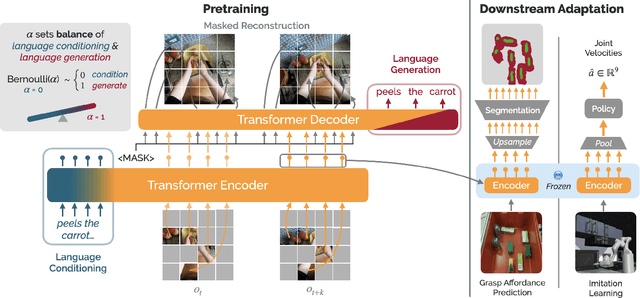
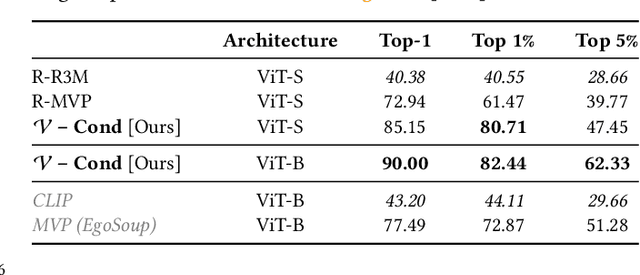
Recent work in visual representation learning for robotics demonstrates the viability of learning from large video datasets of humans performing everyday tasks. Leveraging methods such as masked autoencoding and contrastive learning, these representations exhibit strong transfer to policy learning for visuomotor control. But, robot learning encompasses a diverse set of problems beyond control including grasp affordance prediction, language-conditioned imitation learning, and intent scoring for human-robot collaboration, amongst others. First, we demonstrate that existing representations yield inconsistent results across these tasks: masked autoencoding approaches pick up on low-level spatial features at the cost of high-level semantics, while contrastive learning approaches capture the opposite. We then introduce Voltron, a framework for language-driven representation learning from human videos and associated captions. Voltron trades off language-conditioned visual reconstruction to learn low-level visual patterns, and visually-grounded language generation to encode high-level semantics. We also construct a new evaluation suite spanning five distinct robot learning problems $\unicode{x2013}$ a unified platform for holistically evaluating visual representations for robotics. Through comprehensive, controlled experiments across all five problems, we find that Voltron's language-driven representations outperform the prior state-of-the-art, especially on targeted problems requiring higher-level features.
Project and Probe: Sample-Efficient Domain Adaptation by Interpolating Orthogonal Features
Feb 10, 2023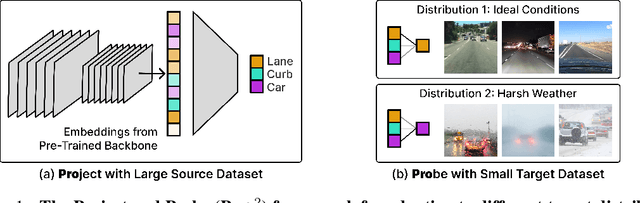

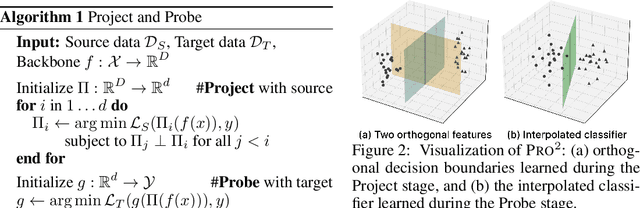
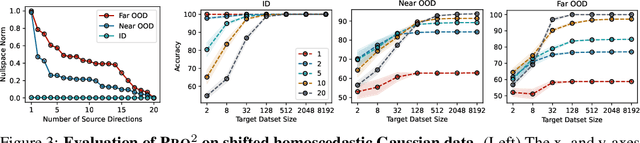
Conventional approaches to robustness try to learn a model based on causal features. However, identifying maximally robust or causal features may be difficult in some scenarios, and in others, non-causal "shortcut" features may actually be more predictive. We propose a lightweight, sample-efficient approach that learns a diverse set of features and adapts to a target distribution by interpolating these features with a small target dataset. Our approach, Project and Probe (Pro$^2$), first learns a linear projection that maps a pre-trained embedding onto orthogonal directions while being predictive of labels in the source dataset. The goal of this step is to learn a variety of predictive features, so that at least some of them remain useful after distribution shift. Pro$^2$ then learns a linear classifier on top of these projected features using a small target dataset. We theoretically show that Pro$^2$ learns a projection matrix that is optimal for classification in an information-theoretic sense, resulting in better generalization due to a favorable bias-variance tradeoff. Our experiments on four datasets, with multiple distribution shift settings for each, show that Pro$^2$ improves performance by 5-15% when given limited target data compared to prior methods such as standard linear probing.
Surgical Fine-Tuning Improves Adaptation to Distribution Shifts
Oct 20, 2022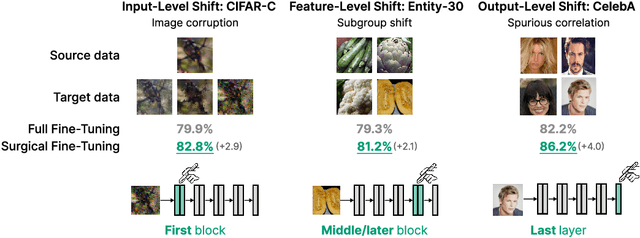
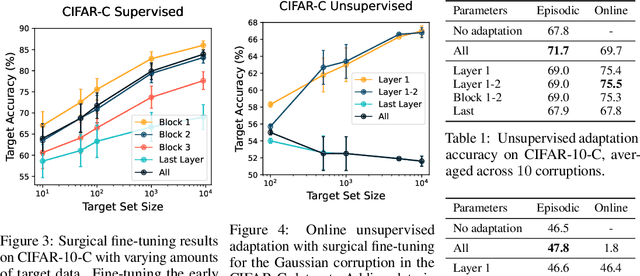
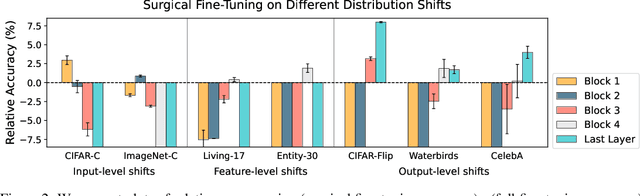
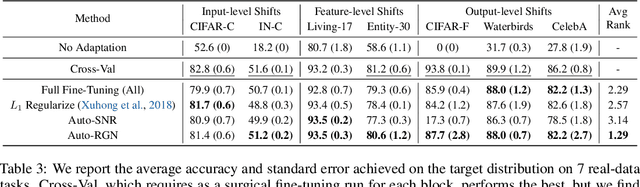
A common approach to transfer learning under distribution shift is to fine-tune the last few layers of a pre-trained model, preserving learned features while also adapting to the new task. This paper shows that in such settings, selectively fine-tuning a subset of layers (which we term surgical fine-tuning) matches or outperforms commonly used fine-tuning approaches. Moreover, the type of distribution shift influences which subset is more effective to tune: for example, for image corruptions, fine-tuning only the first few layers works best. We validate our findings systematically across seven real-world data tasks spanning three types of distribution shifts. Theoretically, we prove that for two-layer neural networks in an idealized setting, first-layer tuning can outperform fine-tuning all layers. Intuitively, fine-tuning more parameters on a small target dataset can cause information learned during pre-training to be forgotten, and the relevant information depends on the type of shift.