 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoregressive Flow Matching for Motion Prediction
Dec 27, 2025Motion prediction has been studied in different contexts with models trained on narrow distributions and applied to downstream tasks in human motion prediction and robotics. Simultaneously, recent efforts in scaling video prediction have demonstrated impressive visual realism, yet they struggle to accurately model complex motions despite massive scale. Inspired by the scaling of video generation, we develop autoregressive flow matching (ARFM), a new method for probabilistic modeling of sequential continuous data and train it on diverse video datasets to generate future point track locations over long horizons. To evaluate our model, we develop benchmarks for evaluating the ability of motion prediction models to predict human and robot motion. Our model is able to predict complex motions, and we demonstrate that conditioning robot action prediction and human motion prediction on predicted future tracks can significantly improve downstream task performance. Code and models publicly available at: https://github.com/Johnathan-Xie/arfm-motion-prediction.
Calibrating Language Models with Adaptive Temperature Scaling
Sep 29, 2024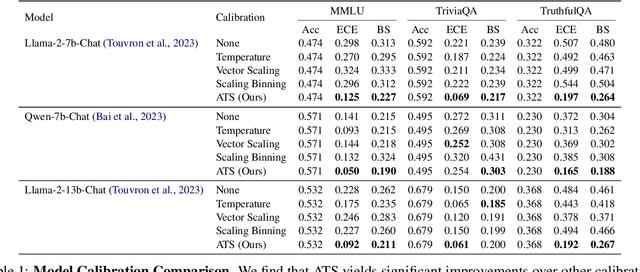

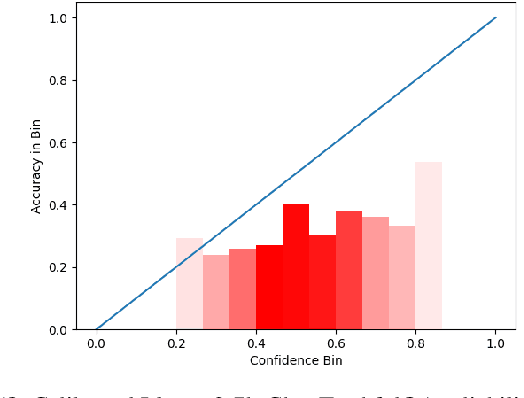
The effectiveness of large language models (LLMs) is not only measured by their ability to generate accurate outputs but also by their calibration-how well their confidence scores reflect the probability of their outputs being correct. While unsupervised pre-training has been shown to yield LLMs with well-calibrated conditional probabilities, recent studies have shown that after fine-tuning with reinforcement learning from human feedback (RLHF), the calibration of these models degrades significantly. In this work, we introduce Adaptive Temperature Scaling (ATS), a post-hoc calibration method that predicts a temperature scaling parameter for each token prediction. The predicted temperature values adapt based on token-level features and are fit over a standard supervised fine-tuning (SFT) dataset. The adaptive nature of ATS addresses the varying degrees of calibration shift that can occur after RLHF fine-tuning. ATS improves calibration by over 10-50% across three downstream natural language evaluation benchmarks compared to prior calibration methods and does not impede performance improvements from RLHF.
Self-Guided Masked Autoencoders for Domain-Agnostic Self-Supervised Learning
Feb 22, 2024



Self-supervised learning excels in learning representations from large amounts of unlabeled data, demonstrating success across multiple data modalities. Yet, extending self-supervised learning to new modalities is non-trivial because the specifics of existing methods are tailored to each domain, such as domain-specific augmentations which reflect the invariances in the target task. While masked modeling is promising as a domain-agnostic framework for self-supervised learning because it does not rely on input augmentations, its mask sampling procedure remains domain-specific. We present Self-guided Masked Autoencoders (SMA), a fully domain-agnostic masked modeling method. SMA trains an attention based model using a masked modeling objective, by learning masks to sample without any domain-specific assumptions. We evaluate SMA on three self-supervised learning benchmarks in protein biology, chemical property prediction, and particle physics. We find SMA is capable of learning representations without domain-specific knowledge and achieves state-of-the-art performance on these three benchmarks.
ZSD-YOLO: Zero-Shot YOLO Detection using Vision-Language KnowledgeDistillation
Sep 24, 2021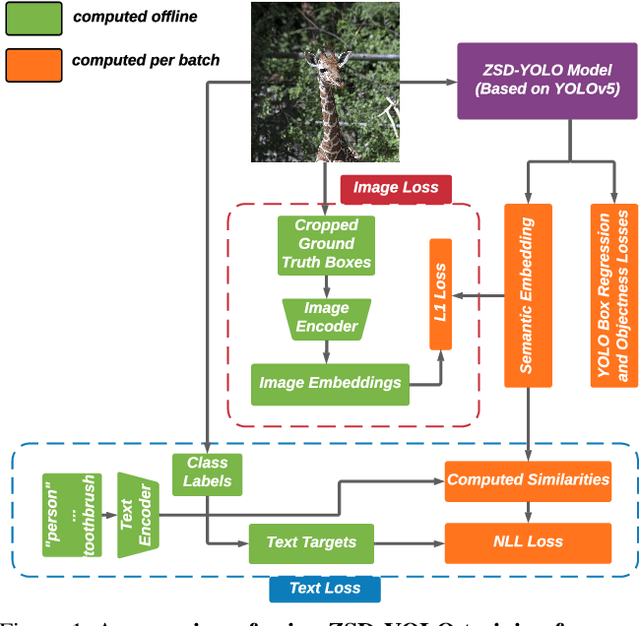
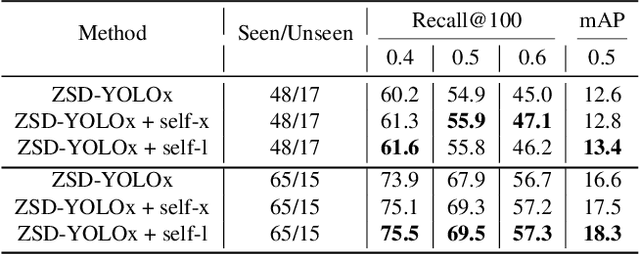
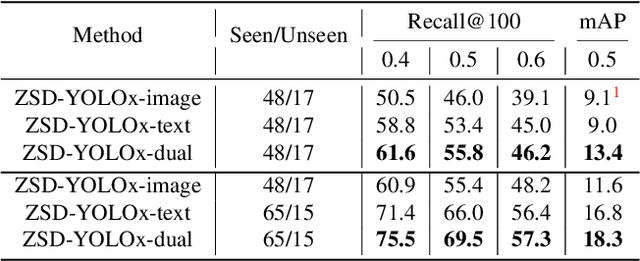

Real-world object sampling produces long-tailed distributions requiring exponentially more images for rare types. Zero-shot detection, which aims to detect unseen objects, is one direction to address this problem. A dataset such as COCO is extensively annotated across many images but with a sparse number of categories and annotating all object classes across a diverse domain is expensive and challenging. To advance zero-shot detection, we develop a Vision-Language distillation method that aligns both image and text embeddings from a zero-shot pre-trained model such as CLIP to a modified semantic prediction head from a one-stage detector like YOLOv5. With this method, we are able to train an object detector that achieves state-of-the-art accuracy on the COCO zero-shot detection splits with fewer model parameters. During inference, our model can be adapted to detect any number of object classes without additional training. We also find that the improvements provided by the scaling of our method are consistent across various YOLOv5 scales. Furthermore, we develop a self-training method that provides a significant score improvement without needing extra images nor labels.