 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZSD-YOLO: Zero-Shot YOLO Detection using Vision-Language KnowledgeDistillation
Paper and Code
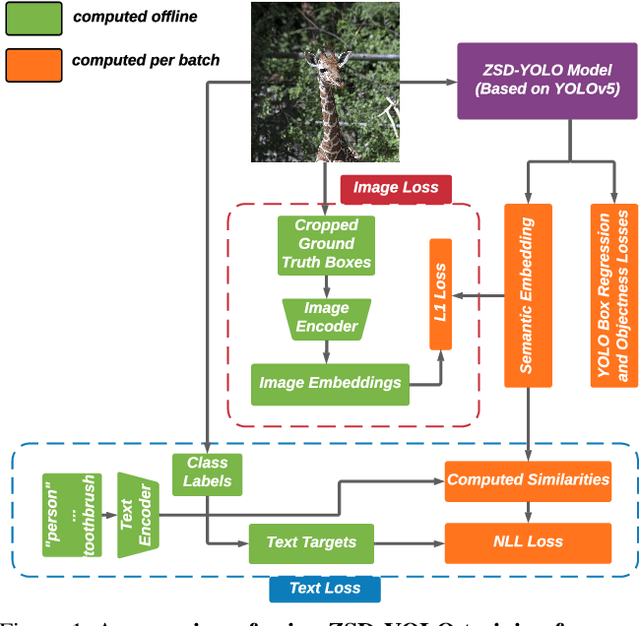
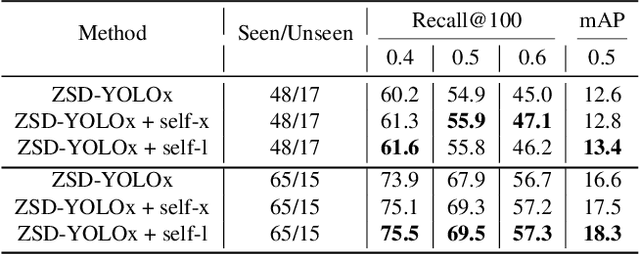
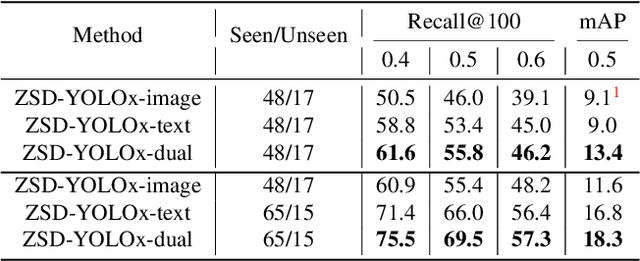

Real-world object sampling produces long-tailed distributions requiring exponentially more images for rare types. Zero-shot detection, which aims to detect unseen objects, is one direction to address this problem. A dataset such as COCO is extensively annotated across many images but with a sparse number of categories and annotating all object classes across a diverse domain is expensive and challenging. To advance zero-shot detection, we develop a Vision-Language distillation method that aligns both image and text embeddings from a zero-shot pre-trained model such as CLIP to a modified semantic prediction head from a one-stage detector like YOLOv5. With this method, we are able to train an object detector that achieves state-of-the-art accuracy on the COCO zero-shot detection splits with fewer model parameters. During inference, our model can be adapted to detect any number of object classes without additional training. We also find that the improvements provided by the scaling of our method are consistent across various YOLOv5 scales. Furthermore, we develop a self-training method that provides a significant score improvement without needing extra images nor labels.