 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting General Map Search via Generative Point-of-Interest Retrieval
May 05, 2026Point-of-Interest (POI) retrieval aims to identify relevant candidates from massive-scale POI databases, serving as a cornerstone for diverse location-based services. However, in general map search scenarios, conventional POI retrieval methods are increasingly challenged by underspecified user queries due to their excessive reliance on surface-level semantic matching. Meanwhile, such queries are often highly context-dependent and personalized, yet existing retrieval paradigms struggle to effectively synergize heterogeneous contexts for complex search intent inference. To address these limitations, we revisit general map search from a generative perspective and propose GenPOI, an innovative Generative POI retrieval framework tailored for general search on maps. It seamlessly unifies heterogeneous search contexts and POIs into structured sequences, leveraging the powerful contextual modeling of Large Language Models (LLMs) for spatial-aware candidate generation. Consequently, this generative paradigm effectively solves more challenging queries through profound context dependency modeling and search intent reasoning. Specifically, accounting for the unique geospatial nature of map scenarios, GenPOI introduces a novel Geo-Semantic POI Tokenization to represent each POI as a compact token sequence encoding both semantic and geographic context, thus grounding the LLM's spatial understanding. Additionally, a proximity-aware constrained generation strategy is employed to restrict the decoding space of the LLM, ensuring the validity and geospatial relevance of the generated results. Extensive experiments on large-scale industrial datasets from Tencent Map, comprising POIs at the scale of over 10 million, demonstrate the superior performance of GenPOI.
Towards Effective and Efficient Graph Alignment without Supervision
Mar 09, 2026Unsupervised graph alignment aims to find the node correspondence across different graphs without any anchor node pairs. Despite the recent efforts utilizing deep learning-based techniques, such as the embedding and optimal transport (OT)-based approaches, we observe their limitations in terms of model accuracy-efficiency tradeoff. By focusing on the exploitation of local and global graph information, we formalize them as the ``local representation, global alignment'' paradigm, and present a new ``global representation and alignment'' paradigm to resolve the mismatch between the two phases in the alignment process. We then propose \underline{Gl}obal representation and \underline{o}ptimal transport-\underline{b}ased \underline{Align}ment (\texttt{GlobAlign}), and its variant, \texttt{GlobAlign-E}, for better \underline{E}fficiency. Our methods are equipped with the global attention mechanism and a hierarchical cross-graph transport cost, able to capture long-range and implicit node dependencies beyond the local graph structure. Furthermore, \texttt{GlobAlign-E} successfully closes the time complexity gap between representative embedding and OT-based methods, reducing OT's cubic complexity to quadratic terms. Through extensive experiments, our methods demonstrate superior performance, with up to a 20\% accuracy improvement over the best competitor. Meanwhile, \texttt{GlobAlign-E} achieves the best efficiency, with an order of magnitude speedup against existing OT-based methods.
Scalable Dexterous Robot Learning with AR-based Remote Human-Robot Interactions
Feb 07, 2026This paper focuses on the scalable robot learning for manipulation in the dexterous robot arm-hand systems, where the remote human-robot interactions via augmented reality (AR) are established to collect the expert demonstration data for improving efficiency. In such a system, we present a unified framework to address the general manipulation task problem. Specifically, the proposed method consists of two phases: i) In the first phase for pretraining, the policy is created in a behavior cloning (BC) manner, through leveraging the learning data from our AR-based remote human-robot interaction system; ii) In the second phase, a contrastive learning empowered reinforcement learning (RL) method is developed to obtain more efficient and robust policy than the BC, and thus a projection head is designed to accelerate the learning progress. An event-driven augmented reward is adopted for enhancing the safety. To validate the proposed method, both the physics simulations via PyBullet and real-world experiments are carried out. The results demonstrate that compared to the classic proximal policy optimization and soft actor-critic policies, our method not only significantly speeds up the inference, but also achieves much better performance in terms of the success rate for fulfilling the manipulation tasks. By conducting the ablation study, it is confirmed that the proposed RL with contrastive learning overcomes policy collapse. Supplementary demonstrations are available at https://cyberyyc.github.io/.
Towards Pre-trained Graph Condensation via Optimal Transport
Sep 18, 2025Graph condensation (GC) aims to distill the original graph into a small-scale graph, mitigating redundancy and accelerating GNN training. However, conventional GC approaches heavily rely on rigid GNNs and task-specific supervision. Such a dependency severely restricts their reusability and generalization across various tasks and architectures. In this work, we revisit the goal of ideal GC from the perspective of GNN optimization consistency, and then a generalized GC optimization objective is derived, by which those traditional GC methods can be viewed nicely as special cases of this optimization paradigm. Based on this, Pre-trained Graph Condensation (PreGC) via optimal transport is proposed to transcend the limitations of task- and architecture-dependent GC methods. Specifically, a hybrid-interval graph diffusion augmentation is presented to suppress the weak generalization ability of the condensed graph on particular architectures by enhancing the uncertainty of node states. Meanwhile, the matching between optimal graph transport plan and representation transport plan is tactfully established to maintain semantic consistencies across source graph and condensed graph spaces, thereby freeing graph condensation from task dependencies. To further facilitate the adaptation of condensed graphs to various downstream tasks, a traceable semantic harmonizer from source nodes to condensed nodes is proposed to bridge semantic associations through the optimized representation transport plan in pre-training. Extensive experiments verify the superiority and versatility of PreGC, demonstrating its task-independent nature and seamless compatibility with arbitrary GNNs.
Dynamic Graph Condensation
Jun 16, 2025Recent research on deep graph learning has shifted from static to dynamic graphs, motivated by the evolving behaviors observed in complex real-world systems. However, the temporal extension in dynamic graphs poses significant data efficiency challenges, including increased data volume, high spatiotemporal redundancy, and reliance on costly dynamic graph neural networks (DGNNs). To alleviate the concerns, we pioneer the study of dynamic graph condensation (DGC), which aims to substantially reduce the scale of dynamic graphs for data-efficient DGNN training. Accordingly, we propose DyGC, a novel framework that condenses the real dynamic graph into a compact version while faithfully preserving the inherent spatiotemporal characteristics. Specifically, to endow synthetic graphs with realistic evolving structures, a novel spiking structure generation mechanism is introduced. It draws on the dynamic behavior of spiking neurons to model temporally-aware connectivity in dynamic graphs. Given the tightly coupled spatiotemporal dependencies, DyGC proposes a tailored distribution matching approach that first constructs a semantically rich state evolving field for dynamic graphs, and then performs fine-grained spatiotemporal state alignment to guide the optimization of the condensed graph. Experiments across multiple dynamic graph datasets and representative DGNN architectures demonstrate the effectiveness of DyGC. Notably, our method retains up to 96.2% DGNN performance with only 0.5% of the original graph size, and achieves up to 1846 times training speedup.
FineQ: Software-Hardware Co-Design for Low-Bit Fine-Grained Mixed-Precision Quantization of LLMs
Apr 28, 2025Large language models (LLMs) have significantly advanced the natural language processing paradigm but impose substantial demands on memory and computational resources. Quantization is one of the most effective ways to reduce memory consumption of LLMs. However, advanced single-precision quantization methods experience significant accuracy degradation when quantizing to ultra-low bits. Existing mixed-precision quantization methods are quantized by groups with coarse granularity. Employing high precision for group data leads to substantial memory overhead, whereas low precision severely impacts model accuracy. To address this issue, we propose FineQ, software-hardware co-design for low-bit fine-grained mixed-precision quantization of LLMs. First, FineQ partitions the weights into finer-grained clusters and considers the distribution of outliers within these clusters, thus achieving a balance between model accuracy and memory overhead. Then, we propose an outlier protection mechanism within clusters that uses 3 bits to represent outliers and introduce an encoding scheme for index and data concatenation to enable aligned memory access. Finally, we introduce an accelerator utilizing temporal coding that effectively supports the quantization algorithm while simplifying the multipliers in the systolic array. FineQ achieves higher model accuracy compared to the SOTA mixed-precision quantization algorithm at a close average bit-width. Meanwhile, the accelerator achieves up to 1.79x energy efficiency and reduces the area of the systolic array by 61.2%.
A Pioneering Neural Network Method for Efficient and Robust Fuel Sloshing Simulation in Aircraft
Dec 14, 2024



Simulating fuel sloshing within aircraft tanks during flight is crucial for aircraft safety research. Traditional methods based on Navier-Stokes equations are computationally expensive. In this paper, we treat fluid motion as point cloud transformation and propose the first neural network method specifically designed for simulating fuel sloshing in aircraft. This model is also the deep learning model that is the first to be capable of stably modeling fluid particle dynamics in such complex scenarios. Our triangle feature fusion design achieves an optimal balance among fluid dynamics modeling, momentum conservation constraints, and global stability control. Additionally, we constructed the Fueltank dataset, the first dataset for aircraft fuel surface sloshing. It comprises 320,000 frames across four typical tank types and covers a wide range of flight maneuvers, including multi-directional rotations. We conducted comprehensive experiments on both our dataset and the take-off scenario of the aircraft. Compared to existing neural network-based fluid simulation algorithms, we significantly enhanced accuracy while maintaining high computational speed. Compared to traditional SPH methods, our speed improved approximately 10 times. Furthermore, compared to traditional fluid simulation software such as Flow3D, our computation speed increased by more than 300 times.
FlexCare: Leveraging Cross-Task Synergy for Flexible Multimodal Healthcare Prediction
Jun 17, 2024
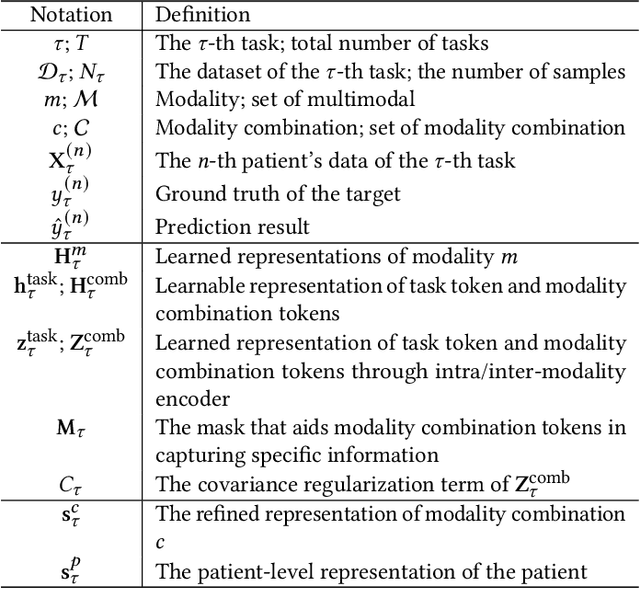

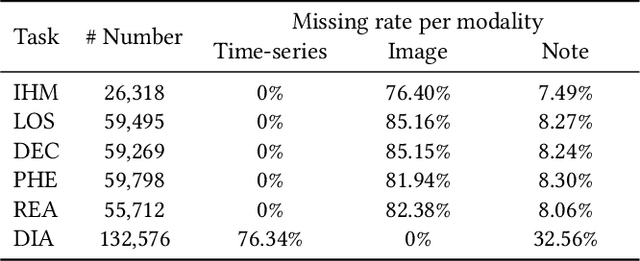
Multimodal electronic health record (EHR) data can offer a holistic assessment of a patient's health status, supporting various predictive healthcare tasks. Recently, several studies have embraced the multitask learning approach in the healthcare domain, exploiting the inherent correlations among clinical tasks to predict multiple outcomes simultaneously. However, existing methods necessitate samples to possess complete labels for all tasks, which places heavy demands on the data and restricts the flexibility of the model. Meanwhile, within a multitask framework with multimodal inputs, how to comprehensively consider the information disparity among modalities and among tasks still remains a challenging problem. To tackle these issues, a unified healthcare prediction model, also named by \textbf{FlexCare}, is proposed to flexibly accommodate incomplete multimodal inputs, promoting the adaption to multiple healthcare tasks. The proposed model breaks the conventional paradigm of parallel multitask prediction by decomposing it into a series of asynchronous single-task prediction. Specifically, a task-agnostic multimodal information extraction module is presented to capture decorrelated representations of diverse intra- and inter-modality patterns. Taking full account of the information disparities between different modalities and different tasks, we present a task-guided hierarchical multimodal fusion module that integrates the refined modality-level representations into an individual patient-level representation. Experimental results on multiple tasks from MIMIC-IV/MIMIC-CXR/MIMIC-NOTE datasets demonstrate the effectiveness of the proposed method. Additionally, further analysis underscores the feasibility and potential of employing such a multitask strategy in the healthcare domain. The source code is available at https://github.com/mhxu1998/FlexCare.
Lancet: Accelerating Mixture-of-Experts Training via Whole Graph Computation-Communication Overlapping
Apr 30, 2024



The Mixture-of-Expert (MoE) technique plays a crucial role in expanding the size of DNN model parameters. However, it faces the challenge of extended all-to-all communication latency during the training process. Existing methods attempt to mitigate this issue by overlapping all-to-all with expert computation. Yet, these methods frequently fall short of achieving sufficient overlap, consequently restricting the potential for performance enhancements. In our study, we extend the scope of this challenge by considering overlap at the broader training graph level. During the forward pass, we enable non-MoE computations to overlap with all-to-all through careful partitioning and pipelining. In the backward pass, we achieve overlap with all-to-all by scheduling gradient weight computations. We implement these techniques in Lancet, a system using compiler-based optimization to automatically enhance MoE model training. Our extensive evaluation reveals that Lancet significantly reduces the time devoted to non-overlapping communication, by as much as 77%. Moreover, it achieves a notable end-to-end speedup of up to 1.3 times when compared to the state-of-the-art solutions.
DualFluidNet: an Attention-based Dual-pipeline Network for Accurate and Generalizable Fluid-solid Coupled Simulation
Dec 28, 2023



Fluid motion can be considered as point cloud transformation when adopted by a Lagrangian description. Compared to traditional numerical analysis methods, using machine learning techniques to learn physics simulations can achieve near accuracy, while significantly increasing efficiency. In this paper, we propose an innovative approach for 3D fluid simulations utilizing an Attention-based Dual-pipeline Network, which employs a dual-pipeline architecture, seamlessly integrated with an Attention-based Feature Fusion Module. Unlike previous single-pipeline approaches, we find that a well-designed dual-pipeline approach achieves a better balance between global fluid control and physical law constraints. Furthermore, we design a Type-aware Input Module to adaptively recognize particles of different types and perform feature fusion afterward, such that fluid-solid coupling issues can be better dealt with. The experiments show that our approach significantly increases the accuracy of fluid simulation predictions and enhances generalizability to previously unseen scenarios. We demonstrate its superior performance over the state-of-the-art approaches across various metrics.