 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraceable Drug Recommendation over Medical Knowledge Graphs
Oct 31, 2025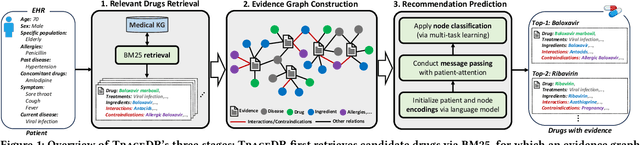
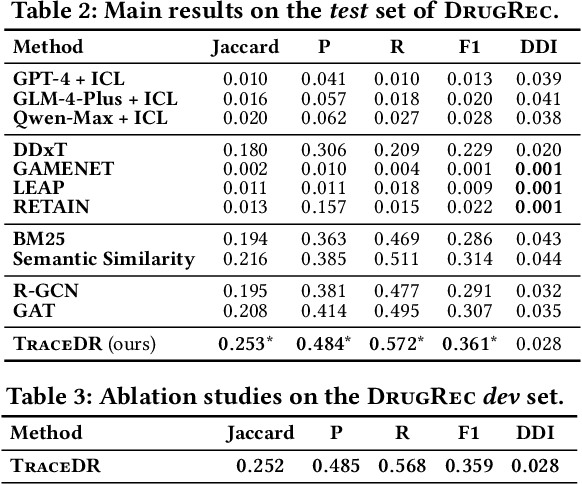

Drug recommendation (DR) systems aim to support healthcare professionals in selecting appropriate medications based on patients' medical conditions. State-of-the-art approaches utilize deep learning techniques for improving DR, but fall short in providing any insights on the derivation process of recommendations -- a critical limitation in such high-stake applications. We propose TraceDR, a novel DR system operating over a medical knowledge graph (MKG), which ensures access to large-scale and high-quality information. TraceDR simultaneously predicts drug recommendations and related evidence within a multi-task learning framework, enabling traceability of medication recommendations. For covering a more diverse set of diseases and drugs than existing works, we devise a framework for automatically constructing patient health records and release DrugRec, a new large-scale testbed for DR.
TTrace: Lightweight Error Checking and Diagnosis for Distributed Training
Jun 10, 2025Distributed training is essential for scaling the training of large neural network models, such as large language models (LLMs), across thousands of GPUs. However, the complexity of distributed training programs makes them particularly prone to silent bugs, which do not produce explicit error signal but lead to incorrect training outcome. Effectively detecting and localizing such silent bugs in distributed training is challenging. Common debugging practice using metrics like training loss or gradient norm curves can be inefficient and ineffective. Additionally, obtaining intermediate tensor values and determining whether they are correct during silent bug localization is difficult, particularly in the context of low-precision training. To address those challenges, we design and implement TTrace, the first system capable of detecting and localizing silent bugs in distributed training. TTrace collects intermediate tensors from distributing training in a fine-grained manner and compares them against those from a trusted single-device reference implementation. To properly compare the floating-point values in the tensors, we propose novel mathematical analysis that provides a guideline for setting thresholds, enabling TTrace to distinguish bug-induced errors from floating-point round-off errors. Experimental results demonstrate that TTrace effectively detects 11 existing bugs and 3 new bugs in the widely used Megatron-LM framework, while requiring fewer than 10 lines of code change. TTrace is effective in various training recipes, including low-precision recipes involving BF16 and FP8.
Extrapolated Urban View Synthesis Benchmark
Dec 10, 2024



Photorealistic simulators are essential for the training and evaluation of vision-centric autonomous vehicles (AVs). At their core is Novel View Synthesis (NVS), a crucial capability that generates diverse unseen viewpoints to accommodate the broad and continuous pose distribution of AVs. Recent advances in radiance fields, such as 3D Gaussian Splatting, achieve photorealistic rendering at real-time speeds and have been widely used in modeling large-scale driving scenes. However, their performance is commonly evaluated using an interpolated setup with highly correlated training and test views. In contrast, extrapolation, where test views largely deviate from training views, remains underexplored, limiting progress in generalizable simulation technology. To address this gap, we leverage publicly available AV datasets with multiple traversals, multiple vehicles, and multiple cameras to build the first Extrapolated Urban View Synthesis (EUVS) benchmark. Meanwhile, we conduct quantitative and qualitative evaluations of state-of-the-art Gaussian Splatting methods across different difficulty levels. Our results show that Gaussian Splatting is prone to overfitting to training views. Besides, incorporating diffusion priors and improving geometry cannot fundamentally improve NVS under large view changes, highlighting the need for more robust approaches and large-scale training. We have released our data to help advance self-driving and urban robotics simulation technology.
Marconi: Prefix Caching for the Era of Hybrid LLMs
Nov 28, 2024



Hybrid models that combine the language modeling capabilities of Attention layers with the efficiency of Recurrent layers (e.g., State Space Models) have gained traction in practically supporting long contexts in Large Language Model serving. Yet, the unique properties of these models complicate the usage of complementary efficiency optimizations such as prefix caching that skip redundant computations across requests. Most notably, their use of in-place state updates for recurrent layers precludes rolling back cache entries for partial sequence overlaps, and instead mandates only exact-match cache hits; the effect is a deluge of (large) cache entries per sequence, most of which yield minimal reuse opportunities. We present Marconi, the first system that supports efficient prefix caching with Hybrid LLMs. Key to Marconi are its novel admission and eviction policies that more judiciously assess potential cache entries based not only on recency, but also on (1) forecasts of their reuse likelihood across a taxonomy of different hit scenarios, and (2) the compute savings that hits deliver relative to memory footprints. Across diverse workloads and Hybrid models, Marconi achieves up to 34.4$\times$ higher token hit rates (71.1% or 617 ms lower TTFT) compared to state-of-the-art prefix caching systems.
Uncertainty-aware self-training with expectation maximization basis transformation
May 02, 2024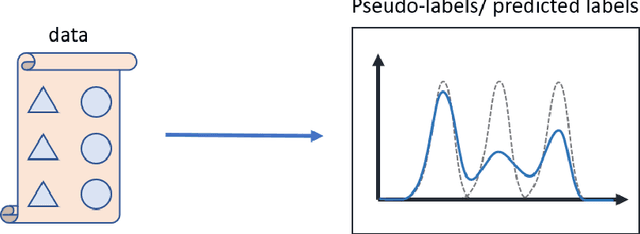



Self-training is a powerful approach to deep learning. The key process is to find a pseudo-label for modeling. However, previous self-training algorithms suffer from the over-confidence issue brought by the hard labels, even some confidence-related regularizers cannot comprehensively catch the uncertainty. Therefore, we propose a new self-training framework to combine uncertainty information of both model and dataset. Specifically, we propose to use Expectation-Maximization (EM) to smooth the labels and comprehensively estimate the uncertainty information. We further design a basis extraction network to estimate the initial basis from the dataset. The obtained basis with uncertainty can be filtered based on uncertainty information. It can then be transformed into the real hard label to iteratively update the model and basis in the retraining process. Experiments on image classification and semantic segmentation show the advantages of our methods among confidence-aware self-training algorithms with 1-3 percentage improvement on different datasets.
Potential Energy based Mixture Model for Noisy Label Learning
May 02, 2024



Training deep neural networks (DNNs) from noisy labels is an important and challenging task. However, most existing approaches focus on the corrupted labels and ignore the importance of inherent data structure. To bridge the gap between noisy labels and data, inspired by the concept of potential energy in physics, we propose a novel Potential Energy based Mixture Model (PEMM) for noise-labels learning. We innovate a distance-based classifier with the potential energy regularization on its class centers. Embedding our proposed classifier with existing deep learning backbones, we can have robust networks with better feature representations. They can preserve intrinsic structures from the data, resulting in a superior noisy tolerance. We conducted extensive experiments to analyze the efficiency of our proposed model on several real-world datasets. Quantitative results show that it can achieve state-of-the-art performance.
Lancet: Accelerating Mixture-of-Experts Training via Whole Graph Computation-Communication Overlapping
Apr 30, 2024



The Mixture-of-Expert (MoE) technique plays a crucial role in expanding the size of DNN model parameters. However, it faces the challenge of extended all-to-all communication latency during the training process. Existing methods attempt to mitigate this issue by overlapping all-to-all with expert computation. Yet, these methods frequently fall short of achieving sufficient overlap, consequently restricting the potential for performance enhancements. In our study, we extend the scope of this challenge by considering overlap at the broader training graph level. During the forward pass, we enable non-MoE computations to overlap with all-to-all through careful partitioning and pipelining. In the backward pass, we achieve overlap with all-to-all by scheduling gradient weight computations. We implement these techniques in Lancet, a system using compiler-based optimization to automatically enhance MoE model training. Our extensive evaluation reveals that Lancet significantly reduces the time devoted to non-overlapping communication, by as much as 77%. Moreover, it achieves a notable end-to-end speedup of up to 1.3 times when compared to the state-of-the-art solutions.
Faithful Temporal Question Answering over Heterogeneous Sources
Feb 23, 2024Temporal question answering (QA) involves time constraints, with phrases such as "... in 2019" or "... before COVID". In the former, time is an explicit condition, in the latter it is implicit. State-of-the-art methods have limitations along three dimensions. First, with neural inference, time constraints are merely soft-matched, giving room to invalid or inexplicable answers. Second, questions with implicit time are poorly supported. Third, answers come from a single source: either a knowledge base (KB) or a text corpus. We propose a temporal QA system that addresses these shortcomings. First, it enforces temporal constraints for faithful answering with tangible evidence. Second, it properly handles implicit questions. Third, it operates over heterogeneous sources, covering KB, text and web tables in a unified manner. The method has three stages: (i) understanding the question and its temporal conditions, (ii) retrieving evidence from all sources, and (iii) faithfully answering the question. As implicit questions are sparse in prior benchmarks, we introduce a principled method for generating diverse questions. Experiments show superior performance over a suite of baselines.
DynaPipe: Optimizing Multi-task Training through Dynamic Pipelines
Nov 17, 2023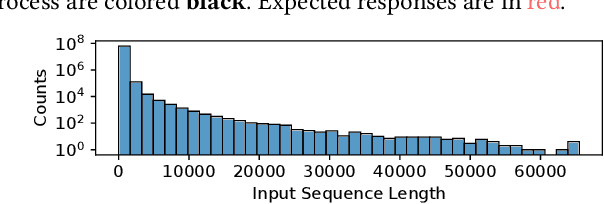
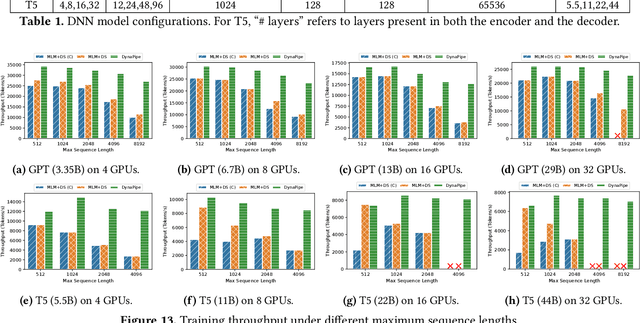
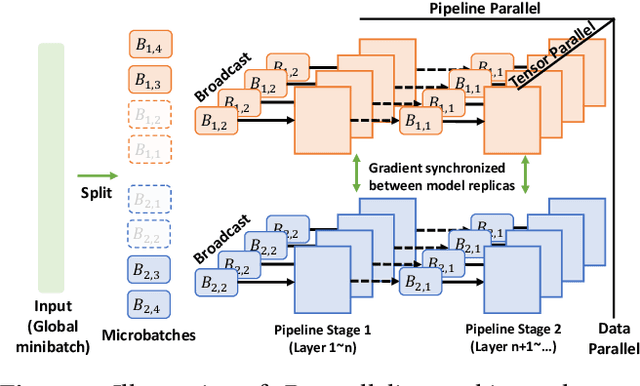
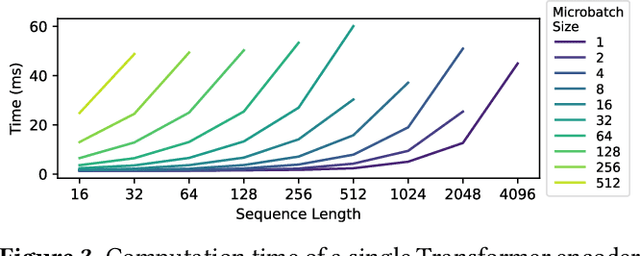
Multi-task model training has been adopted to enable a single deep neural network model (often a large language model) to handle multiple tasks (e.g., question answering and text summarization). Multi-task training commonly receives input sequences of highly different lengths due to the diverse contexts of different tasks. Padding (to the same sequence length) or packing (short examples into long sequences of the same length) is usually adopted to prepare input samples for model training, which is nonetheless not space or computation efficient. This paper proposes a dynamic micro-batching approach to tackle sequence length variation and enable efficient multi-task model training. We advocate pipeline-parallel training of the large model with variable-length micro-batches, each of which potentially comprises a different number of samples. We optimize micro-batch construction using a dynamic programming-based approach, and handle micro-batch execution time variation through dynamic pipeline and communication scheduling, enabling highly efficient pipeline training. Extensive evaluation on the FLANv2 dataset demonstrates up to 4.39x higher training throughput when training T5, and 3.25x when training GPT, as compared with packing-based baselines. DynaPipe's source code is publicly available at https://github.com/awslabs/optimizing-multitask-training-through-dynamic-pipelines.
Multi-Semantic Fusion Model for Generalized Zero-Shot Skeleton-Based Action Recognition
Sep 18, 2023Generalized zero-shot skeleton-based action recognition (GZSSAR) is a new challenging problem in computer vision community, which requires models to recognize actions without any training samples. Previous studies only utilize the action labels of verb phrases as the semantic prototypes for learning the mapping from skeleton-based actions to a shared semantic space. However, the limited semantic information of action labels restricts the generalization ability of skeleton features for recognizing unseen actions. In order to solve this dilemma, we propose a multi-semantic fusion (MSF) model for improving the performance of GZSSAR, where two kinds of class-level textual descriptions (i.e., action descriptions and motion descriptions), are collected as auxiliary semantic information to enhance the learning efficacy of generalizable skeleton features. Specially, a pre-trained language encoder takes the action descriptions, motion descriptions and original class labels as inputs to obtain rich semantic features for each action class, while a skeleton encoder is implemented to extract skeleton features. Then, a variational autoencoder (VAE) based generative module is performed to learn a cross-modal alignment between skeleton and semantic features. Finally, a classification module is built to recognize the action categories of input samples, where a seen-unseen classification gate is adopted to predict whether the sample comes from seen action classes or not in GZSSAR. The superior performance in comparisons with previous models validates the effectiveness of the proposed MSF model on GZSSAR.