 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Resolution Attention Network for High-Resolution PM2.5 Prediction
Mar 12, 2026Vision Transformers have achieved remarkable success in spatio-temporal prediction, but their scalability remains limited for ultra-high-resolution, continent-scale domains required in real-world environmental monitoring. A single European air-quality map at 1 km resolution comprises 29 million pixels, far beyond the limits of naive self-attention. We introduce CRAN-PM, a dual-branch Vision Transformer that leverages cross-resolution attention to efficiently fuse global meteorological data (25 km) with local high-resolution PM2.5 at the current time (1 km). Instead of including physically driven factors like temperature and topography as input, we further introduce elevation-aware self-attention and wind-guided cross-attention to force the network to learn physically consistent feature representations for PM2.5 forecasting. CRAN-PM is fully trainable and memory-efficient, generating the complete 29-million-pixel European map in 1.8 seconds on a single GPU. Evaluated on daily PM2.5 forecasting throughout Europe in 2022 (362 days, 2,971 European Environment Agency (EEA) stations), it reduces RMSE by 4.7% at T+1 and 10.7% at T+3 compared to the best single-scale baseline, while reducing bias in complex terrain by 36%.
Inverse Neural Operator for ODE Parameter Optimization
Mar 12, 2026We propose the Inverse Neural Operator (INO), a two-stage framework for recovering hidden ODE parameters from sparse, partial observations. In Stage 1, a Conditional Fourier Neural Operator (C-FNO) with cross-attention learns a differentiable surrogate that reconstructs full ODE trajectories from arbitrary sparse inputs, suppressing high-frequency artifacts via spectral regularization. In Stage 2, an Amortized Drifting Model (ADM) learns a kernel-weighted velocity field in parameter space, transporting random parameter initializations toward the ground truth without backpropagating through the surrogate, avoiding the Jacobian instabilities that afflict gradient-based inversion in stiff regimes. Experiments on a real-world stiff atmospheric chemistry benchmark (POLLU, 25 parameters) and a synthetic Gene Regulatory Network (GRN, 40 parameters) show that INO outperforms gradient-based and amortized baselines in parameter recovery accuracy while requiring only 0.23s inference time, a 487x speedup over iterative gradient descent.
MCMC Informed Neural Emulators for Uncertainty Quantification in Dynamical Systems
Mar 11, 2026Neural networks are a commonly used approach to replace physical models with computationally cheap surrogates. Parametric uncertainty quantification can be included in training, assuming that an accurate prior distribution of the model parameters is available. Here we study the common opposite situation, where direct screening or random sampling of model parameters leads to exhaustive training times and evaluations at unphysical parameter values. Our solution is to decouple uncertainty quantification from network architecture. Instead of sampling network weights, we introduce the model-parameter distribution as an input to network training via Markov chain Monte Carlo (MCMC). In this way, the surrogate achieves the same uncertainty quantification as the underlying physical model, but with substantially reduced computation time. The approach is fully agnostic with respect to the neural network choice. In our examples, we present a quantile emulator for prediction and a novel autoencoder-based ODE network emulator that can flexibly estimate different trajectory paths corresponding to different ODE model parameters. Moreover, we present a mathematical analysis that provides a transparent way to relate potential performance loss to measurable distribution mismatch.
TopoFlow: Physics-guided Neural Networks for high-resolution air quality prediction
Feb 18, 2026We propose TopoFlow (Topography-aware pollutant Flow learning), a physics-guided neural network for efficient, high-resolution air quality prediction. To explicitly embed physical processes into the learning framework, we identify two critical factors governing pollutant dynamics: topography and wind direction. Complex terrain can channel, block, and trap pollutants, while wind acts as a primary driver of their transport and dispersion. Building on these insights, TopoFlow leverages a vision transformer architecture with two novel mechanisms: topography-aware attention, which explicitly models terrain-induced flow patterns, and wind-guided patch reordering, which aligns spatial representations with prevailing wind directions. Trained on six years of high-resolution reanalysis data assimilating observations from over 1,400 surface monitoring stations across China, TopoFlow achieves a PM2.5 RMSE of 9.71 ug/m3, representing a 71-80% improvement over operational forecasting systems and a 13% improvement over state-of-the-art AI baselines. Forecast errors remain well below China's 24-hour air quality threshold of 75 ug/m3 (GB 3095-2012), enabling reliable discrimination between clean and polluted conditions. These performance gains are consistent across all four major pollutants and forecast lead times from 12 to 96 hours, demonstrating that principled integration of physical knowledge into neural networks can fundamentally advance air quality prediction.
PUFM++: Point Cloud Upsampling via Enhanced Flow Matching
Dec 24, 2025Recent advances in generative modeling have demonstrated strong promise for high-quality point cloud upsampling. In this work, we present PUFM++, an enhanced flow-matching framework for reconstructing dense and accurate point clouds from sparse, noisy, and partial observations. PUFM++ improves flow matching along three key axes: (i) geometric fidelity, (ii) robustness to imperfect input, and (iii) consistency with downstream surface-based tasks. We introduce a two-stage flow-matching strategy that first learns a direct, straight-path flow from sparse inputs to dense targets, and then refines it using noise-perturbed samples to approximate the terminal marginal distribution better. To accelerate and stabilize inference, we propose a data-driven adaptive time scheduler that improves sampling efficiency based on interpolation behavior. We further impose on-manifold constraints during sampling to ensure that generated points remain aligned with the underlying surface. Finally, we incorporate a recurrent interface network~(RIN) to strengthen hierarchical feature interactions and boost reconstruction quality. Extensive experiments on synthetic benchmarks and real-world scans show that PUFM++ sets a new state of the art in point cloud upsampling, delivering superior visual fidelity and quantitative accuracy across a wide range of tasks. Code and pretrained models are publicly available at https://github.com/Holmes-Alan/Enhanced_PUFM.
SPIN-ODE: Stiff Physics-Informed Neural ODE for Chemical Reaction Rate Estimation
May 08, 2025Estimating rate constants from complex chemical reactions is essential for advancing detailed chemistry. However, the stiffness inherent in real-world atmospheric chemistry systems poses severe challenges, leading to training instability and poor convergence that hinder effective rate constant estimation using learning-based approaches. To address this, we propose a Stiff Physics-Informed Neural ODE framework (SPIN-ODE) for chemical reaction modelling. Our method introduces a three-stage optimisation process: first, a latent neural ODE learns the continuous and differentiable trajectory between chemical concentrations and their time derivatives; second, an explicit Chemical Reaction Neural Network (CRNN) extracts the underlying rate coefficients based on the learned dynamics; and third, fine-tune CRNN using a neural ODE solver to further improve rate coefficient estimation. Extensive experiments on both synthetic and newly proposed real-world datasets validate the effectiveness and robustness of our approach. As the first work on stiff Neural ODEs for chemical rate coefficient discovery, our study opens promising directions for integrating neural networks with detailed chemistry.
Data-Efficient Limited-Angle CT Using Deep Priors and Regularization
Feb 19, 2025Reconstructing an image from its Radon transform is a fundamental computed tomography (CT) task arising in applications such as X-ray scans. In many practical scenarios, a full 180-degree scan is not feasible, or there is a desire to reduce radiation exposure. In these limited-angle settings, the problem becomes ill-posed, and methods designed for full-view data often leave significant artifacts. We propose a very low-data approach to reconstruct the original image from its Radon transform under severe angle limitations. Because the inverse problem is ill-posed, we combine multiple regularization methods, including Total Variation, a sinogram filter, Deep Image Prior, and a patch-level autoencoder. We use a differentiable implementation of the Radon transform, which allows us to use gradient-based techniques to solve the inverse problem. Our method is evaluated on a dataset from the Helsinki Tomography Challenge 2022, where the goal is to reconstruct a binary disk from its limited-angle sinogram. We only use a total of 12 data points--eight for learning a prior and four for hyperparameter selection--and achieve results comparable to the best synthetic data-driven approaches.
Deep Spatio-Temporal Neural Network for Air Quality Reanalysis
Feb 17, 2025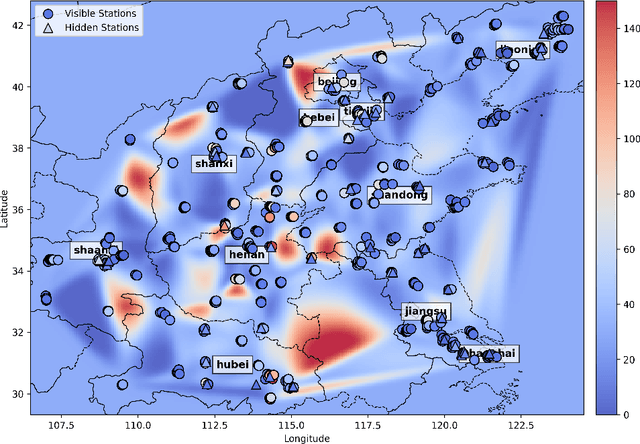
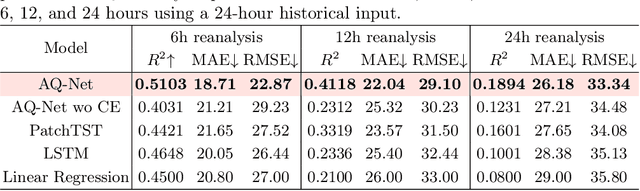
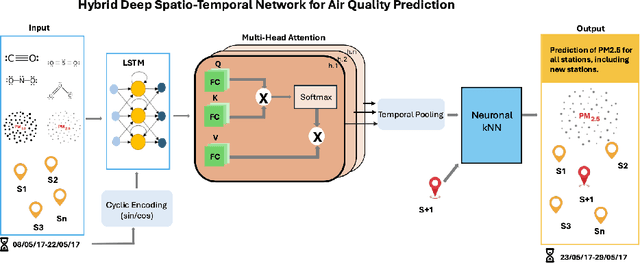

Air quality prediction is key to mitigating health impacts and guiding decisions, yet existing models tend to focus on temporal trends while overlooking spatial generalization. We propose AQ-Net, a spatiotemporal reanalysis model for both observed and unobserved stations in the near future. AQ-Net utilizes the LSTM and multi-head attention for the temporal regression. We also propose a cyclic encoding technique to ensure continuous time representation. To learn fine-grained spatial air quality estimation, we incorporate AQ-Net with the neural kNN to explore feature-based interpolation, such that we can fill the spatial gaps given coarse observation stations. To demonstrate the efficiency of our model for spatiotemporal reanalysis, we use data from 2013-2017 collected in northern China for PM2.5 analysis. Extensive experiments show that AQ-Net excels in air quality reanalysis, highlighting the potential of hybrid spatio-temporal models to better capture environmental dynamics, especially in urban areas where both spatial and temporal variability are critical.
Efficient Point Clouds Upsampling via Flow Matching
Jan 25, 2025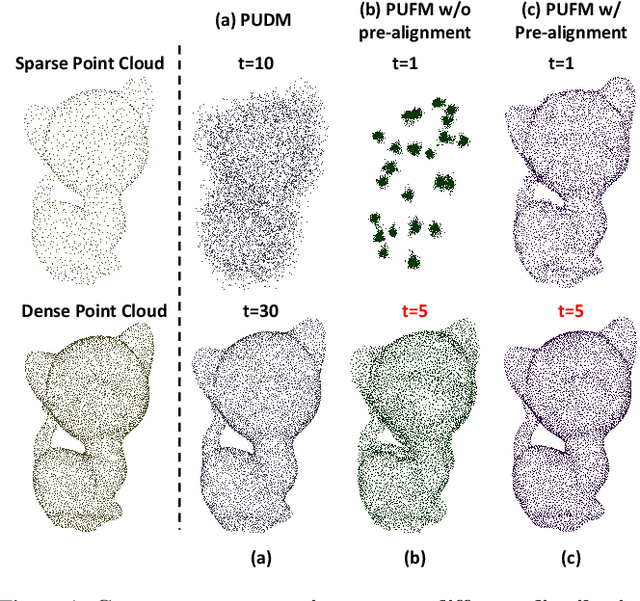
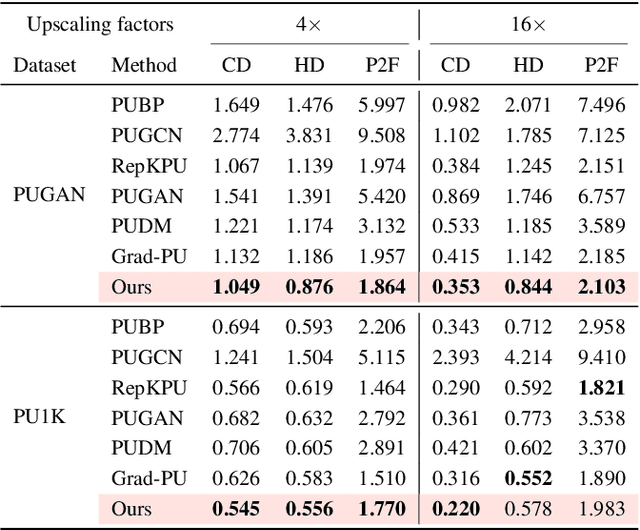
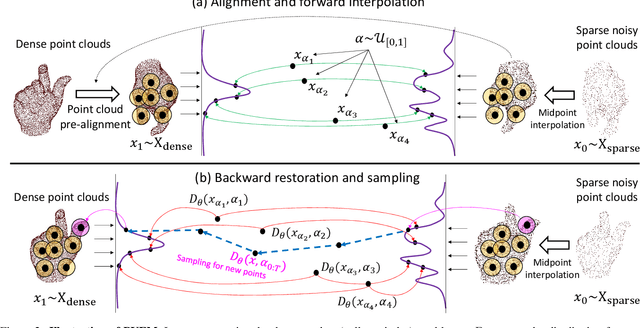
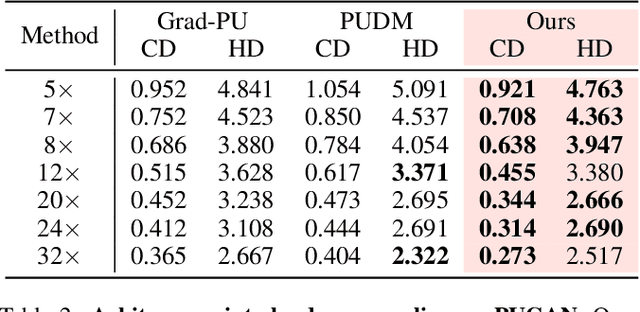
Diffusion models are a powerful framework for tackling ill-posed problems, with recent advancements extending their use to point cloud upsampling. Despite their potential, existing diffusion models struggle with inefficiencies as they map Gaussian noise to real point clouds, overlooking the geometric information inherent in sparse point clouds. To address these inefficiencies, we propose PUFM, a flow matching approach to directly map sparse point clouds to their high-fidelity dense counterparts. Our method first employs midpoint interpolation to sparse point clouds, resolving the density mismatch between sparse and dense point clouds. Since point clouds are unordered representations, we introduce a pre-alignment method based on Earth Mover's Distance (EMD) optimization to ensure coherent interpolation between sparse and dense point clouds, which enables a more stable learning path in flow matching. Experiments on synthetic datasets demonstrate that our method delivers superior upsampling quality but with fewer sampling steps. Further experiments on ScanNet and KITTI also show that our approach generalizes well on RGB-D point clouds and LiDAR point clouds, making it more practical for real-world applications.
Bridging Text and Image for Artist Style Transfer via Contrastive Learning
Oct 12, 2024



Image style transfer has attracted widespread attention in the past few years. Despite its remarkable results, it requires additional style images available as references, making it less flexible and inconvenient. Using text is the most natural way to describe the style. More importantly, text can describe implicit abstract styles, like styles of specific artists or art movements. In this paper, we propose a Contrastive Learning for Artistic Style Transfer (CLAST) that leverages advanced image-text encoders to control arbitrary style transfer. We introduce a supervised contrastive training strategy to effectively extract style descriptions from the image-text model (i.e., CLIP), which aligns stylization with the text description. To this end, we also propose a novel and efficient adaLN based state space models that explore style-content fusion. Finally, we achieve a text-driven image style transfer. Extensive experiments demonstrate that our approach outperforms the state-of-the-art methods in artistic style transfer. More importantly, it does not require online fine-tuning and can render a 512x512 image in 0.03s.